|
|
|
发布时间: 2021-02-25 |
计算机与信息科学 |
|
|
|


|
收稿日期: 2020-02-28
中图法分类号: TP183;TP389.1
文献标识码: A
文章编号: 2096-8299(2021)01-0073-05
|
摘要
由于自然场景中的图像背景复杂、文字排列不规则、光照条件不确定等因素,文字检测难度较大,且传统检测方法的效果并不理想。在研究文字分割检测方法PSENet(Progressive Scale Expansion Network)的基础上,提出了一种针对自然场景文字检测的改进方法。该方法由卷积神经网络提取特征模块,再通过渐进式规模扩张对文字区域进行分割检测。改进点主要是使用高精度的语义分割网络RefineNet(Refinement Network),对卷积网络特征提取模块进行优化,且增加较多的残差连接及链式池化,提高网络对文字区域的检测精度。通过对数据集ICDAR2015的实验结果对比,表明所提出的改进算法在精度方面略高于改进前,且能更好地解决文字粘连问题。
关键词
文字检测; 图像分割; 特征融合
Abstract
Due to the problematic scene background, irregular arrangement of text, and uncertain lighting conditions in natural scenes, text detection is difficult, and the traditional detection method is not ideal.In the study of the text segmentation detection method Progressive Scale Expansion Network (PSENet), an improved method for text detection in a natural scene is proposed.The improved model mainly uses the convolutional neural network to extract feature modules and performs segmentation detection on the text area through progressive scale expansion.The improvement points mainly uses a high-precision semantic segmentation network(RefineNet), optimizing the volume and network feature extraction modules, adding more residual connections and chain pooling, and improving the network's detection accuracy of the text area.Comparing the experimental results on the data set (ICDAR2015), the proposed improved algorithm is slightly more accurate than the previous algorithm and can better solve the problem of text conglutination.
Key words
text detection; image segmentation; feature fusion
文字作为人类交流思想、传承文化的重要媒介, 从古至今一直发挥着重要的作用。利用文字所包含的高级语义, 可以更有效地利用场景信息, 提高文字检测的精度。
现有的文字检测方式主要分为3类: 传统区域建议方法、基于目标检测方法以及基于图像分割检测方法[1]。传统区域建议方法包括滑动窗口方法和连通域方法, 在环境背景复杂和噪声污染的情况下, 效果较差。因此, 相关学者将深度学习引入文字检测领域, 利用大量的数据进行学习训练, 并通过不断迭代和调整权重, 提取更多有用的特征[2]。基于目标检测方法的主要思路是将文字区域作为一项特殊的目标检测, 一般先在图像上提取多个候选区域, 然后再通过分类器对候选区域进行分类筛选, 最后再对其进行精修。通常在提取多个候选区域时较为耗时。基于目标检测的方法, 在Faster R-CNN[3-4]后, SSD[5]和YOLO[6]等网络结构被相继提出。基于图像分割检测方法通常利用卷积神经网络提取图像中的特征, 再对图像进行像素级的文字/背景的标注, 能较好地检测倾斜文字及不规则文字, 且避免受文字区域框长宽比变化的影响。ZHANG Z等人[7]将文字区域作为一个特殊的分割目标, 首次提出利用全卷积网络从像素层面对图像进行处理, 而后PixelLink[8], Inceptext[9], PSENet(Progressive Scale Expansion Network)[10]等基于实例分割的网络结构被相继提出。
为了进一步优化文字检测领域的算法和网络, 本文主要在学习PSENet网络的基础上, 进一步优化评判指标, 将改进后的PSENet对自然场景中的文字进行检测, 通过标准文字数据集的实现对比进行结果分析, 证明此算法的可行性。
1 原始特征提取网络
在文字的特征提取过程中, 低层网络往往带有较多对文字检测有用的边角位置信息, 而高层网络经过了多层的卷积层后富含丰富的语义信息[11]。
FPN(Feature Pyramid Networks)融合算法由LIN T Y等人[12]提出后, 得到了广泛应用, 主要解决物体检测中的多尺度问题, 通过对简单网络的连接改变, 在小幅增加原有模型计算量的情况下, 大幅度提升了对小物体的特征检测能力。其网络结构如图 1所示。
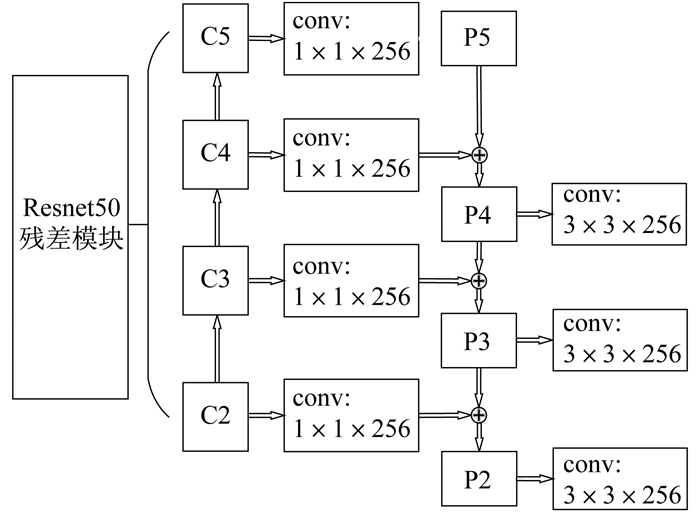

FPN网络主要分为3个部分: 自底向上的路径、自顶向下的路径以及中间的连接部分。第1部分网络选用Resnet50中每个阶段的最后一个残差网络输出的特征, 并将其表示为C2, C3, C4, C5;第2部分通过对包含最丰富语义信息的特征层进行上采样来获得更加具有高分辨率的特征, 再通过侧向连接自底向上的结构, 使每个特征层的空间位置信息得到加强, 加强融合特征表示为P2, P3, P4, P5;第3部分为减少上采样的混叠响应, 对每层输出特征附加一个3×3卷积来生成最后的特征映射。
LI X等人[10]在PSENet网络中使用的特征提取网络为FPN融合算法。
2 改进的特征提取网络
本文对原始的特征融合网络进行改进, 利用在语义分割领域中效果较好的RefineNet[13]融合算法提高对图片中特征的提取精度, 以此提高后续操作对文字区域的分割和定位。RefineNet网络结构如图 2所示。
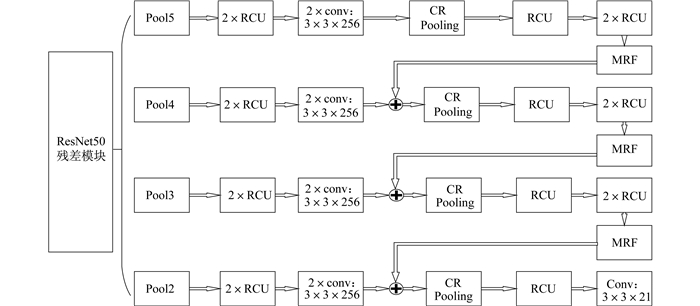
RefineNet网络的一个特点是其使用了较多残差连接, 从而使网络内部形成了短程连接的同时, 还与ResNet残差模块中的特征层形成了远程连接, 不仅提高了训练能力, 还让梯度能够有效地进行短距离和长距离的残差网络传播, 实现有效的端到端训练。
RefineNet网络选用ResNet50中的2~5层网络特征图作为输入层, Pool5作为第1层输入, 目的是为了调整预训练网络Resnet50中的第5层特征图的权重, 而后将Pool5经过一次RefineNet网络后的输出与Pool4的输入相加后, 再经过一次RefineNet融合, 目的是为了使用具有高分辨的特征改善上一次输入的低分辨率特征, 同样地, 将剩余的Pool3和Pool2进行相同的操作。这样通过RefineNet的层层融合后, 得到精调特征图。
RefineNet网络主要分为3个部分: RCU(Residual Conv Unit), CR Pooling(Chained Residual Pooling), MRF(Multi-resolution Fusion)。RCU中包含两次激活函数及两次3×3卷积操作, 主要目的是为了修整经过预训练的ResNet的权重, 每一个输入层都将连续经过2次RCU。在MRF操作过程中, 每个输入层经过3×3卷积层以及上采样操作后进行加和融合。CR Pooling模块包含残差结构、池化层和卷积层, 主要目的是为了针对较大的图像区域提取上下文的背景信息。最后, 再经过一个RCU模块, 以平衡所有的权重, 从而得到与输入分辨率一致的分割结果。
3 实验与结果分析
3.1 实验环境
实验设备为配置TITANXPascal的Ubuntu16.04系统, 内存12 G, 训练与测试软件平台选用TensorFlow。为了验证本文所提改进算法的有效性, 采用公共数据集ICDAR2015。该数据集是ICDAR鲁棒性阅读比赛的官方数据集, 包含1 000张训练图片及500张测试图片, 图片主要侧重于自然场景中的倾斜文字, 在场景文字区域检测领域中较为流行, 因此本文测试结果具有较强的参考意义。
3.2 评价指标
在机器学习中, 通常会有该领域相对应的评价指标来评判一个模型的好坏, 在文字检测领域中, 通常使用准确率、召回率和F_score作为评价指标[14]。
准确率是针对于预测结果而言的, 表示预测为正的样本中有多少是真正的正样本。其定义为
| $ {P = \frac{{{p_{\rm{T}}}}}{{{p_{\rm{T}}} + {p_{\rm{F}}}}}} $ | (1) |
式中: pT——正确判断的正像素;
pF——错误判断的正像素。
召回率是指可以与预测框匹配的真值框占所有真值框的比例, 是针对于原来的样本而言的, 表示样本中的正例有多少被正确预测了。其定义为
| $ {R = \frac{{{p_{\rm{T}}}}}{{{p_{\rm{T}}} + {n_{\rm{F}}}}}} $ | (2) |
式中: nF——错误判断的负像素。
F-score是两者的综合评判, 该指标越高, 则网络模型越稳定。其定义为
| $ {F = \frac{{2PR}}{{P + R}}} $ | (3) |
3.3 实验结果分析
在相同的实验环境和实验平台下, 在同一种数据集上进行训练和测试。均仅采用ResNet50残差网络作为预训练模型, 训练相同数量迭代次数, 对ICDAR2015数据集中的1 000张图片进行训练, 通过控制其他变量, 仅改进特征融合部分。具体实验数据如表 1所示。
表 1
PSENet网络改进前后实验数据对比
| 算法 | 准确率 | 召回率 | F-score |
| FPN | 63 | 67 | 64 |
| RefineNet | 68 | 71 | 69 |
实验结果表明, 本文使用RefineNet融合算法相较于原PSENet网络中的FPN融合算法, 评价指标均有所提升。本文改进的模型, 在准确率和召回率上提升7%和5%, 综合指标F-score提升7%。
通过生成测试图片的预测效果图, 可以进一步对比两种算法得到的实验结果, 更加直观地看出改进后算法的有效性。具体如图 3和图 4所示。图 3的中央与右侧区域, 使用RefineNet融合算法得到的文字区域更为准确, 能将较小区域中的单词分别识别, 检测准确度较高。图 4中, 第2行文字末端由于文字区域较倾斜, 单词间隙较小, 产生粘连情况, 使用RefineNet融合算法得到的文字区域能更好地解决文字粘连问题。


改进前使用FPN融合算法虽然也能较为准确地标记出图片中的文字区域, 但使用RefineNet融合算法对PSENet网络进行改进, 优化特征提取网络, 可以使自然场景下较小的文字区域得到正确识别, 因此本文提出的算法有效可行。
4 结语
针对自然场景下的文字区域检测问题, 本文提出改进PSENet网络的RefineNet融合算法, 将自然场景下拍摄的图片作为输入, 通过对原PSENet网络中特征提取部分FPN融合算法进行改进, 优化对文字区域的检测能力。实验结果证明, 本文提出的算法有效可行。
但该算法仍有改进空间, 后续将通过进一步优化损失函数, 以及对文字区域进行尺度分类等方式, 提高PSENet网络对文字区域的检测能力。
参考文献
-
[1]余若男, 黄定江, 董启文. 基于深度学习的场景文字检测研究进展[J]. 华东师范大学学报(自然科学版), 2018(5): 1-16.
-
[2]刘战东. 基于深度学习的场景文字检测[D]. 合肥: 中国科学技术大学, 2019.
-
[3]杨宏志, 庞宇, 王慧倩. 基于改进Faster R-CNN的自然场景文字检测算法[J]. 重庆邮电大学学报(自然科学版), 2019, 31(6): 876-884.
-
[4]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intellgence, 2017(6): 1137-1149.
-
[5]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21-37.
-
[6]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 779-788.
-
[7]ZHANG Z, ZHANG C Q, SHEN W, et al. Multi-oriented text detection with fully convolutional networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 4159-4167.
-
[8]DENG D, LIU H F, LI X L, et al. PixelLink: detecting scene text via instance segmentation[EB/OL].(2018-01-04)[2020-02-02].https://arxiv.org/pdf/1801.01315.pdf.
-
[9]YANG Q P, CHENG M L, ZHOU W M, et al. Inceptext: a new inception-text module with deformable PSROI pooling for multi-oriented scene text detection[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence(IJCAI). Stockholm, Sweden, 2018: 1071-1077.
-
[10]LI X, WANG W H, HOU W B, et al. Shape robust text detection with progressive scale expansion network[EB/OL].(2018-06-07)[2020-02-02].https://arxiv.org/pdf/1806.02559.pdf.
-
[11]林泓, 卢瑶瑶. 聚焦难样本的区分尺度的文字检测方法[J]. 浙江大学学报(工学版), 2019, 53(8): 1506-1516.
-
[12]LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu, IH, USA: IEEE, 2017: 936-944.
-
[13]LIN G S, MILAN A, SHEN C H, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, IH, USA: IEEE, 2017: 1925-1934.
-
[14]余若男, 黄定江, 董启文. 基于深度学习的场景文字检测研究进展[J]. 华东师范大学学报(自然科学版), 2018(5): 1-16.


