|
|
|
发布时间: 2021-02-25 |
计算机与信息科学 |
|
|
|


|
收稿日期: 2020-02-28
中图法分类号: TP301.6
文献标识码: A
文章编号: 2096-8299(2021)01-0099-05
|
摘要
针对现实场景图片中的文字区域具有仿射变换和多方向的问题,设计了一种带有仿射变换锚点,能够生成仿射变换文本预测框的文本检测网络。按照常见文字实例的仿真变换形状,给定了6种固定角度和5个固定变换量。检测过程中对预测候选框的角度和偏移值进行了调整拟合,最后对边框进行了回归,让检测结果更适应真实文字区域的边界框。与以往的文字检测网络相比,该检测方法能够有效适应文字区域,在检测精度和平均指标上分别有了7%和10%的提升。
关键词
自然场景; 文字检测; 仿射变换; 锚点; 卷积网络
Abstract
Aiming at the problem of affine transformation and multi-direction in the text area in real scene pictures, a text detection network with affine transformation anchors is designed, which can generate affine transformation shape text prediction box.6 angles and 5 transformation amounts are given by the affine transformation amount of common text annotation.In the detection process, the angle and offset value of the predicted candidate box are adjusted and fitted, and finally the frame is regressed to make the detection result more suitable for the bounding box of the real text area.Compared with the previous text detection network, this detection method can effectively adapt to the text area, and the detection accuracy and average index have been improved by 7% and 10% respectively.
Key words
natural scene; text detection; affine transformation; anchor; convolutional network
文字检测是计算机视觉中的一个重要部分, 也是文字识别的必要过程。自然场景下的文字检测目前依然面临很大的挑战, 主要是因为自然场景图像中的文字在亮度、模糊、形状、方向等方面有很高的随机性, 导致文字检测的难度较大。
近年来, 研究者提出了很多的文字检测方法[1-5]。尽管这些方法提高了检测结果, 但大多还是基于水平的检测方式, 无法有效解决自然场景图像中文字复杂多变的情况。在实际应用中, 大部分图片中的文字区域都不是水平的, 通过以前的水平候选区方法来大量训练并不能得到很高的检测精度, 还会增加大量的计算时间。最近带有几何方向性的文字检测方法被提出[6-7]。该方法主要是通过自底向上的卷积神经网络(Convolutional Neural Network, CNN)[8-9]进行特征提取来生成文字预测特征图, 再通过计算有倾斜性质和特殊形状的锚点框与特征图上网格之间的置信度, 使用回归方法或者其他精细调整方法得到最终的检测结果。区域提议网络(Region Proposal Network, RPN)与Faster-RCNN[10]框架的结合, 进一步加快了锚点的提议进程。本文将角度信息和仿射变换信息加入多方向文本检测的模型中, 以期进一步优化适应文字区域的检测。
1 仿射变换锚点
1.1 水平锚点
RPN可以进一步加速区域提议的生成过程, 采用残差网络(Residual Network, ResNet)[11]的一部分作为共享网络层, 通过在最后一层卷积得到特征图上滑动窗口来生成水平区域提议。每个滑动窗口得到的特征提取后, 被送入回归层(regression)和分类层(classification)中; 回归层输出的每个提议框上有4个参数(宽、高、中心位置x坐标和y坐标), 另外每个滑动位置的锚点还有2个分数从分类层输出。
RPN使用尺度和宽高比两个参数控制锚点的大小和形状, 以便更好地适应不同尺寸的文字。尺度决定锚点的大小, 宽高比决定锚点的形状比例。在文字检测中, 尤其是自然场景下的图像, 文本通常都以非常规形状表现, 如果只使用RPN产生的水平锚点, 对于场景文字检测来说鲁棒性较差。为了提高网络检测的鲁棒性和准确率, 有必要建立一个适应文本形状的检测框架。
1.2 网络结构
本文所提网络的整体框架使用ResNet-101的卷积层进行特征提取, 增加仿射变换参数的RPN对最后一层卷积的特征图进行区域提议。图 1为仿射变换区域提议网络结构。
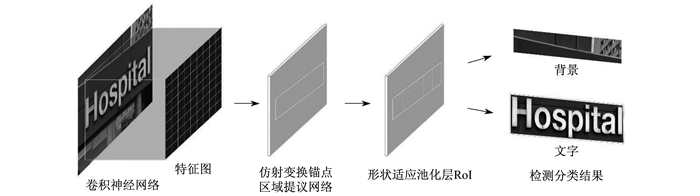

首先, 从场景图像上的预测文本实例中生成适应方向和变换的提议, 然后对提议进一步回归边界框来适应真实文本区域。由回归层和分类层输出的回归提议信息和分类分数计算回归和分类损失, 最终汇总为多任务损失。兴趣区域(Region-of-Interest, RoI)池化层将带有仿射变换的提议映射到特征图上。最后, 通过两个全连接层组成的分类网络将RoI特征区域分为前景文字区域和背景。
1.3 训练集处理
训练时, 图像上文本实例的位置形状坐标由标注真值框4个角的坐标(x1, y1, x2, y2, x3, y3, x4, y4)获得, 输入网络时通过计算转换为6个参数(x, y, h, w, θ, trans_x)。坐标(x, y)表示文本边界框的几何中心坐标; 高度(h)为边界框的短边长度; 宽度(w)为边界框的长边长度; 角度(θ)为边界框长边与坐标轴x之间的夹角; 变换值(trans_x)为长边方向的仿射变换偏移量。文本框的中心坐标、长宽和角度由文本边界框真值坐标求出的最小外接矩形得到, 仿射变换值由最小外接矩形与边界框真值的x坐标差值得到。
1.4 仿射变换锚点
传统的水平锚点不能进行很好的文字检测, 因此本文设计了具有仿射变换的旋转锚点, 并且进行了相应的调整和改进。
图 2所示的是仿射变换锚点位置形状参数的固定值。其中有6个方向的参数, 分别是:
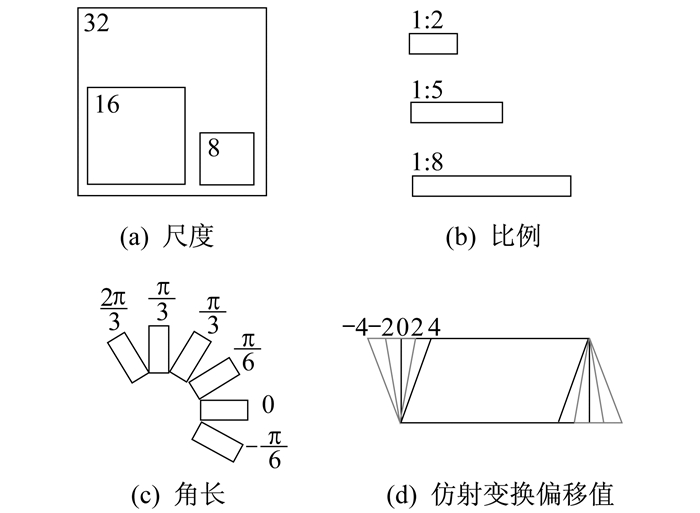
训练数据经过预处理步骤后, 一个提议锚点中有6个参数(x, y, h, w, θ, trans_x)。对于特征图上的每个点, 生成3×3×6×5共270个锚点。在每个滑动窗口经过的位置上分别生成6×270共1 620个输出, 分类层生成2×270共540个输出。根据仿射变换锚点网络在宽度为W、高度为H的特征图上滑动, 总共生成H×W×270个锚点。训练数据所给的坐标真值数量较少, 如果直接选择为训练结果, 容易产生过拟合现象。由于RPN中锚点数量多、形状变化大, 因此将锚点作为RPN的候选框进行正负样本分类时, 网络会学习这些具有仿射变换属性的锚点。通过计算文本坐标真值框与仿射变换锚点的面积交并比(Intersection-over-Union, IoU)来判断检测效果的好坏。正样本定义为: 最高的交并比或交并比大于0.7, 锚点的方向角度与文本坐标真值的旋转角度小于π/12[12], 并且仿射变换的变换值小于2。负样本定义为: 交并比小于0.3, 交并比大于0.7, 但旋转角度超过π/12。其余为不参与训练的多余样本。
1.5 损失函数
RPN在候选框生成完成后, 还需要使用Faster-RCNN的全连接层对这些候选框进行准确检测。检测过程分为回归网络和分类网络两个部分, 损失函数分为分类损失和回归损失: 分类损失是指候选框在前景背景分类时的误差; 回归损失是指候选框与标注真值框的几何参数的误差。
对于仿射变换锚点, 网络采用了多任务损失函数, 定义为
| $ {L\left( {p, l, {v^*}, v} \right) = {L_{{\rm{cls}}}}\left( {p, l} \right) + \lambda l{L_{{\rm{reg}}}}\left( {{v^*}, v} \right)} $ | (1) |
式中: p——softmax函数计算的类的概率, p=(p0, p1);
l——分类标签的指示符, l=1为文本, l=0为背景, 对于背景不进行回归;
v*——文本标注真值, v*=(vx*, vy*, vw*, vh*, vθ*, vtrans_x*);
v——文本标签预测出的参数组, v=(vx, vy, vw, vh, vθ, vtrans_x);
Lcls, Lreg——分类损失和回归损失;
λ——平衡控制参数。
分类损失与回归损失之间由λ权衡。其中将分类损失定义为
| $ {{L_{{\rm{cls}}}}\left( {p, l} \right) = - {\rm{log}}\;{p_l}} $ | (2) |
对于边界框回归, 背景RoI被忽略。文字RoI采用了smooth-L1损失函数, 即
| $ {{L_{{\rm{reg}}}}\left( {{v^*}, v} \right) = \sum\limits_{i \in \left\{ {x, y, h, w, \theta , {\rm{trans}}\_x} \right\}} {{\rm{smoot}}{{\rm{h}}_L}_1\left( {v_i^* - {v_i}} \right)} } $ | (3) |
| $ {\rm{smoot}}{{\rm{h}}_L}_1\left( x \right) = \left\{ \begin{array}{l} 0.5{x^2}\;\;\;\;\;\;\left| x \right| < 1\\ \left| x \right| - 0.5\;\;\;\;\;\;其他 \end{array} \right. $ | (4) |
候选框形状参数元组v和v*的计算方式为
| $ \begin{array}{l} {v_x} = \frac{{x - {x_{\rm{a}}}}}{{{w_{\rm{a}}}}}, {\rm{ }}{v_y} = \frac{{y - {y_{\rm{a}}}}}{{{h_{\rm{a}}}}}, \\ {v_h} = {\rm{log}}\frac{h}{{{h_{\rm{a}}}}}, {\rm{ }}{v_w} = {\rm{log}}\frac{w}{{{w_{\rm{a}}}}}, \\ {\rm{ }}\;\;\;\;\;{v_\theta } = \theta - {\theta _{\rm{a}}} + k{\rm{ \mathit{ π} }}, {\rm{ }}\\ \;\;{v_{{\rm{tran}}{{\rm{s}}_x}}} = {\rm{tran}}{{\rm{s}}_x} - {\rm{tran}}{{\rm{s}}_{x{\rm{a}}}} \end{array} $ | (5) |
| $ \begin{array}{l} v_x^* = \frac{{{x^*} - {x_{\rm{a}}}}}{{{w_{\rm{a}}}}}, {\rm{ }}v_y^* = \frac{{{y^*} - {y_{\rm{a}}}}}{{{h_{\rm{a}}}}}, {\rm{ }}\\ \;\;v_w^* = {\rm{log}}\frac{{{h^*}}}{{{h_{\rm{a}}}}}, {\rm{ }}v_h^* = {\rm{log}}\frac{{{w^*}}}{{{w_{\rm{a}}}}}, {\rm{ }}\\ \;\;\;\;\;\;\;{v_\theta }^* = {\theta ^*} - {\theta _{\rm{a}}} + k{\rm{ \mathit{ π} }}, {\rm{ }}\\ v_{{\rm{trans}}\_x}^* = {\rm{trans}}\_{x^*} - {\rm{trans}}\_{x_a} \end{array} $ | (6) |
式中: x, xa, x*——预测框、锚点和标注真值框;
vθ, vθ*——预测框和标注框的角度参数, 范围为
θ*——标注框的角度参数, 范围为
θa——锚点的角度参数, 范围为
w*, h*——标注框的宽和高;
wa, ha——锚点的宽和高;
k——任意整数。
仿射变换锚点的旋转角度定在仿射变换锚点的旋转角度定在$ \left[ {{\rm{ - }}\frac{{\rm{ \mathit{ π} }}}{{\rm{4}}}, \frac{{3{\rm{ \mathit{ π} }}}}{4}} \right)$范围内, 变换的偏移值定在[-4, 4]范围内, 给出固定的6个方向和6个偏移值中每一组都可以拟合到一个对于标注坐标真值相对较小差距的预测值。当标注坐标真值的形状与一个仿射变换锚点相拟合时, 这个仿射变换锚点最有可能是标注真值的正样本。范围内, 变换的偏移值定在[-4, 4]范围内, 给出固定的6个方向和6个偏移值中每一组都可以拟合到一个对于标注坐标真值相对较小差距的预测值。当标注坐标真值的形状与一个仿射变换锚点相拟合时, 这个仿射变换锚点最有可能是标注真值的正样本。
仿身变换区域提议网络可以提供大量不同形状的锚点, 针对任何仿射变换形状的文本实例都可以在合适范围内拟合形状。
1.6 优化计算
由于引入了仿射变换形状的锚点, 在计算IoU时相交面积不再是矩形, 因此可能会造成IoU计算不准确, 影响网络训练学习。针对新的锚点形状, 设计了一种求解任意形状四边形相交面积的IoU算法。输入锚点和标注框的6个坐标形状参数(x, y, h, w, θ, trans_x)转化为4个角的点坐标, 通过4个角的点坐标求出凸包形状, 即仿射变换锚点和标注框的形状, 通过这两个图形分别求出各自的面积和重叠面积, 最终可以得到两个仿射变换形状的IoU。
2 实验
本文在文字检测公共竞赛数据集ICDAR2015[13]和ICDAR2017MLT[14]上进行了实验。这两个数据集的图像和标注坐标都具有仿射变换形状, 可以训练和测试文字检测网络的几何文本检测能力。ICDAR2015是用于文本检测的常用数据集, 共包含1 500张图片, 其中1 000张用于训练, 其余用于测试。文本区域由四边形的4个顶点注释。ICDAR2017MLT是大规模的多语言文本数据集, 包括7 200个训练图像、1 800个验证图像和9 000个测试图像。数据集由来自9种语言的完整场景图像组成。与ICDAR2015类似, ICDAR2017MLT中的文本区域也由四边形的4个顶点注释。
实验使用一块TITAN X显卡, 显存为12 GB, CPU为Intel Core i5-2320 @3.00GHz×4, 内存为15.6 GB。实验中, 网络在前200 000次迭代中的学习率为10-3, 后100 000次迭代中的学习率为10-4, 权重衰减为5×10-4, 动量为0.9。
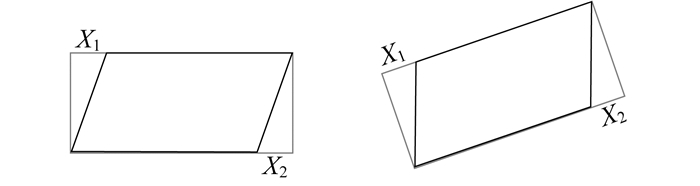
训练时, 锚点形状参数中的倾斜角度(θ)和仿射变换变换值(trans_x)由输入训练图片的标注坐标真值求出。在输入文本框水平时, 当左上点坐标的x坐标值大于文本框最小外接矩形左上点x坐标值, 则仿射变换偏移值取正; 当右下点坐标的x坐标值小于文本框最小外接矩形右下点x坐标值, 则仿射变换偏移值也取正, 如图 3所示。图 3中, X是指某一段的偏移量。训练时生成的仿射变换变换值(trans_x)就由左上点坐标的偏移值与右下点坐标的偏移值取平均值得到。
使用ICDAR2015的训练数据集进行训练, 该数据集包含1 000张图像和10 886个文本实例。检测的结果如下: 召回率为0.62;准确率为0.81;F1值为0.71。即使给定了270种形状的锚点, 但是一些训练的文本区域仍然太小, 导致召回率的提升不是很高。
与同类方法在标准数据集上进行了对比, 结果如表 1所示。
表 1
不同文字检测方法在ICDAR2015上的常用评价指标对比
由表 1可以看出, 由于本文方法带有仿射变换属性, 可以更好地检测到真实场景图片中的文字目标区域, 检测出的文字框形状与文字真实形状更加贴合。
图 4为检测过程模拟及检测结果。由图 4可知, 相比水平检测方法和带角度的矩形检测方法, 具有仿射变换形状的检测方法对于图片上的文字区域能够更好地框选出来, 不会像普通检测算法一样框选出很多不需要的背景区域, 从而提高了检测精准度。另外, 检测出来的文字框具有仿射变换参数, 可以轻松地将文字区域反求转换成矩形正面字体, 方便后续识别等操作。

3 结语
针对现实场景图片中的文字大部分具有仿射变换和多方向的形状, 以及传统水平锚点检测无法很好检测场景图片中文字的问题, 本文设计了一个带有仿射变换锚点的文本检测网络。利用网络中较高卷积层的文本位置信息, 结合具有仿射变换形状的锚点, 生成了具有任意方向和仿射变换形状文本的检测网络。在ICDAR2015和ICDAR2017数据集上进行了实验比较, 结果表明, 本文所提出的仿射变换文字检测网络在场景文字检测任务中具有较高的准确率。
参考文献
-
[1]CHEN X, YUILLE A L. Detecting and reading text in natural scenes[C]//Computer Vision and Pattern Recognition.New York, USA: IEEE, 2004: 366-373.
-
[2]WANG K, BELONGIE S. Word spotting in the wild[C]//Proceeding of 11th European Conference on Computer Vision.Amsterdam: Springer, 2010: 591-604.
-
[3]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016.
-
[4]BUTA M, NEUMANN L, MATAS J. Fastext: efficient unconstrained scene text detector[C]//2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1206-1214.
-
[5]ZHOU X, YAO C, WEN H, et al. EAST: an efficient and accurate scene text detector[C]//Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 2642-2651.
-
[6]ZHANG Z, ZHANG C, SHEN W, et al. Multi-oriented text detection with fully convolutional net-works[C]//Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016.
-
[7]LIAO M H, ZHU Z, SHI B G, et al. Rotation-sensitive regression for oriented scene text detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 5909-5918.
-
[8]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe: ACM, 2012: 1097-1105.
-
[9]周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6): 1229-1251.
-
[10]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Patterm Analysis and Multimedia, 2017, 39(6): 1137-1149.
-
[11]LIN G S, MILAN A, SHEN C H, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation[C]//Computer Vision and Pattern Recognition.Honolulu, HI, USA: IEEE, 2017: 1925-1934.
-
[12]MA J Q, SHAO W Y, YE H, et al. Arbitrary-oriented scene text detection via rotation proposals[J]. IEEE Transactions on Multimedia, 2018, 20(11): 3111-3122. DOI:10.1109/TMM.2018.2818020
-
[13]KARATZAS D, GOMEZ-BIGORDA L, NICOLAOU A, et al.Competition on robust reading[C]//13th International Conference on Document Analysis and Recognition.Nancy, France: IEEE, 2015: 1156-1160.
-
[14]BURIE J C, CHENGLIN L.Icdar 2017 competition on multi-lingual scene text detection and script identification[DB/OL].(2017-11-09)[2019-11-20].http://rrc.cvc.uab.es/?ch=8&com=introduction.
-
[15]TIAN Z, HUANG W L, HE T, et al.Detecting text in natural image with connectionist text proposal network[C]//European Conference on Computer Vision. Cham: Springer, 2016: 56-72.
-
[16]YAO C, BAI X, SANG N, et al.Scene text detection via holistic, multi-channel prediction[EB/OL].(2016-06-29)[2019-11-20].https://arXiv.org/abs/1606.09002.
-
[17]LIU Y L, JIN L W.Deep matching prior network: toward tighter multi-oriented text detection[C]//2017 Conference on IEEE Computer Vision Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 1275-1282.


