|
|
|
发布时间: 2021-06-25 |
图像技术 |
|
|
|


|
收稿日期: 2020-05-27
基金项目: 国家自然科学基金(61802250);上海市科学技术委员会地方能力建设项目(15110600700)
中图法分类号: TP391.41
文献标识码: A
文章编号: 2096-8299(2021)03-0277-07
|
摘要
为了自动、准确、高效地评估采集图像的质量,设计了一个名为MTIQA的卷积神经网络。该网络能够输出与主观评价指标保持较高一致性的客观评估结果。MTIQA采用多任务学习策略,包含网络训练质量评估和失真类型分类两个任务,将两个任务的损失融合并构成新的损失函数。为了评估算法所得到的客观指标的可靠性,建立了名为SIR2019的单眼虹膜质量评估数据集,并召集志愿者进行主观实验以得到主观评价指标。在SIR2019和CASIA-Iris-Distance-Lamp数据集上的实验结果表明,该网络在虹膜图像质量评估上具有较好的可行性、准确性和鲁棒性。
关键词
虹膜图像; 质量评估; 卷积神经网络; 多任务学习
Abstract
In order to automatically, accurately and efficiently evaluate the quality of collected images, a convolutional neural network named MTIQA is designed, which can output objective evaluation results with high consistency with subjective evaluation indexes.MTIQA adopts the multi-task learning strategy, classifies the two tasks through a network training quality assessment and distortion type, and finally fuses the losses of the two tasks into a new loss function.In order to evaluate the reliability of the objective indexes obtained by the algorithm, a monocular iris quality evaluation dataset named SIR2019 is established, and volunteers are recruited for subjective experiments to obtain the subjective evaluation indexes.The proposed network is tested on SIR2019 and CASIA-Iris-Distance-Lamp datasets.The experimental results show that the proposed network has good accuracy, robustness and feasibility in iris image quality evaluation.
Key words
iris images; quality assessment; convolution neural network; multi-task learning
虹膜设备采集到的虹膜图片, 会受到如光照、曝光、光圈和镜头限制等多方面因素的影响, 若处理不当, 可能会产生干扰识别的图像伪影, 降低图片的视觉质量, 从而影响虹膜识别的结果。若是能够自动预测虹膜图像的质量, 便可以及时筛选出低质量图片进行预处理或重新捕获等操作。传统的图像质量评估(Image Quality Assessment, IQA)方法可以分为主观评估方法和客观评估方法。主观的IQA方法是以人的主观意识为判断的评价方法, 在许多常规场景下不便使用, 如实时和自动化系统等, 因此有必要开发客观的IQA方法来自动、可靠地测量图像质量。
DAUGMAN J G[1]首次提出了虹膜图像质量评价的概念, 通过对虹膜图像二维傅里叶频谱中的高频分量进行求和计算, 将阈值作为评判标准, 判断虹膜图像是否清晰。陈戟等人[2]提出了一种新的基于小波包分解的算法, 将虹膜纹理进行小波包分解, 通过计算其高频能量来实现对图像的评估。晁静静等人[3]提出了一种新颖的多指标融合的虹膜IQA方法, 选取多个质量指标, 利用GA-BP神经网络将多个指标融合, 从而得到一个关于虹膜图像的综合评估分数。
如今虹膜IQA领域对于计算效率和泛化能力的要求越来越高, 传统方法逐渐不能满足许多苛刻的条件, 同时也无法较为准确地表征人的主观评价意见。随着深度学习的快速发展, 其强大的学习能力、泛化能力及可移植性, 可以很好地解决传统IQA算法中存在的一些问题。KANG L等人[4]首次提出了将卷积神经网络(Convolutional Neural Networks, CNN)模型用于IQA任务, 并通过实验证明其有效性。因此, 本文将卷积神经网络与虹膜IQA相结合, 提出了一种新的基于多任务CNN的无参考IQA方法, 具有快速、准确、鲁棒等特点。
1 多任务卷积神经网络结构
1.1 多任务学习
在一些应用场景中, 有限的训练数据导致模型过拟合, 泛化能力弱。多任务学习(Multi-Task Learning, MTL)是一种归纳迁移机制, 主要目标是利用隐含在多个相关任务的训练信号中的特定领域信息来提高泛化能力, MTL通过使用共享表示并行训练多个任务来完成这一目标[5]。虹膜IQA的数据集标注工作量较大, 训练数据有限, 因此使用多任务学习的方法较为合适。
1.2 图像预处理
输入图像预处理过程主要分为3个步骤。
步骤1 数据集原始图像大小均为800×600像素, 包含大量的非虹膜区域, 为了有效地剔除干扰信息, 采用文献[6]所提出的虹膜快速定位方法, 将虹膜目标区域用矩形框框出, 选取框内的图像作为后续环节的输入样本, 并通过归一化统一其尺寸。
步骤2 对局部对比度进行归一化处理, 突出图像的边缘特征。
步骤3 将图像分割为32×32像素的重叠小块作为神经网络的输入。“块”操作有助于网络提取到更多的虹膜边缘特征和底层信息, 同时由于数据集样本并不丰富, 以重叠的图像块进行输入也起到了数据增强的作用。
1.3 多任务图像质量评估网络
本文设计的多任务图像质量评估网络(Multi-Task Image Quality Assessment, MTIQA)结构示意如图 1所示。


由图 1可以看出, 在网络结构的上半部分, 采取与文献[7]中VGG16网络相类似的结构, 卷积层分为5个区块。5个区块在结构上保持一致, 都是由反复堆叠的3×3的小型卷积核和2×2的最大池化层构成。因为使用3×3的小型卷积串联比1个较大的卷积核拥有更少的参数量和更多的非线性变换。第5个区块后接2个全连接层, 使用ReLU作为激活函数, 利用dropout方式来减少过拟合的可能性。
在多任务网络的末端分为线性回归层和逻辑回归层两个子层, 分别用于质量评估和失真类型分类。两个任务都将第2个全连接层的输出作为输入, 并共享之前的所有网络结构。
1.4 损失函数设计
本文以虹膜IQA作为主要任务, 经过预处理操作后, 网络输入的图像为32×32像素的小块, 使用MTIQA网络对每个小块进行打分, 并采取平均池化策略得到图像的质量分数。
若xi为第i个小块的质量分数, 则一幅被分割为N个重叠的小块图像的整体质量分数Q(x)为
| $ Q(x) = \frac{{\sum\limits_{i = 1}^N {{x_i}} }}{N} $ | (1) |
为了将得到的分数与主观分数进行有效比较, 质量评估任务采用的损失函数表示为
| $ {L_{{\rm{quality }}}} = \sum\limits_{i = 0}^N {\left| {{y_i} - Q\left( {{x_i}} \right)} \right|} $ | (2) |
式中: Lquality——虹膜IQA任务的损失函数;
yi——主观真实值;
Q(xi)——输入xi得到的评估值。
辅助任务的目标是对失真类型进行分类。分类任务选用Softmax作为分类器, 采用分类交叉熵的损失函数表示为
| ${L_{{\rm{distortions }}}} = - \frac{1}{N}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^M {{T_{i,j}}} } \ln {P_{i,j}} $ | (3) |
式中: Ldistortions——失真类型分类的损失函数;
M——总类别数;
j——类别;
Ti, j——真实的分类标签;
Pi, j——预测的分类。
多任务网络需要增加一个线性约束将上述两类损失函数融合成一个损失函数。融合损失函数表示为
| $ L=\lambda L_{\text {quality }}+(1-\lambda) L_{\text {distortions }} $ | (4) |
式中: L——融合后的损失函数;
λ——主要任务的损失函数的权重。
由于两项任务的损失函数不同, 所以对应的损失也有所不同。但多任务网络归根结底是为了进行质量评估, 主要任务的损失应占有更大的比重, 故引入λ作为超参数来平衡两项任务的重要性。
2 实验数据集及质量评价指标
质量评估数据集比较特殊, 不仅需要大量的数据, 而且数据的标签平均主观得分(Mean Opinion Score, MOS)需要通过主观实验得到。由于主观实验工作量较大, 且需要大量经过培训的志愿者配合, 故目前还没有公开的虹膜IQA数据集。鉴于以上情况, 本文建立了一个新的虹膜IQA数据集SIR2019, 用于评价客观指标的准确性。
2.1 数据集
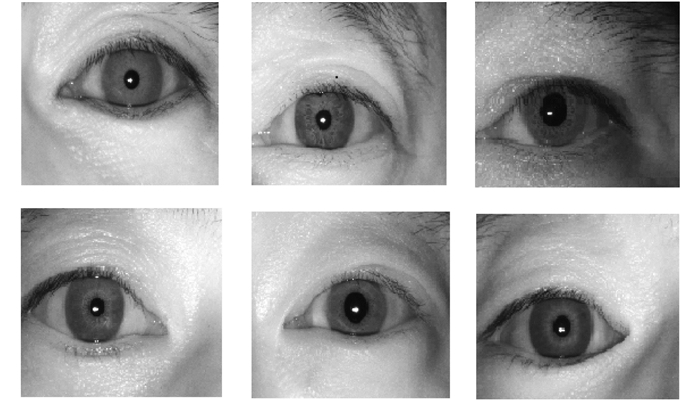
本文在某煤矿矿车司机虹膜图像库中选取了6幅具有代表性的图片作为参考图像, 如图 2所示。
由于自然失真图像数量较少且类别难以界定, 故IQA领域通常采用人为添加失真的方式生成数据集中的失真图片。表 1为SIR2019数据集中所包含的失真类型及对应场景, 其中的失真均为人为添加, 每个失真包括5个级别。
表 1
SIR2019数据集所包含的失真类型
| 失真类型 | 对应实际出现的场景 |
| 高斯白噪声 | 图像采集 |
| 椒盐高斯噪声 | 图像采集 |
| JPEG压缩 | JPEG压缩 |
| JPEG2000压缩 | JPEG2000压缩 |
| 高斯模糊 | 图像配准 |
本文所选取的5种失真类型在实际应用中经常出现, 且在通用质量评价数据集中较为常见。通过调节函数中的参数设置, 为6幅参考图片添加不同类型和等级的失真。通过大量的试验选择合适的参数, 使生成的不同失真等级的图片之间能够存在人类可以观察到的视觉感知差异。创建完成的SIR2019数据集包含6张参考图片, 150张失真图片。
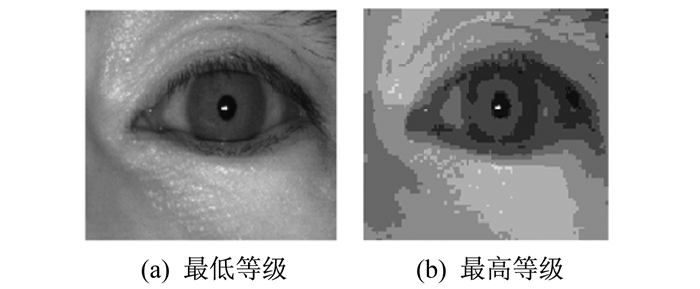
图 3为参考图片进行不同等级的JPEG压缩后生成的最低等级和最高等级失真图片之间的差异对比。
2.2 主观实验
在主观实验中, 由观察者评估图像的质量, 最终统计出MOS值。根据主观实验所选策略的不同, 志愿者可以被要求评估图像的绝对质量, 或与参考图片比较评估异同程度。主观评价实验策略通常基于单激励和双激励损伤量表、双激励连续质量量表(Double Stimulus Continuous Quality Scale, DSCQS)设计。策略必须符合主观质量评价国际标准ITU-R BT.1788建议书《对多媒体应用中视频质量的主观评估方法》。
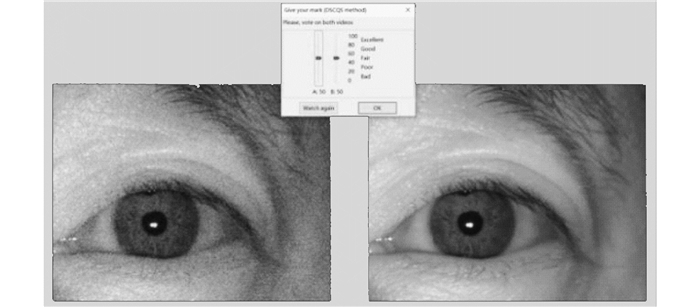
本文主观实验使用莫斯科国立大学图形和媒体实验室开源的图像及视频主观实验软件MSU Perceptual Video Quality Tool, 选择DSCQSⅡ策略。在实验中, 将参考图像与失真图像同时显示, 可以更直接地让打分者感知两幅图像之间的差异, 从而给出更加客观的MOS值。分值范围设置为1~100。实验软件打分窗口如图 4所示。
共有9名观察员参加了本次实验。在实验前对他们进行了初步的指导和预评估, 实验过程中有专业人员监督。
SIR2019数据集中150幅失真图片的MOS值如图 5所示。所有类型所有等级的失真图片的平均MOS值如图 6所示。
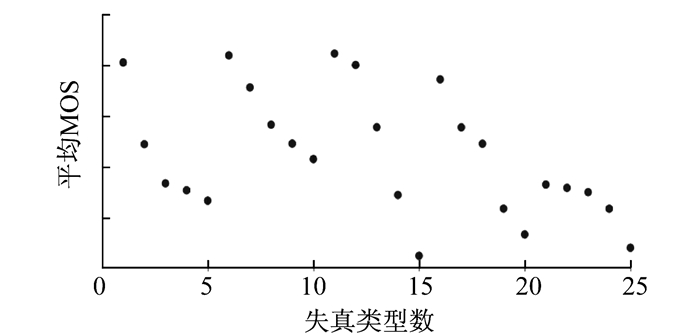
2.3 质量评价指标对比及分析
质量评价指标验证实验将SIR2019数据集划分为几种特定的子集, 分别代表不同的情景。子集包括一种或几种类型的失真图片。表 2为用于验证指标的4种子集。其中, “+”代表添加该种失真类型图片到此子集中。
表 2
用于验证指标的4种子集
| 失真类型 | 子集 | |||
| Noise | JPEG | Actual | Full | |
| 高斯白噪声 | + | + | + | |
| 椒盐高斯噪声 | + | + | ||
| JPEG压缩 | + | + | ||
| JPEG2000压缩 | + | + | ||
| 高斯模糊 | + | + | + | |
为了验证数据集的可用性, 选取以下12种经典图像质量评估算法作为数据集评价指标, 包括: VIF[8], BRISQUE[9], FSIM[10], MSSIM[11], VSNR[12], PSNR-HVS, PSNR-HVSM, PSNR, MSE, GMSD, BIQI, SSIM[13]。以上指标均在IQA领域被广泛使用, 大量的实验证实了这些指标与人的意志具有较高的主观一致性。因此, 计算以上指标与主观实验所得MOS值之间的Spearman秩相关系数(Spearman’s Rank Order Correlation Coefficient, SROCC)和Kendall秩相关系数(Kendall Rank Order Correlation Coefficient, KROCC), 能够定量地验证主观实验所得MOS值是否可用; 同时, 可以间接地判断该数据集能否用作训练数据。12个质量评估指标与4种所选子集之间的SROCC和KROCE如表 3和表 4所示, 表中加下划线的数据代表每个子集的最佳指标。
表 3
12个质量评估指标与4种子集之间的SROCC
| 指标 | Noise | JPEG | Actual | Full |
| VIF | 0.882 | 0.937 | 0.698 | 0.924 |
| BRISQUE | 0.852 | 0.907 | 0.631 | 0.873 |
| FSIM | 0.770 | 0.931 | 0.494 | 0.872 |
| MSSIM | 0.768 | 0.921 | 0.681 | 0.846 |
| VSNR | 0.832 | 0.886 | 0.746 | 0.840 |
| PSNR-HVS | 0.880 | 0.921 | 0.703 | 0.835 |
| PSNR-HVSM | 0.863 | 0.919 | 0.715 | 0.833 |
| PSNR | 0.689 | 0.888 | 0.664 | 0.825 |
| MSE | 0.689 | 0.888 | 0.664 | 0.825 |
| GMSD | 0.726 | 0.925 | 0.452 | 0.820 |
| BIQI | 0.665 | 0.814 | 0.355 | 0.820 |
| SSIM | 0.618 | 0.891 | 0.436 | 0.770 |
表 4
12个质量评估指标与4种子集之间的KROCC
| 指标 | Noise | JPEG | Actual | Full |
| VIF | 0.718 | 0.792 | 0.544 | 0.767 |
| BRISQUE | 0.676 | 0.741 | 0.474 | 0.703 |
| FSIM | 0.597 | 0.774 | 0.381 | 0.691 |
| MSSIM | 0.588 | 0.761 | 0.517 | 0.659 |
| VSNR | 0.653 | 0.698 | 0.576 | 0.652 |
| PSNR-HVS | 0.711 | 0.764 | 0.545 | 0.659 |
| PSNR-HVSM | 0.687 | 0.758 | 0.558 | 0.653 |
| PSNR | 0.503 | 0.714 | 0.496 | 0.630 |
| MSE | 0.503 | 0.714 | 0.496 | 0.630 |
| GMSD | 0.538 | 0.765 | 0.330 | 0.623 |
| BIQI | 0.477 | 0.645 | 0.234 | 0.620 |
| SSIM | 0.426 | 0.725 | 0.295 | 0.571 |
针对所涉及的4种子集, SIR2019数据集与两个图像质量通用数据集TID2013[14]和LIVE[15]的指标验证实验结果均具有较高的相似性。在大多数情景下, SIR2019数据集的MOS值与所选验证指标具有较高的相关性, 即证明了主观实验得到的MOS值是可用的。综上所述, SIR2019数据集可用于无参考虹膜图像质量评估。
3 算法评估实验及其有效性验证
3.1 算法评估实验
3.1.1 评价指标
通常情况下, SROCC和线性相关系数(Linear Correlation Coefficient, LCC)被用于评价质量算法的优劣性。其中, SROCC用于衡量模型算法的单调性, LCC通过计算真实值和预测值的关系来评价模型的估计精度。SROCC和LCC的值越高, 意味着评估算法越好。其定义分别为
| $ {{\rm{SROCC }} = 1 - \frac{{\sum\limits_{i = 1}^K {{\rm{d}}_i^2} }}{{K\left( {{n^2} - 1} \right)}}} $ | (5) |
| $ {{\rm{LCC}} = \frac{{\sum\limits_i {\left( {{p_i} - \bar p} \right)} \times \left( {{g_i} - \bar g} \right)}}{{\sqrt {\sum\limits_i {{{\left( {{p_i} - \bar p} \right)}^2}} \times {{\left( {{g_i} - \bar g} \right)}^2}} }}} $ | (6) |
式中: di——图像在主观评分中的位次与网络学习分数位次的差值;
K——进行评价的图像总数;
pi——模型通过训练学习到的图像的预测分数;
g——对应图像的主观质量评分, 即真实值。
3.1.2 实验结果分析
MTIQA中, 质量评估为主任务, 使用SROCC和LCC作为评价指标; 失真类型分类为次任务, 使用较为常见的分类准确率作为评价指标。SIR2019数据集在MTIQA中进行训练, 最终次任务的评价指标分类准确率达到100%。由于多任务学习能够获取相近任务中的有效信息, 次任务作为一种辅助, 其较高的准确率对于主任务的性能也将会有明显的提高。不同的IQA方法在SIR2019数据集上的实验结果如表 5所示。
表 5
不同IQA方法在SIR2019数据集上的实验结果
| IQA方法 | SROCC | LCC |
| VIF | 0.924 | 0.911 |
| BRISQUE | 0.873 | 0.883 |
| CNNIQA[4] | 0.841 | 0.938 |
| 本文方法 | 0.933 | 0.940 |
由表 5可以看到, 与传统的全参考方法VIF相比, 本文方法的SROCC提升了0.97%, LCC提升了3.18%; 与无参考方法CNNIQA相比, 本文方法的SROCC提升了10.94%, LCC提升了0.21%。上述结果验证了MTIQA网络的有效性。
3.2 算法有效性验证实验
错误匹配率(False Match Rate, FMR)和错误不匹配率(False Non-Match Rate, FNMR)是虹膜识别常用的性能评价指标, 它们随阈值的改变而改变。在验证实验中, 一般取FMR=0.001时FNMR的值作为参考值, FNMR参考值越小, 算法的识别性能越好。检测错误权衡图(Detection Error Tradeoff, DET)则是一种描述FMR与FNMR之间随阈值变化而变化的曲线图。将FMR和FNMR压缩在一个坐标系内, 曲线越靠近x轴, 说明算法的识别性能越好。
虹膜IQA研究的根本目的在于提升虹膜识别系统的性能。本文设计的验证实验使用CASIA-Iris-Distance-Lamp数据集, 通过质量评估算法对数据集中所有样本进行评分, 将一定比例的质量分数最低的样本摒弃。随后对摒弃前后的数据集分别进行虹膜匹配, 得到不同阈值所对应的FMR和FNMR, 并画出所对应的DET曲线图。根据DET曲线图和FNMR参考值, 可以判断质量评估算法的有效性及其对于虹膜识别性能提升的程度。不同的图像评估算法在CASIA-Iris-Distance-Lamp数据集上的有效性验证实验DET曲线如图 7所示。其中, 曲线1表示CASIA-Iris-Distance-Lamp数据集原始曲线, 曲线2表示使用BRISQUE算法摒弃3%低质量图片后的DET曲线, 曲线3表示使用CNNIQA算法摒弃3%低质量图片后的DET曲线, 曲线4和5分别表示使用本文算法摒弃3%和8%低质量图片后的DET曲线。
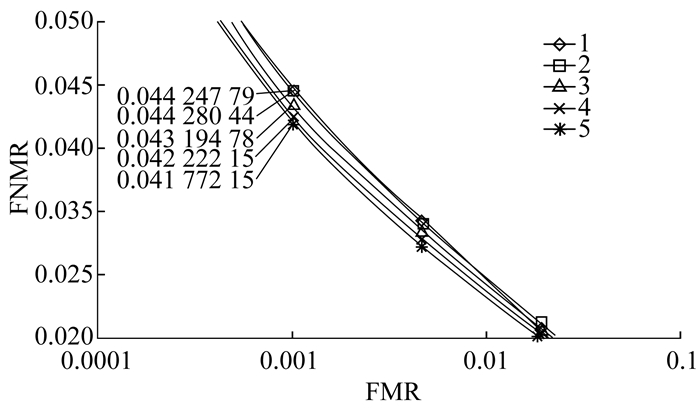
由图 7可以看出, 无论基于何种质量评估算法, 在摒弃一定比例的低质量图像后, FNMR均呈减小趋势。通过比较本文算法摒弃比例分别为3%和8%的情况, 证明随着摒弃比例的增加, FNMR减小的程度也随之增加。由此可见, 摒弃低质量图片能够有效地提升虹膜识别系统的性能。此外, 通过比较图中涉及算法摒弃3%低质量图片后的DET曲线可以发现, 本文算法所对应的曲线与初始曲线的分离程度最大, 且FNMR参考值最小, 较初始曲线的参考值下降了4.65%。这表明, 本文算法与虹膜识别系统对于图像质量的感知具有较高的一致性, 所摒弃的低质量图像对于识别系统的负面影响更大, 从侧面印证了本文算法的准确性和有效性。
4 结语
本文提出了一种多任务卷积神经网络MTIQA以实现对虹膜图像的质量评估, 同时完成图像质量的定量评估和失真类型的分类任务。由于数据有限, 所以只建立了虹膜IQA数据集SIR2019。在SIR2019数据集上的实验取得了不错的效果, 证明了算法的准确性; 同时, 通过在CASIA-Iris-Distance-Lamp数据集上实验, 考察了算法对识别系统性能的影响, 验证了算法的有效性。
参考文献
-
[1]DAUGMAN J G. High confidence visual recognition of persons by a test of statistical independence[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1993, 15(11): 1148-1161.
-
[2]陈戟, 胡广书, 徐进. 基于小波包分解的虹膜图像质量评价算法[J]. 清华大学学报, 2003, 43(3): 377-38. DOI:10.3321/j.issn:1000-0054.2003.03.026
-
[3]晁静静, 沈文忠, 宋天舒, 等. 基于多指标融合的虹膜图像质量评估方法[J]. 仪表技术, 2019(3): 24-28.
-
[4]KANG L, YE P, LI Y, et al. Convolutional neural networks for no-reference image quality assessment[C]//2014 IEEE Conference on CVPR. Columbus, OH, USA: IEEE, 2014: 1733-1740.
-
[5]CARUANA R. Multitask learning[J]. Mach Learn, 1997, 28(1): 41-75. DOI:10.1023/A:1007379606734
-
[6]滕童, 沈文忠, 毛云丰. 基于级联神经网络的多任务虹膜快速定位方法[J]. 计算机工程与应用, 2020, 56(12): 118-124. DOI:10.3778/j.issn.1002-8331.1903-0145
-
[7]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//International Conference on Learning Representations, 2015.
-
[8]SHEIKH H R, BOVIK A C. Image information and visual quality[J]. IEEE Trans Image Process, 2006, 15(2): 430-444. DOI:10.1109/TIP.2005.859378
-
[9]MITTAL A, MOORTHY A K, BOVIK A C. No-reference image quality assessment in the spatial domain[J]. IEEE Trans Image Process, 2012, 21(12): 4695-4708. DOI:10.1109/TIP.2012.2214050
-
[10]ZHANG L, ZHANG L, MOU X, et al. FSIM: a feature similarity index for image quality assessment[J]. IEEE Trans Image Process, 2011, 20(8): 2378-2386. DOI:10.1109/TIP.2011.2109730
-
[11]WANG Z, SIMONCELLI E P, BOVIK A C. Multiscale structural similarity for image quality assessment[C]//Proc 37th Asilomar Conf Signals, Syst Comput, 2003: 1398-1402.
-
[12]CHANDLER D M, HEMAMI S S. VSNR: a wavelet-based visual signal-to-noise ratio for natural images[J]. IEEE Trans Image Process, 2007, 16(9): 2284-2298. DOI:10.1109/TIP.2007.901820
-
[13]WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Trans Image Process, 2004, 13(4): 600-612. DOI:10.1109/TIP.2003.819861
-
[14]SJEIKH H R, WANG Z, CORMACK L, et al. Live image quality assessment database[EB/OL]. (2005-06-10)[2020-05-02]. http://live.ece.utexas.edu/research/quality.
-
[15]PONOMARENKO N, JIN L, IEREMEIEV O, et al. Image database TID2013:Peculiarities, results and perspectives[J]. Signal Process Image Commun, 2015, 30: 57-77. DOI:10.1016/j.image.2014.10.009


