|
|
|
发布时间: 2021-10-28 |
计算机信息科学 |
|
|
|


|
收稿日期: 2020-03-18
基金项目: 国家自然科学基金(61672337)
中图法分类号: TP399
文献标识码: A
文章编号: 2096-8299(2021)05-0491-05
|
摘要
随着互联网技术的飞速发展,互联网用户在畅游网络的同时也面临着信息过载的问题,而个性化推荐技术则成为了解决信息过载问题的有力工具。为了对用户提供更精准的商品推荐服务,提出了一个基于栈式降噪自编码器(SDAE)和贝叶斯个性化排序(BPR)相结合的深度神经网络模型SDAE-BPR。首先,使用SDAE把商品评分数据作为输入,编码后得到隐特征。其次,用BPR的方法学习对应商品的隐特征向量。该模型能够避免矩阵稀疏性的影响,因此达到了更精准推荐商品的效果。最后,分别使用Movielens 20 M和Movielens 1 M数据集,对SDAE-BPR模型与传统基于商品的协同过滤模型(IB-CF)、传统基于用户的协同过滤模型(UB-CF)做了对比,结果发现SDAE-BPR具有更高的准确度。
关键词
推荐系统; 栈式降噪自编码器; 贝叶斯个性化排序; 深度学习
Abstract
With the development of Internet technology, the problem of information overload needs to be solved.Personalized recommendation technology has become a powerful tool to solve the problem of information overload.In order to provide more accurate commodity recommendation service for users, a deep neural network model (SDAE-BPR) based on the combination of stack denoising auto-encoder(SDAE) and Bayesian personalized ranking(BPR) is proposed.Firstly, SDAE is used to take the commodity score data as input, and the hidden features are obtained after coding.Secondly, the implicit feature vectors of the corresponding commodities are learned by the method of BPR.This model can avoid the influence of matrix sparsity, thus achieving the effect of more accurate commodity recommendation.Finally, based on Movielens 20 M data set, the results of SDAE-BPR are compared with the traditional item-based collaborative filtering model(IB-CF) and the traditional user-based collaborative filtering model(UB-CF).It can be seen that SDAE-BPR has higher accuracy.
Key words
recommendation system; stack denoising auto-encoder; Bayesian personalized ranking; deep learning
推荐系统在电子商务平台中发挥着极其重要的作用, 因为它能帮助平台向用户推广广告和产品, 带来巨大的商业效益[1]。目前, 协同过滤是应用最广泛的商业推荐算法。该算法通过学习已有的商品用户评价建立评价矩阵, 预测未评分商品的用户评价[2]。随着大数据时代的到来, 用户和产品的数量都在飙升。大多数产品只被一小部分用户评价过。因此, 评价矩阵的稀疏性严重影响了推荐结果的质量[3]。
为了提高推荐结果的准确率, 本文利用基于贝叶斯个性化排序(Bayesian Personalized Ranking, BPR)和栈式降噪自编码器(Stack Denoising Auto-Encoder, SDAE)的深度学习网络来确定每个商品独有的相关性排序表, 提出了一种新的推荐方法。此方法与以前依赖特定上下文信息的方法不同, 对每个商品在特征提取步骤中选择SDAE方法。该方法在输入数据中加入噪声, 具有较强的泛化能力和鲁棒性[4]。另外, 通过对其他商品和自身的相似度排序, 可以保证更相似的商品比不相似商品的相似度高, 从而解决不平衡问题。
1 模型描述
1.1 模型结构
本文提出的模型融合了SDAE和BPR的优点, 形成了一个新的深度学习模型(SDAE-BPR)。首先, 通过SDAE对深度网络进行提取, 每个条目的评价向量可以得到更复杂的隐藏特征表示。同时噪声的加入也提高了模型的抗干扰性, 使得提取的特征更加可靠。其次, 最后的BPR排序部分可以更好地捕捉每个商品的独特特征, 给出每个商品之间相似度的概率, 有效减少数据稀疏性的影响。模型结构示意如图 1所示。
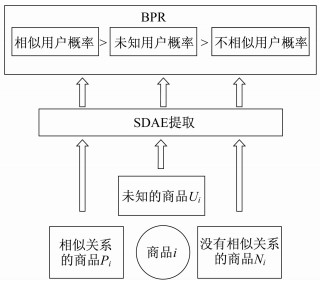

1.2 问题定义
在提出的模型中, 用u∈RN表示用户, i∈RI表示商品。定义E ∈[0, 1]I×N表示全部用户对所有商品的评分构成的评价矩阵。eiu=E(i, u)=1表示用户u∈RN对商品i∈RI感兴趣, eiu=E(i, u)=0表示用户u∈RN对商品i∈RI不感兴趣。在实际应用中, 评价矩阵E通常是稀疏的, 因为大部分用户接触到的商品只是整个商品数据库中极少的一部分。
定义R∈[0, 1]I×N表示商品之间相似概率构成的相似概率矩阵, rij=R(i, j)=p(eij=1)表示商品i和商品j相似的概率。这样对于每个商品i都可以分为两个不相交的集合——即具有相似关系的商品集合Pi={u|rij=1}, 其余不确定相似关系的商品集合Mi={u|rij < 1}。定义相似概率矩阵的目的是要实现推荐排序任务的学习模型, 也就是保证有相似关系的商品全部排在相似关系不确定的商品前面。通过进一步分析, 把不确定相似关系的商品Mi分为未知的商品Ui和没有相似关系的商品Ni, 即Mi = Ui∪Ni。在排序任务的训练过程中, 应保证j∈Pi和k∈Mi, 或者j∈Ui和k∈Ni, 则商品相似概率rij应该大于rik。在BPR中, 这个关系称为偏序关系j > ik。
基于以上定义, 本文的商品推荐可以分为两类偏序关系: Pi与Mi之间的偏序关系{j > ik| j∈Pi和k∈Mi}和Ui与Ni之间的偏序关系{j > ik|j∈Ui和k∈Ni}。商品i的所有偏序关系式的集合表示为Ri={(j, k)| j > ik}。因此, 可以看出在本文中商品推荐任务的实质就是排序任务, 相比分类和拟合, 排序任务可以更好地避免不平衡问题。这个排序任务的最终目标是排序似然概率最大化, 公式如下
| $ {\rm{max}}\prod\limits_{{\rm{i}} \in {\mathit{R}^\mathit{I}}} {\prod\limits_{(\mathit{j}, \mathit{k}) \in {\mathit{R}_\mathit{i}}} {\mathit{p}(\mathit{j} > {\mathit{i}_\mathit{k}})} } $ | (1) |
1.3 特征提取
SDAE将多个降噪编码器连接在一起, 是一种深度模型结构。对于普通的自编码器来说, 如果仅仅通过最小化输入、输出之间的误差来提取商品评分的特征, 那么很容易得到一个恒等函数。本文采用多层降噪编码器相连的原因在于, 如果在每个商品的用户评分中加入噪声, 自编码器在重构输入数据时就需要被迫去除这种噪声, 因为增加了去除噪声的过程, 特征提取层训练后也会相应得到一个比恒等函数更为复杂的函数。为了消除评分中噪声的影响, 在损失函数中加入L2正则项[5], 其目的是对过大的权重进行惩罚。在如今互联网海量数据信息的背景下, 浅层模型面对众多商品的评分向量时表达能力有限, 不能准确区分出不同商品的特征。深度模型可以通过更强大的深层提取能力获得用户对每个商品评分背后隐藏的特质, 在提取方面更形象、更具有代表性[6]。
模型中的SDAE部分隐层H共3层, 结构为U-A-B, U为每条商品评分向量的输入层, A, B分别为第1个隐层和第2个隐层。对于原始评分x按照比例在输入网络之前将其中的部分数据赋值为0得到x~。把x~代入后采用逐层贪婪训练策略依次训练网络的每一层, 进而预训练整个深度网络, 最终使用最后一个隐层训练得到的编码为该商品的隐特征, 考虑到输入数据的非线性和非负性, 选择Sigmoid函数作为SDAE部分的激活函数, 其中的权值矩阵为W, 偏置向量为b。
训练过程如下: 首先代入x~经过第1个隐层得到f1, 再把f1代入解码函数得到x′1, 对于每一条输入的商品评分, 它在任一层的重构误差函数为
| $ \begin{array}{l} l\left( {x, {x^\prime }} \right) = - \sum\limits_{n = 1}^N {{x_n}} {\log _2}\left( {x_n^\prime } \right) + \\ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\left( {1 - {x_n}} \right){\log _2}\left( {1 - x_n^\prime } \right) \end{array} $ | (2) |
式中: x′——评分经编码和解码后的重构。
对于整个包含I条商品数据的训练集来说, 它在该层的整体误差函数为
| $ \begin{aligned} J(\theta)=-\frac{1}{I}\left[\sum\limits_{i=1}^{I} \sum\limits_{n=1}^{N} x_{n}^{(i)} \log _{2}\left(x_{n}^{\prime(i)}\right)+\right.\\ \left(1-x_{n}^{(i)}\right) \log _{2}\left(1-x_{n}^{\prime(i)}\right)+\\ \left.\frac{\lambda}{2 N} \sum\limits_{h=1}^{H-1} \sum\limits_{i=1}^{I_{h}} \sum\limits_{n=1}^{I_{h+1}}\left(\theta^{(h)}\;\;_{n i}\right)^{2}\right] \end{aligned} $ | (3) |
式中: θ, λ——正则化参数;
h——神经网络的层数;
In——该层神经网络中商品元素的个数。
每一次的训练目标就是最小化这个误差函数。其中, 为了防止过拟合引入正则化参数λ来减小权重幅, 对于每一层的误差函数使用反向传播法和随机梯度下降法相结合求出这一层的参数θl, 在这个参数下该层得到的输出fl即为下一层隐层的输入。重复迭代以上训练过程, 保留每层训练得到的参数。
1.4 排序学习
模型结构其余部分基于隐层H, 在最后的输出层采用BPR方法, 对输出结果做排序学习, 使最相似的商品排在最前面, 最终推荐出的商品就从排名前k个商品中选取。训练模型使式(1)的似然概率最大化, 整个模型的损失函数为
| $ \begin{aligned} L\left(\theta_{\mathrm{c}}, \theta_{\mathrm{r}}\right)=-\sum\limits_{i=1}^{I} \sum\limits_{\left(j, k \in R_{i}\right)} p\left(j>i_{k}\right)+\\ \lambda_{1}\left\|\theta_{\mathrm{c}}\right\|^{2}+\lambda_{2}\left\|\theta_{\mathrm{r}}\right\|^{2} \end{aligned} $ | (4) |
θc={W11, W12, b11, b12}为SDAE部分的权重和偏置, θr={W2, b2, b3}是其他部分的参数, 即隐藏层和推理层的权重和偏置。经过SDAE层的预训练后, 再次对θc和θr使用反向传播的随机梯度下降法确定。当梯度稳定后, 针对每个商品i计算其余所有商品和它相似的概率rij, 并制作一个排名列表。系统根据这张排名列表向用户推荐商品。在模型训练结束后, 输入任意两个商品的用户评价向量, 可以得到这两个商品相似的概率值即rij=p(eij=1), 而这个概率值就是推荐商品的理由。
隐藏层的输入部分为Fi, Fj, Fk, 即商品i, j, k经过SDAE后提取出的特征, 作用为将其嵌入Hi, Hj, Hk中作进一步的计算。在该层的神经网络中选择ReLU函数作为激活函数, 这里的隐层作用并非提取特征, 因此可以选用一个信息量相对较少但收敛速度更快的ReLU函数, 即
| $ {\mathit{\boldsymbol{H}}_\mathit{i}} = {\rm{ReLU}}({\mathit{\boldsymbol{W}}^2}{\mathit{\boldsymbol{F}}_\mathit{i}} + {\mathit{\boldsymbol{b}}_2}) $ | (5) |
推理层的输入为Hi, Hj, Hk, 输出为rij和rik的相似概率, 即
| $ {\mathit{\boldsymbol{r}}_{\mathit{ij}}} = \mathit{\sigma }(\mathit{\boldsymbol{b}}_3^\mathit{i} + \mathit{\boldsymbol{b}}_3^\mathit{j} + {\mathit{\boldsymbol{H}}_\mathit{j}}\mathit{\boldsymbol{H}}_\mathit{i}^{\rm{T}}) $ | (6) |
这里的激活函数选择Sigmoid函数是因为要保证最后输出的概率rij∈[0, 1]。在隐藏层中, 为了提高训练的效率, 所有的商品都使用了相同的参数{w2, b2}, 但是在推理层每个商品都有自己独特的参数b3, 这样更有利于发掘每个商品内在的潜质, 提高推荐的准确性。rij与rik之间相似关系的概率定义为
| $ \mathit{p}(\mathit{j} > \mathit{i}{ _\mathit{k}}) = \frac{{{\mathit{r}_{\mathit{ij}}} - {\mathit{r}_{\mathit{ik}}}}}{2} + 0.5 $ | (7) |
2 实验结果分析
2.1 数据集
实验部分将本文所提出的模型SDAE-BPR与两个现有经典协同过滤商品推荐算法模型, 即基于商品的协同过滤(IB-CF)、基于用户的协同过滤(UB-CF)进行了比较。以下实验分别基于互联网上已经公开的Movielens 20 M数据集和Movielens 1 M数据集, 数据集分别包含20 M和1 M大小的真实用户对各个电影的评分txt文件。每种方法都在数据集中使用10折交叉验证, 并显示平均结果。
2.2 评价指标
为了检验不同方法在指定数据集上的性能, 使用受试者工作曲线下的面积(AUC)和归一化折损累计增益(NDCG)作为指标[7]来评估不同推荐方法的性能, 并绘制P-R曲线图进行直观比较。AUC能够衡量一个学习器的优劣, AUC的值越大, 通常可以说明该学习器的效果越好。NDCG表示高关联度结果是否排名靠前, NDCG值越高, 说明排序靠前的结果相关性越高。P-R曲线是以精准率和召回率为变量而做出的曲线, 其中召回率为横坐标, 精准率为纵坐标。如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住, 则可断言后者的性能优于前者。
2.3 实验结果
为了测量3种模型在不同大小数据集上的性能, 分别使用Movielens 20 M和Movielens 1 M数据集对这些模型进行验证。AUC和NDCG@6以及P-R曲线的结果对比如表 1、图 2、图 3所示。
表 1
3种模型的AUC和NDCG@6结果对比
| 模型 | Movielens 20 M | Movielens 1 M | |||
| AUC | NDCG@6 | AUC | NDCG@6 | ||
| UB-CF | 0.926 | 0.883 | 0.913 | 0.839 | |
| IB-CF | 0.941 | 0.892 | 0.927 | 0.874 | |
| SDAE-BPR | 0.967 | 0.971 | 0.944 | 0.958 | |
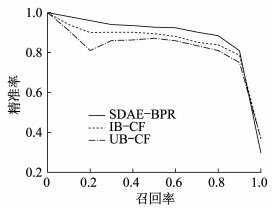
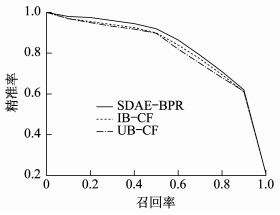
由表 1的数据可以看出: 对于Movielens 20 M数据集, SDAE-BPR的AUC比IB-CF高2.6%。比UB-CF高4.1%;对于Movielens 1 M数据集, SDAE-BPR的AUC比IB-CF高1.7%, 比UB-CF高3.1%。在横向比较的基础上, 随着训练样本大小的增加, 模型能够更好地拟合。因此, 这3种模型在大型数据集上的性能都优于小型数据集。从纵向上看, SDAE-BPR在每个训练集上的表现最好, 其次是IB-CF, 而UB-CF的性能最差。
由图 2和图 3可以看出, SDAE-BPR的P-R曲线基本包住了其他两个模型的曲线。根据前文对P-R曲线的定义, 可以得出SDAE-BPR的综合性能在大数据集和小数据集上都是最好的。这里得出的结论与AUC的结果一致。通过比较这两个结果, 可以清楚地看出SDAE-BPR比其他两种经典协同过滤商品推荐算法模型具有更好的综合性能。但是在图 3中, 所有模型的P-R曲线几乎重合。这一现象说明本文提出的模型在数据量大的情况下更能表现出较好的效果。
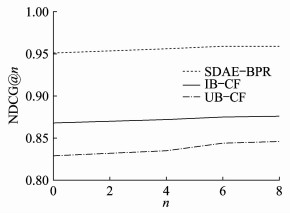
图 4和图 5为选取不同n值时3种模型的NDCG结果图。由图 4和图 5可以看出: 当n=6时, NDCG趋于稳定, 因此选择6作为n的值; SDAE-BPR的曲线远高于其他两条曲线, 即SDAE-BPR模型的NDCG@n也大于其他两种经典协同过滤商品推荐算法模型。由此可以证明SDAE-BPR的排序结果总是比经典算法模型更精确。

3 结语
本文把已有的BPR模型和SDAE相结合来推荐商品, 其中SDAE部分用来提取用户评价向量的隐特征, BPR部分利用已提取的隐特征来获取商品的深层特性, 并在此基础上提出了一套适用于该模型的预训练和微调策略用于提高训练效率和推荐准确度。经过实验验证, 所提出的模型比现有的经典协同过滤商品推荐算法模型具有更良好的性能, 如准确率更高, 排序结果更好, 也避免了稀疏性的影响。但是该模型仍有一些缺点, 如当数据量较大时, 对每个商品提取特征并且计算任意两个商品的相似概率, 模型的学习和数据的保存都可能会遇到困难, 因此在大规模的商业应用之前还需要进行优化。
参考文献
-
[1]赛智产业研究院. 2017中国社交网络创新Top100数据分析[EB/OL]. (2018-01-06)[2020-03-10]. http://www.innov100.com.
-
[2]ZHANG S, YAO L, SUN A, et al. Deep learning based recommender system: a survey and new perspectives[J]. ACM Computing Surveys (CSUR), 2019, 52(1): 5.
-
[3]DENG S, HUANG L, XU G, et al. On deep learning for trust-aware recommendations in social networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(5): 1164-1177.
-
[4]KARATZOGLOU A, HIDASI B. Deep learning for recommender systems[C]//Proceedings of the Eleventh ACM Conference on Recommender Systems. New York: Association for Computing Machinery, 2017: 396-397.
-
[5]SHAN Y, HOENS T R, JIAO J, et al. Deep crossing: web-scale modeling without manually crafted combinatorial features[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, 2017: 255-262.
-
[6]GUOHF, TANG R M, YE Y M, et al. DeepFM: a factorization-machine based neural network for CTR prediction[C]//Proceedings of the 26th International Joint Conference on Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2017: 1725-1731.
-
[7]崔承刚, 邹宇航. 基于深度学习的LSTM光伏预测[J]. 上海电力学院学报, 2019, 35(6): 544-552.


