|
|
|
发布时间: 2022-04-25 |
计算机与信息科学 |
|
|
|


|
收稿日期: 2020-02-28
中图法分类号: TN949.6
文献标识码: A
文章编号: 2096-8299(2022)02-0158-05
|
摘要
针对以CPU为处理平台的H.265/HEVC串并行编码效率较低的问题, 设计了一种基于异构多核CPU+GPU处理平台的并行实时编码算法。按照CPU和GPU互不相同的硬件特性分配任务, 降低了时间复杂度, 同时使CPU和GPU的协作能力获得了提升, 计算资源得到了更加合理的利用。视频编码并行化设计提高了编码效率, 高清视频的编码速度最高可达26.31帧/s, 实现了高清视频的实时编码。
关键词
实时编码; 异构多处理平台; 并行化设计
Abstract
Aiming at the low efficiency of H.265/HEVC serial parallel coding based on CPU, a parallel real-time coding algorithm based on heterogeneous multi-core CPU+GPU processing platform is designed.According to the different hardware characteristics of CPU and GPU, tasks are allocated, which reduces the time complexity, improves the cooperation ability of GPU and CPU, and makes more reasonable use of computing resources.The parallel design of video coding improves the coding efficiency and makes the coding speed of high-definition video up to 26.31 fps, realizing the real-time coding of high-definition video.
Key words
real time coding; heterogeneous multiprocessing platform; parallel design
科学技术的进步使人类社会不断走向高科技, 视频和音频的应用逐渐深入人们的生活, 遍及社会的各个方面, 从而导致了视音频流量、占用空间以及所需的传输带宽也越来越大[1]。这意味着对视音频编码的研究开发已成为一个重要课题。
在云服务方面, 研究人员针对视频编码发布了高效视频编码(High Efficiency Video Coding, HEVC)[2]新编码标准。在云端, 离线编码通常可以借助于大量的计算资源来保持较高的编码效率。HEVC是在H.264/AVC的基础上发展而来, 其视频压缩的编码效率是H.264/AVC的2倍[3], 但HEVC的编码时间和所需的计算资源有所增加, 因此编码复杂度也进一步提高[4]。究其原因是HEVC标准增加了新工具和新模式[5], 导致编码速度达不到要求, 而且还增加了不必要的开销。值得庆幸的是, 云端的并行化资源十分强大, 如多核中央处理器(CPUs)和图形处理器(GPUs)等。本文为了提高HEVC的编码效率, 对多核CPU及其对应的GPU协同工作进行了研究。
1 基于异构多核处理器的视频编码框架
目前, 异构多处理平台中应用最多的架构是CPU+GPU架构。CPU和GPU的建造结构、硬件特点互不相同, 因此二者的数据处理能力和对应的运行任务也不相同。依据这一原则分配任务, 就可以充分利用CPU和GPU内核不同的计算能力。
GPU的计算能力比CPU强, 数据传输带宽更大, 性能功耗比更高[6], 因此一般利用GPU处理高并行计算任务, 利用CPU处理逻辑运算和任务调度。此外, 与CPU相比, GPU拥有的数据缓冲和控制单元数量较少, 因此正常情况下GPU更适用于执行密集型数据计算以及高数据并行的计算任务[7]。在视频压缩过程中, 数据之间必然相互关联, 也就是说数据与数据之间存在着相关性。与串行视频编码框架相比, 异构多处理平台的视频编码框架主要是通过CPU和GPU的高效率协作, 实现最佳的视频编码效率。
无论是在时间还是空间上, 相邻块皆存在着非常强的相关性。由于时间上相邻块存在强烈相关性, 且运动估计(在相邻帧中找到最佳预测块并记录相对运动向量)的预测块来源于已编码的视频帧, 与当前视频帧无关, 因此可以在GPU中实现运动估计的并行处理。但在空间上, 对帧内编码时采用并行处理会破坏相邻块的相关性, 导致编码效率急剧下降, 因此GPU不适用于并行处理空间相邻块。
相对于运动估计来说, 变换和量化所占用的处理时间有限, 并行处理对于加速编码和减少计算时间的作用有限, 熵编码过程中不同编码树单元(Coding Tree Unit, CTU)之间互不依赖、相互独立, 但是熵编码过程需要利用各种信息及指令, 而GPU具有强大的计算能力, 但不适合处理各种判断指令, 所以在GPU上不适合熵编码及变换和量化的并行处理。图 1为基于异构多处理平台的视频编码框架。
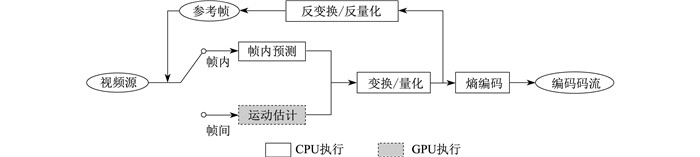

综上所述, 在异构多处理平台的视频编码框架中, GPU仅执行运动估计过程, 其他过程如变换与量化、帧内预测、熵编码等, 都在CPU中处理和执行。
2 异构多核CPU+GPU并行编码设计
本文将编码器分成大小可变块运动估计(Motion Estimation with Variable Block Size, VBSME)、模式决策、编码与重建、去块滤波、分数像素插值和熵编码6个部分。其中VBSME是编码器中最耗时的模块。在本文设计的异构处理器并行编码框架中, VBSME、去块滤波和分数像素插值模块将由GPU处理, 其他剩余模块在多核CPU中处理。上述并行编码框架如图 2所示。

本文提出的编码框架有以下两级并行。
(1) 第1级是CPU和GPU的并行。将读到的一帧图像复制到GPU中, 然后进行插值同步判断, 由插值同步单元负责决定GPU中是执行运动估计还是执行插值。若已经是插值同步, 则GPU执行运动估计, 否则, GPU执行插值。
(2) 第2级是多核CPU中的多流水线并行[8]。运动估计完成后, 在多核CPU中创建多条流水线, 通过波前并行处理(Wavefront Parrallel Processing, WPP)同步单元判断是否由WPP同步来做下一步的决定, 即处理模式决策、编码、重建或等待所有的CTU完成。
在第1级并行中, 插值同步单元保证了第1级的并行化执行。在第2级并行中, WPP同步单元负责多核CPU中的多条流水线同步问题, 保证了第2级的并行化执行。多核CPU的多条流水线并行化是基于文献[8]提出的WPP并行策略。在CPU创建的多条流水线中用单条流水线执行熵编码。在波前并行中, 每帧图像被划分为CTU行, 在同一CTU行的所有CTU将作为同一流水线处理。只有当上一行CTU被编码和重建时, 来自不同CTU行的CTU才能够被同时处理。这个条件由WPP同步单元保证。
3 运动估计
在视频编码中, 运动估计是最重要的部分, 运动估计的好坏将直接影响到编码效率。本文将第1级并行中的运动估计最小块限制为8×8像素, 在此条件下, 一个CTU能分为64个8×8像素块。GPU中基于运动估计的算法采用了文献[9]的思想, 利用全搜索算法和1/4像素精度插值。该算法分为以下4个部分。
(1) 8×8像素块的绝对差值和(Sum of Absolute Difference, SAD)计算。运动估计搜索范围设定为32×32像素, 因此对于每个8×8像素块有1 024个候选运动向量。
(2) 其他尺寸块的SAD计算。算出8×8像素块的SAD后, 只需将相应的8×8像素块的SAD相加即可获得其他尺寸的SAD[10]。例如, 8×16像素或16×8像素块的SAD可以由其对应的两个8×8像素块的SAD相加得到。更大的SAD可按此方法依次生成。
(3) 最佳整像素运动矢量(Interger pixel Motion Vector, IMV)选择。最小SAD对应的IMV就是最佳IMV, 最小的SAD需要通过比较判决来选择。采用1个线程处理1 024个SAD, 共有256个线程, 每个线程分配4个SAD, 再给256个SAD值分配128线程, 每个线程比较两个SAD。依次迭代计算8次, 最后得出最小的SAD及其对应的运动向量(Motion Vector, MV)。
(4) 分数像素插值及运动估计。在插值运算后每个整数像素周围有24个分数像素, 因此可以对整数像素周围的24个分数像素进行运动估计。
GPU经过以上过程处理完一帧视频, 将每种块的最小SAD及其对应MV传送至CPU内存, CPU利用WPP单元进行并行处理, 找出最优良的CTU划分模式。
4 WPP模式决策
在WPP单元的模式决策中, 为了使CPU和GPU的工作量达到平衡, 并加速模式决策, 本文提出了以下快速预测单元(Prediction Units, PU)划分方案[11-13]。
步骤1 采用SKIP检测和CBF_fast检测算法。若SKIP不满足, 则进行CBF_fast检测, 并且当CBF_fast的条件也不满足, 则跳转到步骤2;否则将编码单元(Code Units, CU)深度设置为数字4并跳转到步骤5。
步骤2 快速CU划分。判断4个N×N像素PU的MV与2N×2N像素PU的MV之间的最大差值是否小于等于6。如果是, 那么CU以2N×2N的大小编码, 并将其深度赋值为4, 然后跳到步骤5;否则, 执行步骤3。
步骤3 用2N×2N像素的PU和其对应的MV进行运动补偿, 并计算残差块的纹理图案。
步骤4 计算率失真代价, 对比并选择最小的一个值。
步骤5 检查CU深度是否为4, 所有的4个N×N块是否已经处理完。如果条件为真, 则处理编码重建; 否则, 将CU划分为4个子CU或处理下一个CU, 并回到步骤1。
在所有CPU流水线完成一帧图像的重建后, 将重建图像复制到GPU。CPU主流水线(在OpenMP[14]中主线程的编号为0)控制GPU按照顺序异步执行去块滤波和插值。CPU熵编码的执行和GPU主流水线对插值和边界填充任务的执行是同时进行的。在插值同步单元保证下最后重建帧的边界扩展分数像素图像准备就绪后, CPU主流水线对当前帧启动新的VBSME任务。
5 实验结果与分析
本文基于实用性的开源编码器X265[15-16], 支持H.265/HEVC主要档次的大部分功能, 用C语言实现, 硬件采用HP Z620工作站, 其配置为8核CPU, 工作频率2.6 GHz, NVIDIA Tesla C2050 GPU, 操作系统为64位Windows7旗舰版。
用Proposed表示本文所设计的并行编码器, 利用HM10.0, X265和Proposed分别对BasketballDrive视频序列和Cactus视频序列进行编码。3种编码器的压缩性能和编码速度分别如表 1和表 2所示。其中, 采用峰值信噪比(Peak Signal to Noise Ratio, PSNR)作为压缩性能的评价指标。采用8线程WPP, 所有编码器的主要配置为: 编码测试序列前50帧, 一个I帧和49个P帧; 关闭近似消息传递功能; 关闭样本自适应偏移(Sample Adaptive Offset, SAO)功能; 搜索范围为32×32像素; HM参考模型软件使用TZ快速搜索, 其他编码器使用全搜索; 关闭码率控制功能, 6个量化参数(Quantization Parameter, QP)分别为22, 24, 26, 28, 31, 34;测试序列选为BasketballDrive_1 920×1 080_50.yuv和Cactus_1 920×1 080_50.yuv。由于高清视频尺寸为1 920×1 080, 不可划分为整数个CTU, 为此在GPU中对视频序列填充了8行(1 920×1 088), 使输入和预测视频帧可以划分为整数个CTU。
表 1
3种编码器对BasketballDrive序列的编码实验结果
| QP | HM10.0 | X265 | Proposed | |||||
| 编码速度/(帧·s-1) | PSNR/dB | 编码速度/(帧·s-1) | PSNR/dB | 编码速度/(帧·s-1) | PSNR/dB | |||
| 34 | 0.031 | 36.299 | 2.41 | 35.812 | 26.31 | 35.679 | ||
| 31 | 0.029 | 37.341 | 2.22 | 36.868 | 23.13 | 36.703 | ||
| 28 | 0.025 | 38.274 | 1.83 | 37.652 | 20.64 | 37.543 | ||
| 26 | 0.022 | 38.791 | 1.56 | 38.251 | 17.11 | 38.144 | ||
| 24 | 0.018 | 39.345 | 1.31 | 38.735 | 13.23 | 38.581 | ||
| 22 | 0.014 | 40.124 | 1.14 | 39.412 | 9.86 | 39.221 | ||
表 2
3种编码器对Cactus序列的编码实验结果
| QP | HM10.0 | X265 | Proposed | |||||
| 编码速度/(帧·s-1) | PSNR/dB | 编码速度/(帧·s-1) | PSNR/dB | 编码速度/(帧·s-1) | PSNR/dB | |||
| 34 | 0.032 | 33.889 | 2.43 | 33.312 | 26.32 | 33.091 | ||
| 31 | 0.030 | 35.392 | 2.18 | 34.881 | 23.16 | 34.562 | ||
| 28 | 0.025 | 36.678 | 1.89 | 36.023 | 20.68 | 35.779 | ||
| 26 | 0.022 | 37.243 | 1.61 | 36.655 | 17.15 | 36.396 | ||
| 24 | 0.018 | 37.963 | 1.37 | 37.362 | 13.31 | 37.165 | ||
| 22 | 0.013 | 39.072 | 1.19 | 38.417 | 9.91 | 38.171 | ||
由表 1数据可以看出, Proposed编码BasketballDrive视频序列的速度最高可达26.31帧/s, 相对于HM10.0的0.031帧/s, 加速比为848, PSNR为0.620 dB(QP=34);相对于X265的2.41帧/s, 加速比为11, PSNR为0.133 dB(QP=34)。
表 2中数据表明, Proposed编码Cactus视频序列的速度可达26.32帧/s, 相对于HM10.0的0.032帧/s, 加速比为822, PSNR为0.798 dB(QP=34);相对于X265的2.43帧/s, 加速比为11, PSNR为0.221 dB(QP=34)。
采用调用函数计算得出, 本文所设计的并行编码器编码BasketballDrive序列的总体速度相对HM10.0编码器加速比约为790, PSNR约为0.700 dB; 编码Cactus序列的总体速度相对HM10.0加速比约为790, PSNR约为0.840 dB。
本文提出的编码器虽然率失真性能有一定的损失, 但是其最快的编码速度相对于其他编码器有极大的提高, 已接近于实时编码, 有较好的应用前景。
6 结语
为了达到HEVC高清视频实时编码这一目标, 本文采用异构多核CPU+GPU多处理平台, 利用该平台的并行加速性能来加速HEVC编码。根据CPU和GPU的不同结构和数据处理能力, 对二者的性能进行了剖析, 并按照其不同的特点, 设计了相应的算法以实现异构多处理平台的并行视频编码, 加快了对高清视频的编码速度, 使其极大地接近实时编码。实验结果表明, 该编码器对高清视频的编码速度最高可达26.31帧/s, 加速比高达848, 具有良好的应用前景。
参考文献
-
[1]沈晓琳. HEVC低复杂度编码优化算法研究[D]. 杭州: 浙江大学, 2013.
-
[2]MISRA K, SEGALL A, HOROWITZ M, et al. An overview of tiles in HEVC[J]. IEEE Journal of Selected Topics in Signal Processing, 2013, 7(6): 969-977. DOI:10.1109/JSTSP.2013.2271451
-
[3]WIEGAND T, OHM J R, SULLIVAN G J, et al. Special section on the joint call for proposals on high efficiency video coding (HEVC) standardization[C]//IEEE Transactions on Circuits and Systems for Video Technology. Piscataway: IEEE, 2010: 1661-1666.
-
[4]CORREA G, ASSUNCAO P, CRUZ L A D S, et al. Encoding time control system for HEVC based on Rate-Distortion-Complexity analysis[C]//IEEE International Symposium on Circuits and Systems. Piscataway: IEEE, 2015: 1114-1117.
-
[5]朱秀昌, 李欣, 陈杰. 新一代视频编码标准——HEVC[J]. 南京邮电大学学报(自然科学版), 2013, 33(3): 1-11.
-
[6]文化龙. 基于GPU的LDA算法并行化设计与实现[D]. 北京: 北京邮电大学, 2012.
-
[7]阳王东, 王昊天, 张宇峰, 等. 异构混合并行计算综述[J]. 计算机科学, 2020, 47(8): 5-16.
-
[8]ZHAO Z, LIANG P. Data partition for wavefront parallelization of H. 264 video encoder[C]//IEEE International Symposium on Circuits & Systems. Island of Kos, Greece: IEEE, 2006: 1693173.
-
[9]CHEN W N, HANG H M.H. 264/AVC motion estimation implementation on compute unified device architecture (CUDA)[C]//2008 IEEE International Conference on Multimedia and Expo (ICME 08). IEEE, 2008: 697-700.
-
[10]谢晓燕, 雷祥, 崔继型. H.265整数运动估计参考块更新的并行化设计[J]. 电视技术, 2017(增刊4): 1-5.
-
[11]WANG X W, SUN J, LIU Y Q, et al. Fast mode decision for H. 264 video encoder based on ME motion characteristic[C]//2007 IEEE International Conference on Multimedia and Expo(ICME 07). IEEE, 2007: 372-375.
-
[12]严丹钰, 施隆照, 陈清坤, 等. HEVC运动估计快速算法优化及硬件实现[J]. 广播电视网络, 2020(9): 105-110.
-
[13]赵倩. 基于H.264的FGS实时编码技术及实现[J]. 上海电力学院学报, 2009, 29(4): 401-404.
-
[14]黄炎, 王庆宾, 冯进凯. 基于OpenMP多核并行算法的垂线偏差快速计算[J]. 大地测量与地球动力学, 2019, 39(10): 1033-1036.
-
[15]陈钦艺. 基于HEVC的移动视频监控系统[D]. 广州: 华南理工大学, 2016.
-
[16]乔莉, 李博, 舒行科, 等. 高清视频HEVC编码实时传输系统的设计[J]. 实验室研究与探索, 2018, 37(11): 129-132.


