|
|
|
发布时间: 2022-04-25 |
计算机与信息科学 |
|
|
|


|
收稿日期: 2021-04-13
中图法分类号: TP301
文献标识码: A
文章编号: 2096-8299(2022)02-0203-05
|
摘要
企业或组织内部的重要数据都存储在数据库中, 因此数据库经常成为恶意入侵者的攻击目标。传统防火墙对于来自外部的入侵者有着很好的抵御作用, 但无法检测来自系统内部人员的异常访问。针对数据库异常访问检测中存在的不足和缺陷, 提出了一种基于深度特征合成(DFS)和关联规则(Apriori)算法的异常检测方法。通过对比BP神经网络、随机森林和C4.5决策树等3种其他检测算法表明, 新提出的方法能够更加高效地提取用户特征, 从而使检测的精准率和效率有显著提升。
关键词
数据库; 深度特征合成算法; 关联规则算法; 异常检测
Abstract
The important data in the enterprise or organization are stored in the database, so the database often becomes the target of malicious intruders.The traditional firewall can resist the intruders from outside, but it can't detect the abnormal access from inside.Therefore, this paper proposes an anomaly detection method based on deep feature synthesis and Apriori algorithm, aiming at the shortcomings and defects of database anomaly access detection.Experimental comparison of three other detection algorithms shows that: the new method can extract user features more efficiently, so that the accuracy and efficiency of detection are significantly improved.
Key words
database; deep feature synthesis algorithm; Apriori algorithm; anomaly detection
随着信息技术的发展, 人们在日常生活和工作中会产生并存储大量数据, 由此数据安全的相关问题逐渐引起人们的重视。数据库作为数据存储的“基地”, 不仅需要抵御外来入侵者的攻击, 而且需要防止内部人员的恶意操作。根据相关报告显示, 来自企业或组织内部的信息泄露超过总数的1/4, 所造成的损失比来自外部的攻击要严重得多。目前一些学者基于用户访问数据库所生成的日志记录开展了数据库异常访问检测的相关研究[1-4]。由于系统日志文件数量巨大并且包含大量冗余信息, 而传统特征工程是人为地从关系实体中提取特征, 过程繁琐费时, 使得建立检测模型变得十分困难, 导致异常检测的效率较低。为此, 本文提出了一种基于深度特征合成(Deep Feature Synthesis, DFS)与关联规则(Apriori)算法的异常访问检测方案, 目的在于提升数据库内部用户异常访问的检测准确率与效率。
1 研究现状
部分学者对数据库的访问权限控制方法进行了一些改进, 实现了对数据库访问用户的管理。但这种权限控制方法只能预防来自外部无授权的恶意攻击, 无法对内部授权用户和伪装成内部用户的恶意攻击产生应对。传统的异常检测方法使用反向传播(BP)神经网络、随机森林等算法构建异常检测模型, 能准确检测出异常数据, 在相关领域的检测也取得了显著的效果[5-8]。
一些学者将机器学习运用到数据库访问异常检测中来。李勃等人[9]对用户产生的数据库SQL操作日志进行了聚类, 通过对SQL语句中的各属性进行分析来提取用户的异常行为, 并在形成先验知识的基础上创建特征库进行检测。顾兆军和郭靖轩[10]针对审计日志中角色行为特征进行了分析处理, 提出了一种基于角色异常行为挖掘的内部威胁检测方法, 根据序列模式挖掘原理判断角色当前行为是否存在异常。段淼和梁杰[11]通过提取大数据流频繁序列的模式特征, 并将特征提取结果与待检测的大数据流频繁序列进行了模式特征匹配以进行异常检测。文献[12]实现了一种面向数据库管理系统的异常用户行为检测方法。该检测方法的核心是对与数据库交互的用户配置文件进行学习和分析, 将偏离这些配置文件的用户请求当作异常用户。文献[13-14]利用访问事务间和访问事务内的特征进行异常检测, 给出了一种基于信息源和信度更新的数据库异常检测方法。文献[15]运用关联规则和聚类分析在数据库检测系统中进行异常行为的检测。该检测方法通过运用聚类算法, 可以根据用户的角色生成不同的常规配置文件。如果新的用户行为与现有规则不符, 就会被系统标记为异常行为, 进而激活防御功能。文献[16]基于用户行为的多元模式, 提出了一种用户跨域行为模式挖掘方法。文献[17]结合朴素贝叶斯分类法与多标签分类器, 将查询语句的语法结构和查询结果结合成新的用户行为特征。但这种方法仅将查询结果的数目占总查询表的比例作为一项特征加入用户行为轮廓中, 并没有计算查询结果的各项统计特征。文献[18]设计开发了一种数据库误用检测系统, 该系统基于数据库自身的结构特点与查询语句内含语义信息, 利用关联规则构造关系数据库中的用户轮廓来检测用户的异常操作。
综上所述, 目前数据库异常访问检测方法所采用的技术方案相对单一, 例如仅应用机器学习分类器或用户特征的构建, 缺少多种方法的融合运用, 而数据库访问日志文件包含大量冗余属性, 不便于检测者提取有效的特征, 进而导致已有方案的效率和检测准确率均较低。为此, 本文提出了一种基于DFS-AP算法的数据库异常访问检测方案。
2 算法理论
2.1 深度特征合成算法
DFS是一种自动为关系数据集生成特征的算法。该算法将数据之间的关系跟踪到具体的基本字段, 然后依照路径顺序应用数学函数以创建最终特征。算法输入的是一组互连实体以及与其关联的表, 表中各实体中的每个实例都有唯一的标识符。因此, 实体可以利用相关实体的唯一标识符来引用其实例。实体的实例具有属于数字、分类、时间戳和自由文本等数据类型之一的功能。
为了描述DFS算法, 首先假定有K个实体的数据集为E1, …, K。规定输入要素均以“feat”结尾。目标将被设定为提取目标的特征EK, 特征类型如下。
(1) dfeat指关系列表中的前向关系。前向关系指的是实体El中的实例m和Ek中另一个实例i的单个属性之间的关系, 相关实例i∈EK中的特征可以被直接转移为m∈EK的特征。
(2) rfeat用于表示关系列表中的后向关系, 代表从Ek中的实例i到El中与k具有前向关系的所有实例m={1, 2, 3, …, M}的关系。将数学函数运用于x: , j|ekk=m来导出实体的实例i, 它通过提取实体中特征j的所有值来组合Ek, 提取条件是ek=i。这种转换可以表示为
| $ x_{i, j'}^k = r{\rm{feat}}({x^l}_{:, j|{e^k} = i}) $ | (1) |
给定实体合成的特征数量z的计算公式为
| $ {z_i} = \left( {e\cdot j} \right)\sum\limits_{u = 0}^i {[{{\left( {r\cdot m + n} \right)}^u}\left( {e + 1} \right)]} $ | (2) |
式中: i——迭代次数;
e——efeat函数的个数;
r——rfeat函数的个数;
n, m——前向关系和后向关系的个数。
(3) efeat是通过计算每一个属性值来获得特征。这些特征可以通过对xi, ji逐元运用计算函数。其计算过程可表示为
| $ {x_{i, j\prime }} = d{\rm{feat}}({x_{:, j}}, i) $ | (3) |
数据库审计日志作为记录内部用户日常访问数据库的行为记录, 通常数据量巨大。传统特征工程人为从关系实体中提取特征, 不仅过程复杂费时而且容易出现错误, 而DFS算法能够实现关系实体的自动特征工程, 可以精确地为结构化数据构造大量特征。因此, 本文采用DFS提取出目标新的特征, 通过对一列数据求和、求均值、求方差等操作挖掘出数据中隐藏的不易被观测到的信息。利用这些更深层次的特征可以更加高效地表述用户行为准则, 提升异常检测的效率。完整的DFS算法流程如下(其中输入为日志文件中的数据集E1, …, K, 输出为合成的特征集合F):
(1) 将实体集合Ei, E1:M, EV初始化;
(2) 构造后向关系实体集合, 表示为EB=Backward(Ei, E1, 2, 3, …, M)
(3) 构造前向关系实体集合, 表示为EF=Forward(Ei, E1, 2, 3, …, M);
(4) 遍历全部实体, 参照连接关系连接相关联的实体, 当Ej包含在EB中时, 进行rfeat特征构造并将构造的特征导入F;
(5) 再次遍历全部实体, 如果Ej∈EV, 则跳过该实体, 否则进行步骤6和步骤7;
(6) 合成构造Ei与Ej相关的dfeat特征, 将合成的特征导入F;
(7) 对Ei单个集合合成构造efeat特征, 将特征导入F。
2.2 关联规则算法
关联规则是数据挖掘算法的一种, 目的在于发掘项或对象的频繁模式、相互之间的关联关系的过程。假定一组事务集I为{I1, I2, I3, …, Im}, 代表事务数据库; 而J为{J1, J2, J3, …, Jn}, 是一组n个不同的项或属性; 项目集X⊆J的支持度指的是包含项目集X的事务频数与总事务数的比值。如果项目集X的支持度大于或等于设定的支持度阈值, 则称项集X为频繁项集。关联规则算法主要有2个部分: 一是对于给定的数据集, 从中找出所有满足项集支持度大于给定最小支持度的频繁项集; 二是从频繁项集中依据给定的最小支持度找出各项之间存在的关联规则。
生成频繁项集是关联规则算法的关键步骤, 可以细分为2个操作: 首先产生候选项集C; 然后将已经产生的候选项集C根据候选集的支持度和给定最小支持度大小关系进行剪枝来找到频繁项集。算法的主要工作是反复扫描数据库或给定的数据集, 依据计算得出的候选集支持度进而得到新长度的候选集, 直到得到能够表述用户正常行为的规则。通过关联规则算法得到数据关联规则后, 可以将其用于用户行为准则的构建, 从而实现用户异常行为的检测。
3 基于DFSAP算法的异常检测系统
本文结合上述2种算法, 提出了一种基于DFS-AP算法的异常检测系统。由于历史数据中存在大量交叉查询语句、分组结构和属性索引, 因此应该先从数据中提取出用户行为特征, 构造用户行为向量; 然后将用户行为向量作为系统的输入, 从而进行异常检测模型的训练。系统的整体结构如图 1所示。
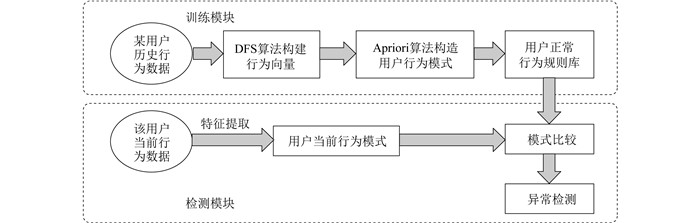

系统的整体流程可以分为如下2个模块。
(1) 训练模块, 对用户历史数据的挖掘以构建行为准则。具体步骤为: 对历史审计日志进行处理, 利用DFS算法分析提取历史数据的特征, 构造出表示用户行为的向量; 通过关联规则算法对用户行为向量进行分析, 挖掘出用户行为模式, 从而得到用户正常访问模式下的行为规则; 将得到的用户行为规则用于构建异常检测模型。
(2) 测试模块, 对新访问的用户进行检测。具体的步骤为: 对用户提交的查询数据进行预处理; 提取用户行为数据的特征, 构建用户当前行为向量, 分析得到用户当前行为模式; 将用户当前行为模式输入异常检测模型中, 通过对比用户的正常行为规则与此次访问之间的偏差来进行异常检测。
4 仿真验证
4.1 测试数据集
鉴于目前真实数据库的审计日志无法轻易获取, 所以本文采用TPC数据库作为实验数据集。TPC-E数据库以美国纽约证券交易为模型, 对客户和股票交易所与证券公司之间的账户查询、在线交易和市场调研等交易进行了模拟。
本实验使用的设备是一台处理器(CPU)为36 GHz四核Intel Core i7、内存为16 G、操作系统为Windows 10的计算机。实验所用的数据库为MySQL 8.0。利用TPC提供的脚本构建TPC-E数据库, 模拟出12种交易事务。为了全面验证模型与方法的有效性, 分别收集了5种不同规模的TPC-E数据集作为实验数据集。将各个数据集的4/5作为训练数据集, 剩余1/5作为测试集。数据集的数据分布情况如表 1所示。
表 1
数据分布情况
| 数据集 | 训练数据 | 测试数据 | 总计 |
| 1 | 86 571 | 41 641 | 128 212 |
| 2 | 164 291 | 41 072 | 205 363 |
| 3 | 246 082 | 61 545 | 307 627 |
| 4 | 325 160 | 83 291 | 408 451 |
| 5 | 301 463 | 100 441 | 401 904 |
4.2 实验结果
运用DFS算法对数据进行特征提取, 再对提取的特征运用关联规则算法进行角色正常行为模式的规则挖掘, 得到角色的正常行为模式, 构建异常检测分类器。本文在此基础上使用BP神经网络[5]、随机森林[8]和C4.5决策树[19]算法进行检测模型的构建, 分别对上述数据集进行训练测试, 并与本文提出的方法进行了对比分析。使用精确率P、召回率R以及精确率与召回率的一种加权平均值F1, 对所提系统的异常检测效果进行评估。3个数值的计算式分别为
| $ P = \frac{{{N_{{\rm{TP}}}}}}{{{N_{{\rm{TP}}}} + {N_{{\rm{FP}}}}}} $ | (4) |
| $ R = \frac{{{N_{{\rm{TP}}}}}}{{{N_{{\rm{TP}}}} + {N_{{\rm{FN}}}}}} $ | (5) |
| $ {F_1} = \frac{{2PR}}{{P + R}} $ | (6) |
式中: NTP——正常访问用户归类为正常类的数量;
NFP——异常访问用户归类为正常类的数量;
NFN——正常访问用户归类为异常类的数量。
不同分类算法的检测结果对比如表 2所示。
表 2
不同分类算法的检测结果对比
| 算法 | P | R | F1 | 训练平均时长 | 测试平均时长 | |
| % | ms | |||||
| 随机森林 | 98.24 | 90.24 | 90.14 | 0.598 | 0.009 | |
| BP神经网络 | 99.25 | 99.25 | 99.25 | 0.494 | 0.005 | |
| C4.5决策树 | 100.00 | 100.00 | 100.00 | 0.090 | 0.001 | |
| DFS-AP | 100.00 | 100.00 | 100.00 | 0.010 | 0.001 |
|
由表 2可以看出, DFS-AP算法的精确率和召回率均达到了100%, 优于随机森林和BP神经网络, 因此能更加精确地对用户行为模式进行构建。此外, DFS-AP算法训练所用平均时间和测试平均时间均最短, 每条记录的平均训练时间为0.010 ms, 测试时间为0.001 ms, 其主要原因在于DFS算法将目标中不重要的特征都去除了, 提高了特征提取效率, 节省了不必要的挖掘时间。C4.5决策树和DFS-AP算法的检测效率都达到了100%, 但C4.5算法模型的训练平均时长为DFS-AP算法的9倍, 构造模型所用时间较长, 检测效率不如DFS-AP算法。
实验对比结果表明, DFS-AP算法可以提高模型构造与测试速度, 能够在保持高检测率的前提下进一步缩短检测时间。
5 结语
本文提出了一种基于DFS和关联规则算法的检测方法用于检测数据库内部合法的异常行为。该方法先运用DFS对复杂的用户访问日志进行特征提取, 再将提取出来的特征构建用户行为, 通过关联规则算法建立检测模型从而进行异常检测。通过相关实验表明, 相较于其他检测方法, 本文所提方法在处理访问数据时所消耗的时间更短, 检测的准确率也更高, 能够更加高效地检测出异常。
参考文献
-
[1]张锐. 基于文件访问行为的内部威胁异常检测模型研究[D]. 北京: 北京交通大学, 2015.
-
[2]李殿伟, 何明亮, 袁方. 基于角色行为模式挖掘的内部威胁检测研究[J]. 信息网络安全, 2017(3): 27-32.
-
[3]魏娜. 面向数据库访问的用户行为异常检测与评估[D]. 南京: 东南大学, 2017.
-
[4]杨先圣, 姜磊, 彭雄, 等. 基于大数据的异常检测方法研究[J]. 计算机工程与科学, 2018, 40(7): 1180-1186. DOI:10.3969/j.issn.1007-130X.2018.07.005
-
[5]李晋国, 丁朋鹏, 王亮亮, 等. 基于NWPSO-BP神经网络的异常用电行为检测算法[J]. 上海电力大学学报, 2020, 36(4): 357-363. DOI:10.3969/j.issn.2096-8299.2020.04.007
-
[6]王真, 李鑫. 基于随机森林的硬件木马检测方法[J]. 上海电力大学学报, 2020, 36(5): 511-516. DOI:10.3969/j.issn.2096-8299.2020.05.018
-
[7]俞庆英, 李倩, 陈传明, 等. 基于BP神经网络的异常轨迹检测方法[J]. 计算机工程, 2019, 45(7): 229-236.
-
[8]RONAO C A, CHO S B. Mining SQL queries to detect anoma-lous database access using random forest and PCA[C]//Conference on Current Approaches in Applied Artificial Intelligence. Berlin: Springer, 2015: 151-160.
-
[9]李勃, 寿曾, 刘昕禹, 等. 融合密度聚类与集成学习的数据库异常检测[J]. 小型微型计算机系统, 2021, 42(3): 666-672.
-
[10]顾兆军, 郭靖轩. 基于角色异常行为挖掘的内部威胁检测方法[J]. 计算机工程与设计, 2020, 41(10): 2740-2746.
-
[11]段淼, 粱杰. 序列模式匹配在大数据流频繁序列异常检测中的应用[J]. 现代电子技术, 2021, 44(3): 59-64.
-
[12]JAYAPRAKASH S, KANDASAMY K. Database intrusion detection system using octraplet and machine learning[C]//2018 Second International Conference on Inventive Communication and Computational Technologies, IEEE, 2018: 1413-1416.
-
[13]PANIGRAHI S, SURAL S, MAJUMDAR A K. Two-stage database intrusion detection by combining multiple evidence and belief update[J]. Information Systems Frontiers, 2013, 15(1): 35-51.
-
[14]RONAO C A, CHO S B. Random forests with weighted voting for anomalous query access detection in relational databases[C]//14th International Conference on Artificial Intelligence and Soft Computing. Berlin: Springer, 2015: 36-48.
-
[15]SINGH I, DARBARI V, KEJRIWAL L, et al. Conditional adherence based classification of transactions for database intrusion detection and prevention[C]//Advances in Computing, Communications and Informatics. Manipal, India: IEEE, 2016: 42-49.
-
[16]文雨, 王伟平, 孟丹. 面向内部威胁检测的用户跨域行为模式挖掘[J]. 计算机学报, 2016, 39(8): 1555-1569.
-
[17]SALLAM A, FADOLALKARIM D, BERTINO E, et al. Dataand syntax centric anomaly detection for relational databases[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2016, 6(6): 231-239.
-
[18]CHUNGC Y, GERTZ M, LEVITT K. DEMIDS: a misuse de-tection system for database systems[C]//Working Conference on Integrity and Internal Control Information Systems. Boston: Springer, 1999: 159-178.
-
[19]MENG X F, ZHANG P, XU Y, et al. Construction of decision tree based on C4.5 algorithm for online voltage stability assessment[J]. International Journal of Electrical Power & Energy Systems, 2020, 118: 105793.


