|
|
|
发布时间: 2024-06-28 |
其他研究 |
|
|
|


|
收稿日期: 2023-12-23
中图法分类号: TP301.6
文献标识码: A
文章编号: 2096-8299(2024)03-0279-06
|
摘要
准确的视线注视方向估计是人机交互和虚拟现实等应用场景中的关键技术。基于外观的视线估计是目前的主流方法,然而,因为眼睛外观、光线条件和头部姿态的多样性,所以无约束环境下的视线估计仍然是一个具有挑战性的任务。提出了一种高频信息视线估计网络(HFA-Net)。首先,在神经网络中加入高频信息提取模块和卷积注意力模块(CBAM),帮助网络减少冗余信息的影响;其次,将视线分为两个角度分别进行回归,并使用独立损失函数进行优化;最后,在公开数据集MPIIGaze上进行训练和测试。实验结果表明,该方法在MPIIGaze上取得了4.17°的最佳角度估计误差,超越目前主流算法。
关键词
视线估计; 高频信息提取; 扩张卷积; 卷积注意力模块
Abstract
Accurate gaze direction estimation is a crucial technology in various applications such as human-computer interaction and virtual reality. The appearance-based gaze estimation is currently the mainstream method. However, due to the diversity in eye appearance, lighting conditions, and head poses, gaze estimation in unconstrained environments remains a challenging task.This paper proposes a high-frequency amplifier gaze estimation network(HFA-Net).Initially incorporating a high-frequency information extraction module and Convolutional Block Attention Module(CBAM)into the neural network helps reduce the impact of redundant information. Finally, the network divides gaze angles into two separate regression tasks, each optimized with independent loss functions. The proposed method is trained and tested on the publicly available MPIIGaze dataset, and experimental results demonstrate that this approach achieves the best angle estimation error of 4.17° on MPIIGaze, surpassing the current mainstream algorithms.
Key words
gaze estimation; high-frequency information extraction; dilated convolutions; convolutional block attention module
近年来,随着人工智能技术的不断发展,人眼视线方向作为反映人类视觉注意力和认知的重要依据被应用于越来越多的场景,如人机交互[1]、医学诊断[2]、虚拟现实[3]等。视线估计方法可以分为基于模型的视线估计和基于外观的视线估计两类。前者主要通过建立几何眼模型估计凝视角度[4-7],以达到高精度的估计效果,但对工作距离、设备有特定的要求;而基于外观的视线估计方法,只需要使用普通的RGB相机且不需要明确眼睛特征,通过建立图像到视线方向的映射函数实现视线估计。随着大数据集和深度学习技术的发展,基于神经网络的视线估计网络迅速发展。文献[8]提出了空间权重神经网络,在全脸特征图上使用具有随机空间权重的卷积核进行区域加权,并通过空间注意力机制改进特征表示,使得更多的权重被分配到人脸图像的特定区域。文献[9]提出了一个基于双眼的非对称回归方法ARE—Net,通过两只眼睛的差异优化视线估计结果,在MPIIGaze数据集上的平均角度误差为5.0°。文献[10-11]利用扩张卷积获得更大的感受野,以捕捉眼睛外观的微小变化,以双眼和脸部图像为输入,在MPIIGaze数据集上的平均角度误差为4.8°。文献[12]提出了RITnet,利用边界感知损失函数和损失调度策略进行视线估计,平均角度误差为4.8°。文献[13]提出了一种从粗到细的自适应网络,该网络首先使用人脸图像预测基本凝视角度,再通过眼部区域获得视线估计的细粒度角度,最后通过一个双图模型桥接基本凝视角度和细粒度角度,其最终平均角度误差为4.27°。文献[14]将transformer引入视线估计,平均角度误差为4.18°。上述研究都是以单独的眼睛或人脸图像作为输入,忽略了两者之间内在的关联性。事实上,除眼睛外,人脸图像中包含的空间信息也对视线估计精度产生影响。因此,本文提出了融合高频信息增强和注意力机制的高频信息视线估计网络(High Frequency Attentive Net,HFANet)。首先,以全脸、双眼图像和头部姿态向量作为输入,并引入卷积注意力模块(Convolutional Block Attention Module,CBAM)机制,调整网络对不同通道和空间位置的关注程度,提高模型的表征能力;然后,依据离散余弦变换原理提出高频信息提取模块,加强包括眼部区域,如虹膜和瞳孔之间的边缘信息,通过更好地学习与视线估计相关的特征信息,提升模型性能;最后,将两个角度拆分送入两个全连接层分别进行回归,并使用三元组损失和均方差融合损失(Triplet and Mean Square Error Fusion Loss,TMF Loss)函数进行监督,以提高每个角度的预测精度,最终回归出俯仰角与偏航角两个方向的角度。
1 实验设计与实验方法
1.1 HFA-Net模型
HFA-Net以眼睛、全脸图像及头部姿态向量作为输入,以形成预测视线真实值的回归函数。HFA-Net结构如图 1所示。
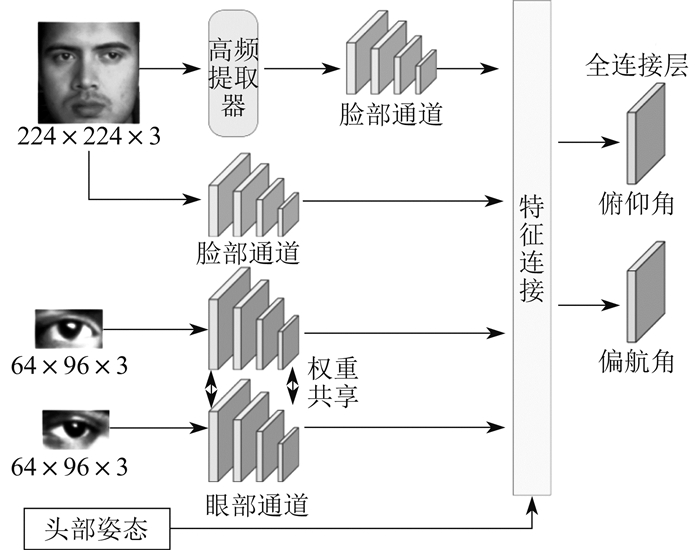

由图 1可知,首先,将归一化的人脸图像与左眼、右眼图像分别输入3个不同的网络通道中。在脸部通道前加入高频信息提取模块,加强包括眼部区域,如虹膜和瞳孔之间的边缘信息,从而有助于网络更好地学习与视线估计相关的特征信息,提升模型性能。接着,将双眼、脸部特征与表征头部姿态的信息进行拼接,进入第2个全连接层,将注视角度拆分为俯仰角、偏航角送入两个全连接层分别进行回归,并设计相应损失函数独立计算损失。最终回归出两个方向的角度。
脸部、眼部神经网络通道结构如图 2所示。其中,Conv为卷积,Max Pool为最大池化层,Di⁃ Conv,rate为扩张卷积扩张率,ReLU为修正线性单元。图 2中,每一层都进行批处理标准化。眼睛和脸部神经网络骨干网络通道的前5层和前6层分别加载VGG16的前5层和前6层在ImageNet上预先训练的权重。本文在眼睛通道中用扩张卷积代替普通卷积,以便在保留特征图分辨率的同时,获得更大的感受野。左眼、右眼的网络通道结构一致且共享权重。

1.2 高频信息提取模块
由于全脸中眼部特征对于完成视线估计任务至关重要,而眼睛轮廓和边界信息又对应频域内的高频特征,因此加强高频信息有助于提高眼部特征表达能力。脸部通道前加入的高频信息提取模块的结构如图 3所示。
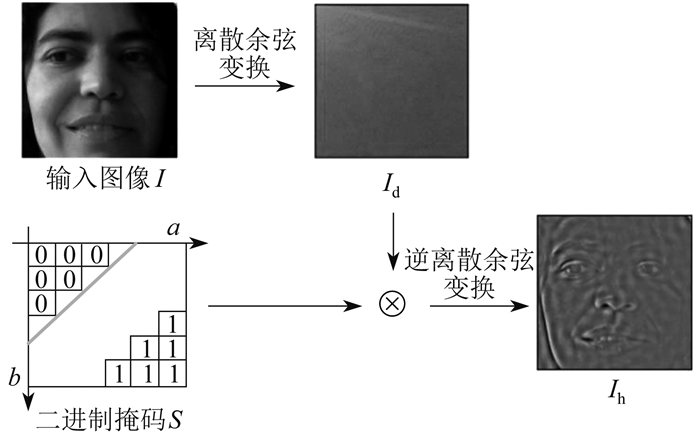
图 3中,首先将输入图像I进行离散余弦变换,得到图像Id;接着图像Id与掩码S进行元素乘积;最后,将得到的结果进行逆离散余弦变换,提取所需的高频信息加强图像Ih。根据逆离散余弦变换后所得到的系数矩阵图可知,从左上角到右下角,频率越来越高。本文设计了一个包含参数α(0~1)的二进制掩码S,其掩码点为
| $ S_{(a, b)}= \begin{cases}0, & b<-a+\alpha x \\ 1, & \text { 其他 }\end{cases} $ | (1) |
式中:x——输入图像高度;
a,b——掩码S的水平坐标和垂直坐标。
不同参数α下的高频信息提取模块结果如图 4所示。

由图 4可知:若参数α取值过小,会因为太过注重低频信息而导致过拟合;若参数α取值过大,大部分与注视估计相关的有用信息会丢失,从而阻碍模型性能的改善。因此,本文将参数α取值为0.2。
1.3 CBAM机制
为了解决卷积神经网络处理图像时信息不均衡和信息丢失等问题,注意力机制被引入到视觉任务中,其作用是动态地给予不同特征权重,从而更好地聚焦于图像中与任务相关的部分,避免计算资源浪费和降低噪声干扰,提高模型的准确性和效率。由于特征的信息级别会随着网络的加深而提高,故本网络在全连接层前引入CBAM机制。该机制主要包括通道注意力和空间注意力。前者首先通过计算每个通道的全局平均值和最大值获取其重要性权重,再用这些权重对原始特征图进行加权求和,以达到动态调整权重,使网络能够更好地关注重要通道特征的目的;后者则首先对特征图进行平均池化和最大池化操作,得到两种不同的空间信息,再通过两个全连接层学习这些信息的权重。CBAM机制的加入,能够帮助网络减少冗余信息的影响,提高特征的紧凑性、有效性及网络视线的估计精度。
1.4 损失函数
大多数基于神经网络的视线估计模型都是将三维注视预测为球坐标下的注视方向角度(俯仰角、偏航角),并且通常采用均方误差(Mean Square Error,MSE)惩罚网络。本文则将两个角度拆分并独立计算损失。设计的损失函数由三元组损失函数和MSE组成。具体来讲,先将回归问题分解为分类问题,然后计算期望值,得到细粒度的视线估计。
损失函数中使用三元组损失函数预测视线分类。三元组由锚样本(Anchor)、最难正样本(Positive)和最难负样本(Negative)组成。其中,最难正样本是指在特征空间上与锚样本距离最远的同类样本;最难负样本是指在特征空间上与锚样本距离最近的异类样本。参照三元组损失函数原理,最终损失函数LT的表达式为
| $ \begin{array}{r} L_{\mathrm{T}}=\max \left(\left\|\boldsymbol{f}_{\text {Anchor }}-\boldsymbol{f}_{\text {Positive }}\right\|^{2}-\right. \\ \left.\quad\left\|\boldsymbol{f}_{\text {Anchor }}-\boldsymbol{f}_{\text {Negative }}\right\|^{2}+M, 0\right) \end{array} $ | (2) |
式中:fAnchor,fPositive,fNegative——锚样本、最难正样本、最难负样本在特征空间上的特征编码向量;
M——边缘阈值参数,设置为0.5。
统计视线输出期望以细化预测,并在输出中添加一个均方误差LMSE(t,y),以改善视线估计的结果。
| $ L_{\mathrm{MSE}}(\mathrm{t}, \mathrm{y})=\frac{1}{N} \sum\limits_{0}^{N}(t-y)^{2} $ | (3) |
式中:N——样本数量;
t——视线角度真实值;
y——视线角度预测值。
最终,每个角度的损失函数LTMF为TMF Loss函数。其公式为
| $ L_{\mathrm{TMF}}=L_{\mathrm{T}}+\omega L_{\mathrm{MSE}}(t, y) $ | (4) |
式中:ω——回归系数。
2 实验过程与结果分析
2.1 实验环境
实验环境为Windows 10的64位系统,采用PyTorch为深度学习框架,编程语言采用Python。计算机内存为64 GB,搭载Intel Core i7-8700K的CPU和NVIDIA GeForce RTX 2080 Ti的GPU。网络一共训练100个epochs,学习率为0.001,采用的优化方法为Adam,batch size为64。
2.2 数据集及评估指标
MPIIGaze包含了15名受试者在不同的光照条件和头部姿势下拍摄的213 659张图像。对采集到的图像进行筛选和半自动标记7个特征点后,使用一个通用三维人脸模型拟合到地标位置,计算得到三维头部姿态。最终得到42 000张图片。
对数据集进行同文献[9]一样的归一化处理。归一化处理后,人脸图像分辨率为224×224,眼部图像分辨率为60×36。
本文用视线角度误差(°)作为视线估计方法的评估指标。数据集标签信息提供的视线角度g ∈R3,视线估计网络输出的视线预测角度ĝ∈R3,视线角度误差gerror为
| $ g_{\text {error }}=\operatorname{arcos}\left(\frac{g \hat{g}}{\|g\|\|\hat{g}\|}\right) $ | (5) |
2.3 HFA-Net训练和测试实验
本文对MPIIGaze使用留一法交叉验证,即每次选取1名受试者作为测试集,剩余的14名受试者作为训练集,以获得鲁棒性结果。HFA-Net训练步骤如下。
步骤1 输入脸部图像I,左眼和右眼图像IL和IR,头部姿态H,HFA-Net预训练权重β或更新权重β*,超参数α、M、ω;
步骤2 获取脸部图像I,通过高频信息提取模块得到图像Ih;
步骤3 输入Ih、I、IL、IR、H,通过HFA-Net推理获得预测视线角度ĝ,ĝ=fHFA(IR,IL,I,Ih,H,β);
步骤4 根据式(4)计算HFA-Net的损失函数LTMF;
步骤5 β*←使用HFA-loss对网络权重β进行更新,跳转到步骤2循环至训练结束;
步骤6 输出视线预测角度ĝ。
HFA-Net测试步骤同步骤2和步骤3。
为了证明本文提出的HFA-Net模型在视线估计误差角度上的优势,设计了与其他模型的对比实验,结果如表 1所示。由于文献[12]中RTGene模型的准确性可以通过4种模型集成提高,故称其为RT-Gene(4种模型),以区别于RTGene模型。
表 1
HFA-Net模型与其他模型的平均视线角度误差
HFA-Net模型与主流视线估计网络模型的参数量和计算复杂度对比如表 2所示。
表 2
HFA-Net模型与主流视线估计网络模型的参数量和计算复杂度对比
| 模型 | 参数量/MB | 计算复杂度/GB |
| FullFace | 196.6 | 2.99 |
| RT-Gene | 82.0 | 30.81 |
| CA-Net | 34.1 | 15.6 |
| HFA-Net | 17.8 | 4.5 |
由表 2可知,HFA-Net模型在保证估计结果精确率的情况下,具备最少的参数量和较小的计算复杂度,在精确率和性能上效果较佳。
2.4 消融实验
为了验证TMF Loss在HFA-Net上的有效性和TMF Loss中不同参数搭配对于实验效果的影响,本文在MPIIGaze数据集上进行实验,实验结果如表 3所示。
表 3
TMF Loss中不同参数的平均视线角度误差
| 回归系数ω | 平均视线角度误差/(°) |
| 1 | 4.59 |
| 2 | 4.43 |
由表 3可知,当回归系数ω=2时,数据集上的平均视线角度误差为4.43°,表现出最佳性能。
为了进一步验证本文算法的有效性和可行性,在MPIIGaze数据集上分别进行消融实验。由于网络中使用了扩张卷积,故将Dilated-Net作为基准网络进行比较,依次添加HFA-Net中不同部分,以验证这些部分是否有利于提升视线回归性能。消融实验结果如表 4所示。
表 4
MPIIGaze数据集消融实验结果
| 实验组别 | 网络结构 | 损失函数 | 平均视线角度误差/(°) |
| 1 | 基准网络 | MSE | 4.80 |
| 2 | 基准网络+头部姿态 | MSE | 4.72 |
| 3 | 基准网络+CBAM+头部姿态 | MSE | 4.57 |
| 4 | 基准网络+头部姿态 | TMF Loss | 4.43 |
| 5 | 基准网络+CBAM+头部姿态 | TMF Loss | 4.24 |
| 6 | 基准网络+CBAM+头部姿态+高频提取模块 | TMF Loss | 4.17 |
由表 4可知,第2组在第1组的基础上,将头部姿态向量和提取到的特征进行拼接,通过后续的全连接层拟合几何变换,使得视线角度误差降低。第3组的角度误差减小,这是由于空间注意力和通道注意力机制优化了特征表示,使得网络更加关注图像中与视线估计相关的区域与特征。第4组修改了损失函数,对俯仰角、偏航角分别进行回归和损失函数计算,提高了每个角度的预测精度,从而提高了整体注视性能。第5组在第4组的基础上加入了注意力机制,视线角度误差进一步降低为4.24°,再次验证了CBAM能够灵活有效地捕捉到视线相关的特征,抑制无关特征。第6组在第5组的基础上增加了高频信息提取模块,视线估计误差角度降低至4.17°。这是由于加强眼部边缘及视线相关特征纹理细节,可以提高特征表达能力,获得更好的视线估计精度。
3 结语
本文提出了一种HFA-Net模型,用于无约束环境下的视线估计任务。HFA-Net模型输入包括双眼图像、人脸图像和头部姿态。一方面,采用扩张卷积技术扩大感受野;另一方面,引入CBAM机制控制不同通道间的相互作用以及不同空间位置的权重,减少网络冗余信息的干扰,聚焦关键特征。在高频信息提取方面,HFA-Net使用了专门的高频信息提取模块。通过该模块,网络可以更加有效地捕捉到图像中的高频细节,提升网络对细微特征和细节的感知能力,提高视线估计的精确性和稳定性。此外,该网络将两个角度分别进行回归,并且为每个视线角度设计了独立TMF Loss函数,有效提高了网络学习能力。实验证实,在具有多种光照、外观和头部姿态的两个无约束数据集MPIIGaze上,本文所建立的模型取得了4.17°的最好视线估计角度误差。未来研究将集中于纯化视线特征以消除光照、外观等的影响,为该算法应用于VR/AR设备奠定基础。
参考文献
-
[1]STRAZDAS D, HINTZ J, KHALIFA A, et al. Robot system assistant (RoSA): towards intuitive multi-modal and multidevice human-robot interaction[J]. Sensors, 2022, 22(3): 923. DOI:10.3390/s22030923
-
[2]JIANG M, ZHAO Q. Learning visual attention to identify people with autism spectrum disorder[C]//Proceedings of the IEEE International Conference on Computer Vision. Salt Lake City, USA: IEEE, 2017: 3267-3276.
-
[3]XU Y, DONG Y, WU J, et al. Gaze prediction in dynamic 360 immersive videos[C]//proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 5333-5342.
-
[4]GUESTRIN E D, EIZENMAN M. General theory of remote gaze estimation using the pupil center and corneal reflections[J]. IEEE Transactions on Biomedical Engineering, 2006, 53(6): 1124-1133. DOI:10.1109/TBME.2005.863952
-
[5]ZHU Z, JI Q. Novel eye gaze tracking techniques under natural head movement[J]. IEEE Transactions on Biomedical Engineering, 2007, 54(12): 2246-2260. DOI:10.1109/TBME.2007.895750
-
[6]JENI L A, COHN J F. Person-independent 3d gaze estimation using face frontalization[C]//Processing of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Lavas, USA: IEEE, 2016: 87-95.
-
[7]FUNES MORA K A, ODOBEZ J M. Geometric generative gaze estimation (g3e) for remote rgb-d cameras[C]//Computer Vision and Pattern Recognition Conference. Columbus, USA: IEEE, 2014: 1773-1780.
-
[8]ZHANG X, SUGANO Y, FRITZ M, et al. It's written all over your face: fullface appearance-based gaze estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Hawaii, USA: IEEE, 2017: 51-60.
-
[9]ZHANG X, SUGANO Y, FRITZ M, et al. Mpiigaze: real-world dataset and deep appearance-based gaze estimation[J]. Transactions on Pattern Analysis and Machine Intelligence, 2017, 41(1): 162-175.
-
[10]CHENG Y, ZHANG X, LU F, et al. Gaze estimation by exploring two-eye asymmetry[J]. Transactions on Image Processing, 2020, 29: 5259-5272. DOI:10.1109/TIP.2020.2982828
-
[11]CHEN Z K, SHI B E. Appearance-based gaze estimation using dilated-convolutions[C]//Asian Conference on Computer Vision. Perth, Australia: ACCV, 2018: 309-324.
-
[12]CHAUDHARY A K, KOTHARI R, ACHARYA M, et al. Ritnet: real-time semantic segmentation of the eye for gaze tracking[C]//2019 International Conference on Computer Vision Workshop (ICCVW). Seoul, Korea: IEEE, 2019: 3698-3702.
-
[13]CHENG Y, HUANG S, WANG F, et al. A coarse-to-fine adaptive network for appearance-based gaze estimation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020: 10623-10630.
-
[14]CHENG Y, LU F. Gaze estimation using transformer[C]//202226th International Conference on Pattern Recognition. Montreal, Canada: IEEE, 2022: 3341-3347.
-
[15]陈号. 上下文感知与区域增强型全脸视线估计方法[D]. 重庆: 重庆大学, 2022.
-
[16]胡长春, 刘笑楠. 基于CBAM-ResNet网络的视线估计方法[J]. 信息技术与信息化, 2023(8): 152-155.
-
[17]王世龙. 基于外观的实时视线估计方法[D]. 哈尔滨: 哈尔滨理工大学, 2023.


