|
|
|
发布时间: 2019-06-10 |
|
|
|
|


|
收稿日期: 2018-10-24
基金项目: 湖北省重点实验室基金资助项目(2015KJ11)
中图法分类号: TM77
文献标识码: A
文章编号: 1006-4729(2019)03-0247-07
|
摘要
广域后备保护可综合利用全网信息, 在传统保护出现错误时, 快速准确地找到故障位置。提出了一种基于聚类算法和改进证据理论的广域后备保护新算法:首先, 基于电网中各子站之间的电气距离特征, 利用k均值聚类算法完成对大电网的分区工作, 由各点故障电压序分量的特征选取可疑故障线路; 然后, 将电气量和保护动作状态量共同作为证据源, 同时对不合理证据进行优化改进; 最终利用改进后的DS证据理论识别故障线路。仿真结果表明, 该方法可有效完成对电网的分区工作, 在保护动作信息部分或者全部出错时均能有效识别故障线路。
关键词
多源信息融合; 证据理论; 聚类算法; 电网分区
Abstract
Wide area backup protection can make full use of the whole network information, and can find the fault location quickly and accurately when the traditional protection is wrong.A new algorithm of wide area backup protection based on clustering algorithm and improved evidence theory is proposed.According to the electrical distance characteristics of each sub station in the grid, the k-means clustering algorithm is used to complete the partitioning work of large power grids, then the suspected fault line is selected, which is based on the characteristic of fault voltage sequence, finally the change characteristics of the fault voltage sequence component and the protection action information are taken as the source of evidence, and at the same time, the irrational evidence is optimized.Finally, the DS evidence theory is used to find the fault location.Simulation results show that this method can effectively complete the work of power grid partition and identify fault lines effectively when the protection action information is in partial or all errors.
Key words
multi-source information fusion; evidence theory; clustering algorithm; grid partition
随着电网规模的日益增大, 继电保护担负的责任越来越重要[1]。传统的基于本地测量的线路主保护一般采用的是各种纵联保护, 发展较为完善, 对各种类型的故障均能做出迅速准确的判断, 但当主保护出现错误时, 其后备保护已不能完全适用于复杂电网[2-3]。因此, 广域后备保护这一概念被提出并成为继电保护中的研究热点[4-5]。
广域后备保护可以收集所有智能电子装置(Intelligent Electronic Device, IED)的信息进行融合决策, 但是过多的信息融合将会造成上传信息的增多和中心主站计算负担的加大, 同时从理论和工程实际的角度出发, 融合全局信息也无必要[6]。因此, 目前对广域后备保护的研究主要集中在以下两个方面:一是大电网的分区和可疑故障线路的选择; 二是信息融合算法。
文献[7]提出了一种综合考虑实时性、经济性、均衡性的分区评价指标, 并基于二层搜索分区算法对大电网进行分区。文献[8]对分区原则、中心站的选取、边界区域的交互等问题进行讨论, 提出了一种基于图论技术的分区方法。文献[9]对故障线路序分量进行分析, 据此建立故障线路启动判据, 有效减少了上传信息量。文献[10]将电气量和状态量相结合, 分别由保护动作值和相量测量单元(Phase Measurement Unit, PMU)测得数据值计算各线路对应的故障概率, 然后加权得到了线路的故障概率。文献[11]利用人工智能算法, 对DS证据理论(Dempster-Shafer Evidence Theory)进行了改进, 并据此进行信息融合, 同时讨论了算法的容错性。
基于以上研究, 本文将对大电网分区方法和故障识别算法进行新的研究。首先, 基于电网中各子站之间的电气距离特征, 利用k均值聚类算法完成对大电网的分区工作; 然后, 由各点故障电压分量的特征选取可疑故障线路, 减少上传信息量; 最后, 将电气量和保护动作状态量共同作为证据源, 利用改进后的DS证据理论识别故障线路。
1 基于聚类算法的系统分区方法
区域集中式结构既具有决策效果好、投资与维护费用低等优点, 同时又可以有效降低各个区域决策中心的计算负担和单点失效的风险。区域集中式结构首先要将大电网分成几个区域。分区主要有以下两方面的工作。
1.1 区域中心主站的选取
中心主站的选取一般要考虑出线数量、变电站人员配置、系统结构、与其他子站的电气距离等因素。其中, 出线数量和与其他子站电气距离较为重要。本文综合考虑这两个因素确定系统中各节点的综合计算值E(i), 目标函数为
| $ \begin{aligned} E(i)=& 0.5 \frac{N_{i}-\min \left(N_{i}\right)}{\max \left(N_{i}\right)-\min \left(N_{i}\right)}+\\ & 0.5 \frac{\max \left(l_{i \Sigma}\right)-l_{i \Sigma}}{\max \left(l_{i \Sigma}\right)-\min \left(l_{i \Sigma}\right)} \end{aligned} $ | (1) |
式中:Ni——子站i的出线数目;
max(Ni), min(Ni)——节点最大和最小出线数目;
li∑——子站i与其他子站的最短通信距离的总和, 各子站之间最短通信距离由Dijkstra算法求得[7];
max(li∑), min(li∑)——所有子站中最短通信距离的最大和最小值。
区域中心主站不能过于集中, 至少要间隔两个变电站的距离。因此, 分区数目选择方法为:首先, 由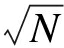 进行估算, N为系统子站数, E(i)计算值最大的前
进行估算, N为系统子站数, E(i)计算值最大的前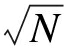 个子站作为有可能的区域中心主站; 然后, 若选出的任意两个子站不满足相隔两个变电站的要求, 删去其中E(i)计算值较小的子站; 最终得出的子站集合就是区域中心主站的集合。
个子站作为有可能的区域中心主站; 然后, 若选出的任意两个子站不满足相隔两个变电站的要求, 删去其中E(i)计算值较小的子站; 最终得出的子站集合就是区域中心主站的集合。
1.2 其余子站划分方法
若中心主站选定为节点m, n, p, q, 则子站i到各中心主站的距离向量为
| $\boldsymbol{S}_{i}=\left\{\begin{array}{llll}l_{i\text {m}} & l_{i\text {n}} & l_{i\text {p}} & l_{i_{\mathrm{q}}}\end{array}\right\}$ | (2) |
于是可构造剩余子站到中心主站的距离矩阵为
| $ \boldsymbol{S}=\left[\begin{array}{cccc} l_{1 \mathrm{m}} & l_{1 \mathrm{n}} & l_{1 \mathrm{p}} & l_{1 \mathrm{q}} \\ \vdots & \vdots & \vdots & \vdots \\ l_{i\mathrm{m}} & l_{i\mathrm{n}} & l_{i\mathrm{p}} & l_{i\mathrm{q}} \\ \vdots & \vdots & \vdots & \vdots \\ l_{(N-M) \mathrm{m}} & l_{(N-M) \mathrm{n}} & l_{(N-M) \mathrm{p}} & l_{(N-M) \mathrm{q}} \end{array}\right] $ | (3) |
该矩阵有(N-M)行, M列。N, M分别是系统所有子站和已经确定的中心主站的数目。通过该矩阵, 把各个中心主站作为基准点, 其余子站到中心主站的距离特征作为该子站的坐标, 可以确定各个子站唯一的位置, 然后对上述距离矩阵用k均值聚类分析算法进行分类, 完成对大电网系统的分区。
2 基于故障序分量的可疑故障线路选取
故障发生时, 系统中各点电气量变化情况有很大差异, 且越靠近故障点其突变量越大。根据这一性质, 可以由各线路电气量变化特征确定较少的可疑故障线路。
首先, 建立子站保护单元的启动判据
| $ \left\{\begin{array}{l} U_{\mathrm{L} 0} \geqslant 0.1 U_{\mathrm{N}} \\ U_{\mathrm{L} 1} \leqslant 0.8 U_{\mathrm{N}} \end{array}\right. $ | (4) |
式中:UL0, UL1——故障时母线零序、正序电压幅值;
UN——系统正常运行时的母线电压幅值。
当系统发生故障时, 将满足启动判据的母线故障分量上传至区域决策中心, 并对所有上传信息进行排序。正序电压按照由小到大进行排序; 零序电压按照由大到小进行排序。考虑到系统结构、线路损耗、互感器误差等因素, 将各序列中排序前两位以及与其相差在10%以内的母线定义为不正常母线, 将不正常母线之间的线路定义为可疑故障线路。
3 DS证据理论及其改进
证据理论的作用是对一系列具有不确定信息或者具有冲突的证据源进行融合决策。利用该算法可有效减轻或者消除错误信息对结果的影响, 提高结果的准确度。
3.1 传统DS证据理论
传统DS证据理论首先定义Θ为辨识框架。如果函数m:2Θ∈[0, 1], ∅为空集, 满足以下两个条件
| $\left\{\begin{array}{l}m(\varnothing)=0 \\ \sum\limits_{A \subseteq \Theta} m(A)=1\end{array}\right.$ | (5) |
则将m(A)称为命题A的基本可信度赋值函数[11]。一个事件有n组独立的证据, 设为m1(A), m2(A), m3(A), …, mn(A)。这n组证据的融合规则为
| $ \begin{array}{l} m(A)= \\ \left\{\begin{array}{l}(1-k)^{-1} \sum\limits_{A_{i}=A} \prod\limits_{1 \leqslant j \leqslant n} m_{j}\left(A_{i}\right) \quad A \neq \varnothing \\ 0 \quad A=\varnothing\end{array}\right. \end{array} $ | (6) |
若mj(Ai) > 0, 则称Ai为焦元。其中,
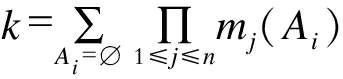 称为证据冲突因子, 表示证据之间冲突程度。当证据之间的冲突较大时, 使用证据理论进行融合将得到不理想甚至完全错误的结果。因此, 目前对证据理论的改进主要集中在对冲突的处理上。
称为证据冲突因子, 表示证据之间冲突程度。当证据之间的冲突较大时, 使用证据理论进行融合将得到不理想甚至完全错误的结果。因此, 目前对证据理论的改进主要集中在对冲突的处理上。
3.2 证据理论的改进
首先, 构造n个证据之间的冲突因子矩阵为
| $ \boldsymbol{k}=\left[\begin{array}{cccc} 0 & k_{12} & \cdots & k_{1 n} \\ \vdots & \vdots & k_{i j} & \vdots \\ k_{n 1} & k_{n 2} & \cdots & 0 \end{array}\right] $ | (7) |
式中:kij——证据i和证据j之间的冲突大小。
累加矩阵k的每一行可以得到证据i与其他证据的总的冲突, 即
| $ k_{i}=\sum\limits_{j=1}^{n} k_{i j} \quad i=1,2,3, \cdots, n $ | (8) |
一般来说, ki越大, 证据越不合理。当某一个证据与其他任意一个证据间冲突≥0.5时, 该证据可定义为不合理证据, 用该证据进行融合有可能会影响证据理论算法的性能, 因此需要对其进行改进。
冲突因子矩阵表示各证据之间的冲突程度, 即各证据间的不包容性。文献[12]提出用相似系数表示证据之间的相似程度, 并定义证据mi和mj之间的相似系数为
| $ S_{i j}=\frac{\sum\limits_{A_{\mathrm{p}} \cap A_{\mathrm{q}}=A \neq \varnothing} m_{i}\left(A_{\mathrm{p}}\right) \times m_{j}\left(A_{\mathrm{q}}\right)}{\sqrt{\left[\sum m_{i}\left(A_{\mathrm{p}}\right)^{2}\right]\left[\sum m_{j}\left(A_{\mathrm{q}}\right)^{2}\right]}} $ | (9) |
对n个证据进行计算得到相似系数矩阵为
| $ \boldsymbol{S}=\left[\begin{array}{cccc} 1 & S_{12} & \cdots & S_{1 n} \\ \vdots & \vdots & S_{i j} & \vdots \\ S_{n 1} & S_{n 2} & \cdots & 1 \end{array}\right] $ | (10) |
累加矩阵S的每一行得到证据i与其他证据的总的相似度为
| $ S_{i}=\sum\limits_{j=1}^{n} S_{i j} \quad i=1,2,3, \cdots, n $ | (11) |
将Si归一化得到证据i的可信程度为
| $ \operatorname{Rel}\left(S_{i}\right)=\frac{S_{i}}{j \sum\limits_{j=1}^{n} S_{i}} $ | (12) |
Rel(Si)的大小表示证据i的可信程度的高低。将Rel(Si)作为证据i的权值, 根据每个证据的权值加权得到一个新的可靠证据
| $\boldsymbol{m}^{\prime}=\left[\begin{array}{llllll}A_{1^{\prime}}, & A_{2^{\prime}} & \cdots & A_{j^{\prime}} & \cdots & A_{m^{\prime}}\end{array}\right]$ | (13) |
其中
| $ A_{j^{\prime}}=\sum\limits_{i=1}^{n} \operatorname{Rel}\left(S_{i}\right) \times m_{i}\left(A_{j}\right) $ | (14) |
用新证据取代证据集合中冲突最大的不合理证据, 然后再对新的集合重复上述计算, 直到没有不合理证据, 最后对新的证据集合进行融合, 找到发生故障的线路。
4 广域后备保护新算法的实现
4.1 广域后备保护方案
基于以上分析, 本文广域后备保护方案可由子站部分和区域决策中心部分共同完成。其基本原理流程如图 1所示。
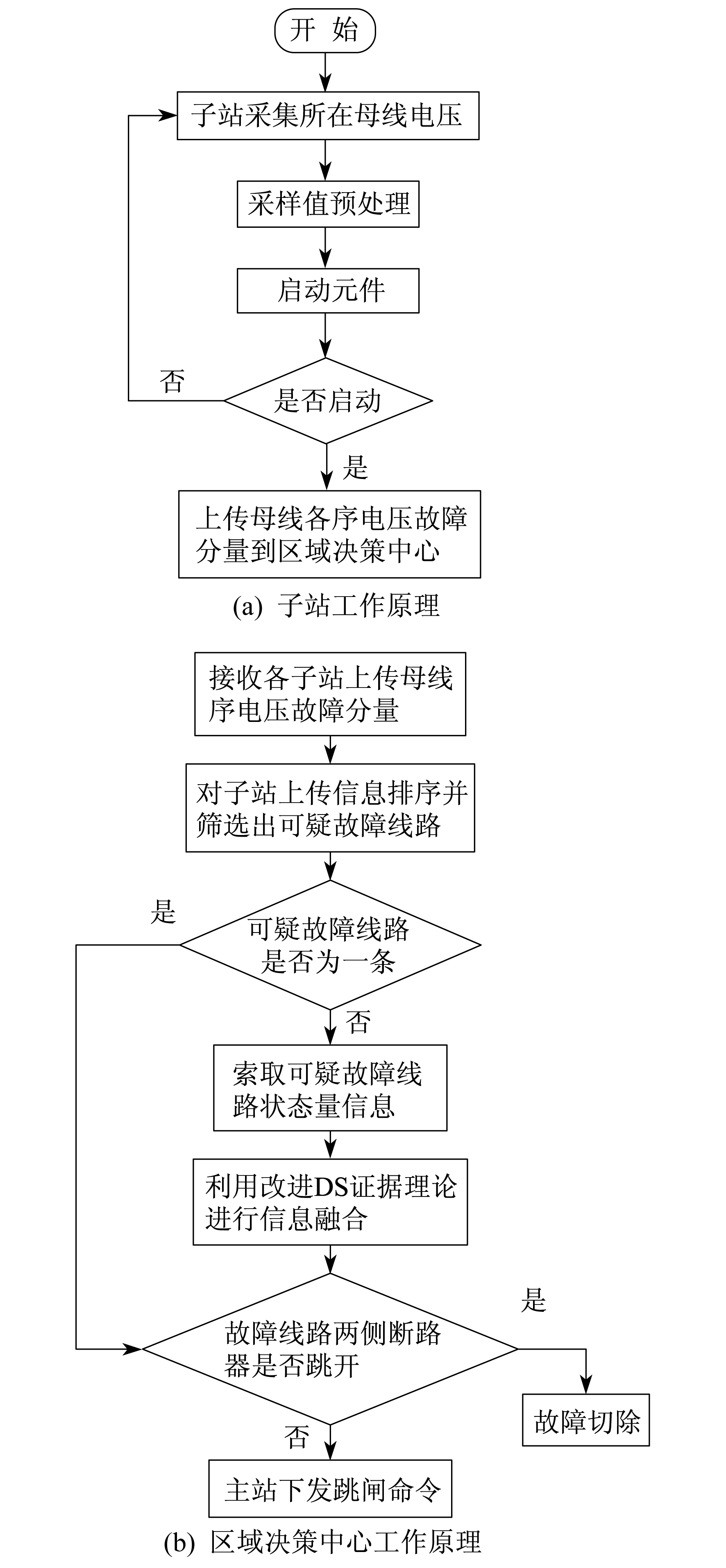

(1) 各子站采集所在母线正、负、零序故障电压分量, 然后将各序故障电压分量与其启动判据进行对比。若启动元件动作, 则上传其信息到区域决策中心; 若启动元件不动作, 则不上传其具体信息。
(2) 区域决策中心接受子站上传的各序电压分量, 并筛选出可疑的线路。若筛选出的可疑线路只有一条, 则该线路即为发生故障的线路; 若可疑线路不只一条, 则索取其传统保护的状态量信息, 然后利用改进DS证据理论进行信息融合找到故障线路。
4.2 基于改进DS证据理论融合的保护策略
4.2.1 原始证据的选择
目前证据理论融合中, 证据的选择一般为各IED中保护的动作状态量。这种方法简单、方便。然而, 各保护的动作状态并不是完全可信的, 当错误的信息较多时, 会发生不能有效识别故障线路的情况。当故障发生时, 相应的各点的电气量也将随之发生突变, 且这种变化不会同传统保护一样存在拒动或者误动的问题。因此, 本文考虑采用电气量和保护动作状态量相结合的方法。
4.2.2 各证据基本概率分配函数
(1) 对于电气量, 分别上传各可疑故障线路两侧母线中IED检测到的故障前两个周期和故障后两个周期的正、负、零序故障电压, 并计算其平均值Ujm, U′jm(j=1, 2, 3, …, 表示IED编号; m=1, 2, 0, 表示正、负、零序)。各IED电压分量突变量为
| $\beta_{j m}=\left|U_{j m}^{\prime}-U_{j m}\right|$ | (15) |
以线路Li两侧两个IED电压分量突变量取平均值作为该线路各分量电压突变量βLi。
由电气量确定的各线路基本概率分配(Basic Probability Assignment, BPA)为
| $ m\left(L_{i}\right)=\frac{\beta_{L_{i}}}{\sum\limits_{i=1}^{j} \beta_{L_{i}}} $ | (16) |
式中:j——可疑故障线路数目。
(2) 对于状态量信息, 由于线路主保护或者距离保护1段都只是保护单一线路, 如果该线路发生故障, 则这两种保护动作, 相应的BPA取值为“1”; 如果无故障, 则这两种保护不动作, 相应BPA取值为“0”。但距离2段保护的长度过长, 因此不能单纯地按照上述方法赋值。文献[11]提出了一种基于保护范围的赋值方法。分别取距离保护1段和2段的范围为线路全长的P1-1和P1-2倍(P1-1通常取值为0.8, P1-2取值为1.4), 则本线路的距离2段BPA取值为xi=(1-P1-1)/(P1-2-P1-1), 下一级线路距离2段BPA取值为1-xi。距离保护2段的BPA分布如表 1所示。
表 1
距离保护2段BPA分布
| 距离保护 情况 |
本线概率分配 | 邻线概率分配 | |||
| 故障 | 正常 | 故障 | 正常 | ||
| 动作 | xi | 1-xi | 1-xi | xi | |
| 未动作 | 0 | 1 | 0 | 1 | |
发生故障时, 由各可疑故障线路的主保护和距离1段、2段动作特征确定保护状态向量为
| $\boldsymbol{q}=\left[\begin{array}{llllll}q_{1} & q_{2} & \cdots & q_{i} & q_{j} & \cdots\end{array}\right]$ | (17) |
由状态量特征所确定的各线路BPA为
| $ m\left(L_{i}\right)=\frac{q_{i}+q_{j}}{\sum\limits_{i=1}^{n} q_{i}} $ | (18) |
式中:qi, qj——可疑故障线路Li两端保护动作状态。
4.3 基于改进DS证据理论的保护策略计算步骤
简单电力系统网络如图 2所示, 假设线路L4发生故障, 经区域主站计算和筛选得到可疑故障线路集合为{L3 L4 L5}, 共3条线路。基于改进证据理论的保护步骤如下。

(1) 计算这3条线路在各种证据下的BPA值, Pi={mi(L3) mi(L4) mi(L5)}。其中i指待融合的证据类型, i=1, 2, 3, …, 6, 分别代表正、负、零序故障电压和主保护、距离保护1段、距离保护2段。
(2) 计算各证据之间的冲突大小并据此建立冲突因子矩阵。若矩阵中所有因子kij < 0.5, 则直接由式(6)进行融合得到最终各线路的BPA值; 反之, 则由上文所述DS证据理论改进方法对不合理证据进行改进优化, 然后进行证据间的信息融合, 得到各线路的BPA值。
(3) 最后取BPA值最大的线路作为故障线路。
5 算例分析
为验证本文提出的基于聚类算法的分区方法和基于电气量与逻辑量相结合的改进证据理论算法的性能, 在PSCAD中搭建IEEE 39节点模型进行测试, IEEE 39节点系统模型及其分区如图 3所示。
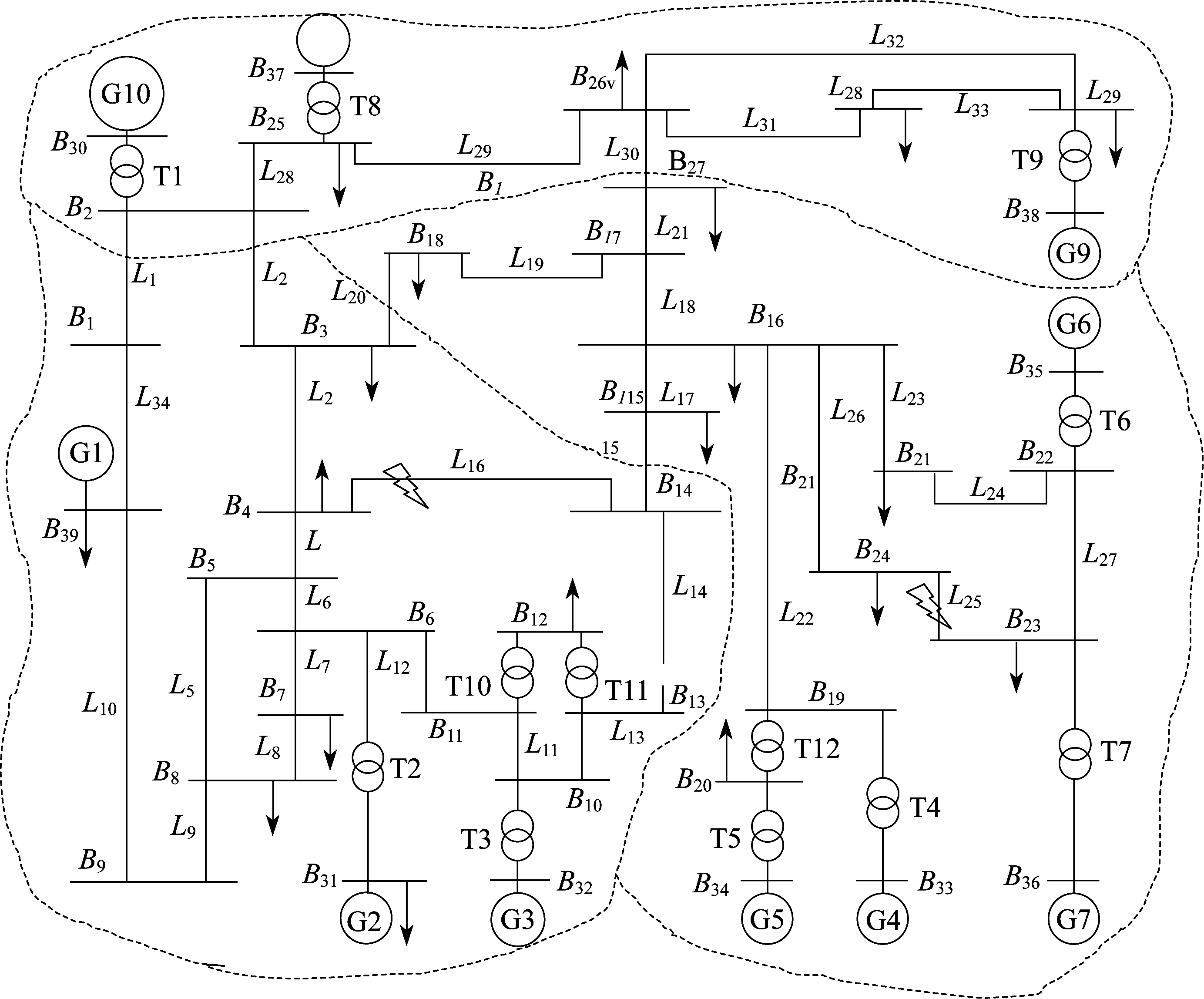
5.1 基于聚类算法的大电网分区
5.2 疑似故障线路的选择
图 3中, 对线路L16和线路L25分别设置故障进行分析, 故障F1故障点设置为距离母线B4侧40%处, F2故障点设置为线路L25中心点。然后按照本文方法确定可疑故障线路。最终所得结果如表 3所示。
表 3
不同故障类型下疑似故障线路
| 故障类型 | 可疑故障母线/可疑故障线路 | |
| F1 | F2 | |
| AG | B4, B14 / L16 | B23, B24/L25 |
| AG(100 Ω) | B4, B5, B14, B13/L4, L16, L14 | B22, B23, B24 /L25, L27 |
| AB | B4, B14 / L16 | B23, B24 / L25 |
| ABG(0 Ω) | B4, B14 / L16 | B23, B24 / L25 |
| ABG (100 Ω) |
B4, B5, B14, B13/L4, L16, L14 | B22, B23, B24 /L25, L27 |
| ABCG | B4, B14 / L16 | B23, B24 / L25 |
由表 3可以看出:当发生直接接地故障或者相间短路时, 确定的可疑故障线路都只有一条, 该线路即为故障线路; 当发生经高阻接地故障时, 由于接地电阻的存在, 会使各序故障电压突变量减小, 此时可疑故障线路数目不止一条, 但可疑故障线路集合中必包含实际的故障线路。因此, 由本文提出的可疑故障线路方法可有效检测出故障线路, 并大幅降低上传信息量。
5.3 IED信息有误时算法性能的检验
以F1发生单相接地故障, 接地电阻为100 Ω为例, 检验本文算法在保护误动及拒动时的性能。
5.3.1 IED拒动时
5.3.2 IED误动时
正常情况下, 线路L14, L4两端主保护、距离1段、距离保护2段不该动作, 共12个保护信息。当分别发生1~12个保护误动时, 融合结果如表 5所示。
表 5
保护误动时融合结果
| 线路 | 保护拒动个数 | |||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| L16 | 1 | 0.93 | 0.92 | 0.90 | 0.84 | 0.82 | 0.73 | 0.70 | 0.66 | 0.62 | 0.56 | 0.51 |
| L14 | 0 | 0.07 | 0.08 | 0.08 | 0.13 | 0.13 | 0.23 | 0.23 | 0.25 | 0.26 | 0.30 | 0.31 |
| L3 | 0 | 0 | 0 | 0.02 | 0.03 | 0.05 | 0.04 | 0.07 | 0.09 | 0.12 | 0.14 | 0.18 |
| 故障线路 | L16 | L16 | L16 | L16 | L16 | L16 | L16 | L16 | L16 | L16 | L16 | L16 |
由表 5可以看出, 当IED信息全部或者部分误动时, 本文的算法都能做到正确有效地判别出故障的线路。
结合表 4和表 5可以看出, 无论IED拒动或者误动, 该算法均有较高的可靠性, 因此对于常见的IED拒动或者误动问题, 该算法有极高的容错性。
6 结论
本文将保护动作逻辑量和电气量相结合共同作为证据源, 并对不合理证据进行迭代优化; 同时, 基于电网中各子站之间的电气距离特征, 使用k均值聚类分析算法完成电网的分区工作。其具有以下优点:
(1) 基于k均值聚类分析算法的大电网分区算法简便易行, 且分区合理;
(2) 采用序电压故障分量作为标准来选取可疑故障线路, 对于对称故障和不对称故障, 均能有效选出可疑故障线路, 减少上传信息量;
(3) 将电气量和保护动作逻辑量共同作为证据源, 并对不合理的证据进行优化迭代, 有效提高了算法的容错性能。
参考文献
-
[1]时空协调的大停电防御框架: (一)从孤立防线到综合防御[J]. 电力系统自动化, 2006, 30(1): 1-9. DOI:10.3321/j.issn:1000-1026.2006.01.001
-
[2]防止距离Ⅲ段保护因过负荷误动方法的分析与改进[J]. 电力系统保护与控制, 2015, 43(7): 1-7. DOI:10.7667/j.issn.1674-3415.2015.07.001
-
[3]基于广域保护系统的距离后备保护整定方案[J]. 电力系统保护与控制, 2016, 44(1): 40-47. DOI:10.7667/j.issn.1674-3415.2016.01.006
-
[4]广域继电保护系统研究综述[J]. 电力系统保护与控制, 2012, 40(1): 145-155. DOI:10.3969/j.issn.1674-3415.2012.01.025
-
[5]电力系统广域保护与控制技术[J]. 电网技术, 2006, 30(8): 7-14. DOI:10.3321/j.issn:1000-3673.2006.08.002
-
[6]基于区域多信息融合的广域后备保护算法[J]. 电力系统保护与控制, 2017, 45(4): 26-32. DOI:10.7667/PSPC160328
-
[7]集中决策式广域后备保护的分区模型与优化算法[J]. 电工技术学报, 2014, 29(4): 212-219. DOI:10.3969/j.issn.1000-6753.2014.04.028
-
[8]有限广域继电保护系统的分区原则与实现方法[J]. 电力系统自动化, 2010, 34(19): 48-52.
-
[9]基于序电流相位比较和幅值比较的广域后备保护方法[J]. 电工技术学报, 2013, 28(1): 242-250. DOI:10.3969/j.issn.1000-6753.2013.01.034
-
[10]基于故障电压比较与多信息融合的广域后备保护算法[J]. 电力系统保护与控制, 2015, 43(22): 92-98. DOI:10.7667/j.issn.1674-3415.2015.22.014
-
[11]基于区域多信息融合的广域后备保护算法[J]. 电力系统保护与控制, 2017, 45(4): 26-32. DOI:10.7667/PSPC160328
-
[12]基于证据可信度的D-S理论协作频谱感知方法[J]. 计算机测量与控制, 2016, 24(12): 209-212.


