|
|
|
发布时间: 2019-08-10 |
|
|
|
|


|
收稿日期: 2018-12-17
中图法分类号: TP399
文献标识码: A
文章编号: 1006-4729(2019)04-0399-05
|
摘要
提出了一种基于强化学习的云计算虚拟机资源调度问题的解决方案和策略。构建了虚拟机的动态负载调度模型, 将虚拟机资源调度问题描述为马尔可夫决策过程。根据虚拟机系统调度模型构建状态空间和虚拟机数量增减空间, 并设计了动作的奖励函数。采用Q值强化学习机制, 实现了虚拟机资源调度策略。在云平台的虚拟机模型中, 对按需增减虚拟机数量和虚拟机动态迁移两种场景下的学习调度策略进行了仿真, 验证了该方法的有效性。
关键词
云计算; 虚拟机; 强化学习; 控制策略
Abstract
A solution to cloud computing resource scheduling problem based on reinforcement learning is proposed.The dynamic load scheduling model of the virtual machine is constructed, and the virtual machine resource scheduling problem is described as the Markov decision process.According to the virtual machine system scheduling model, the state space and the number of virtual machines are increased or decreased, and the reward function of the action is designed.The Q-valued reinforcement learning mechanism is used to implement the virtual machine resource scheduling strategy.Finally, in the virtual machine model of the cloud platform, the performance of the learning and scheduling strategy is enhanced under the scenarios of increasing or decreasing the number of virtual machines and virtual machine dynamic migration.The effectiveness of the method is verified.
Key words
cloud computing; virtual machine; reinforcement learning; control strategy
云计算是一种新兴的领先信息技术, 云计算是在“云”上分配计算任务, 通过专用软件实现的自动化管理使用户能够按需访问计算能力、存储空间和信息服务, 用户可以专注于自己的业务, 无需考虑复杂的技术细节, 有助于提高效率、降低成本和技术创新。
云计算研究的关键技术有:虚拟化技术、数据存储技术、资源管理技术、能源管理技术、云监控技术等。其中, 系统资源调度是云计算中的关键问题之一。然而, 由于云计算平台上应用程序的多样性和用户负载的动态变化, 可能发生节点之间负载不平衡的问题, 一些节点负载不足、资源不足, 而另一些节点负载闲置空闲, 极大地影响了云计算系统的整体性能。此外, 随着云计算资源规模的扩大, 资源集群的人工或手动管理变得非常不现实。因此, 如何通过适当的算法自动协调服务器之间的负载, 以提升云计算平台的资源利用率已成为云计算领域迫切需要解决的问题[1-3]。
与传统的虚拟机资源调度策略算法不同, 强化学习(Reinforcement Learning, RL)算法是一种无模型调度方法, 不需要系统的先验知识和模型。该算法通过设定马尔可夫决策模型, 定义强化模型中的智能体(Agent)和环境(Environment), 通过使智能体与环境交互学习, 获得系统的模型和动态特性。交互过程中, 通过设定奖励(Reward)和惩罚(Punishment)来约束智能体的行为, 并通过最大化累计奖赏获得最优控制策略[4]。文献[5-6]研究了强化学习和动态规划模型在云计算资源管理中的应用, 以云计算虚拟资源的配置问题为学习对象, 从控制规划的角度进行了研究。文献[6]着重于每个虚拟机的计算资源分配, 并将其作为学习对象, 构建了分布式虚拟机资源自动配置系统。但是, 该方法仅从每个虚拟机资源启动, 忽略了虚拟集群的整体资源性能。
本文针对具有用户负载动态的云计算虚拟机资源调度问题, 设计了一种基于Q值强化学习的云计算虚拟机资源调度方法。将系统虚拟机的配置管理过程描述为马尔可夫决策过程(Markov Decision Process, MDP), 并根据系统中的运行状态和输入负载的动态变化引入Q值强化学习机制。智能体通过与服务器虚拟机资源环境的持续交互来获得最佳虚拟机调度策略。最后, 本文以按需增减虚拟机数量和虚拟机动态迁移两种场景为例, 进行了仿真研究, 并分析了不同场景下强化学习的性能。
1 虚拟机资源调度决策模型
1.1 虚拟机调度结构
本文研究的云计算虚拟机资源调度模型由用户服务器、监视器、调度器和虚拟机资源池等组成。虚拟机资源调度结构如图 1所示。其中, 调度程序自动将虚拟机的决策模块配置为强化学习的智能体结构, 发挥虚拟机的资源决策调度作用。根据动态负载平衡, 当用户负载与所需虚拟机服务器不匹配时, 虚拟机调度策略将通过控制器调节相应节点的虚拟机个数, 以达到用户负载平衡。
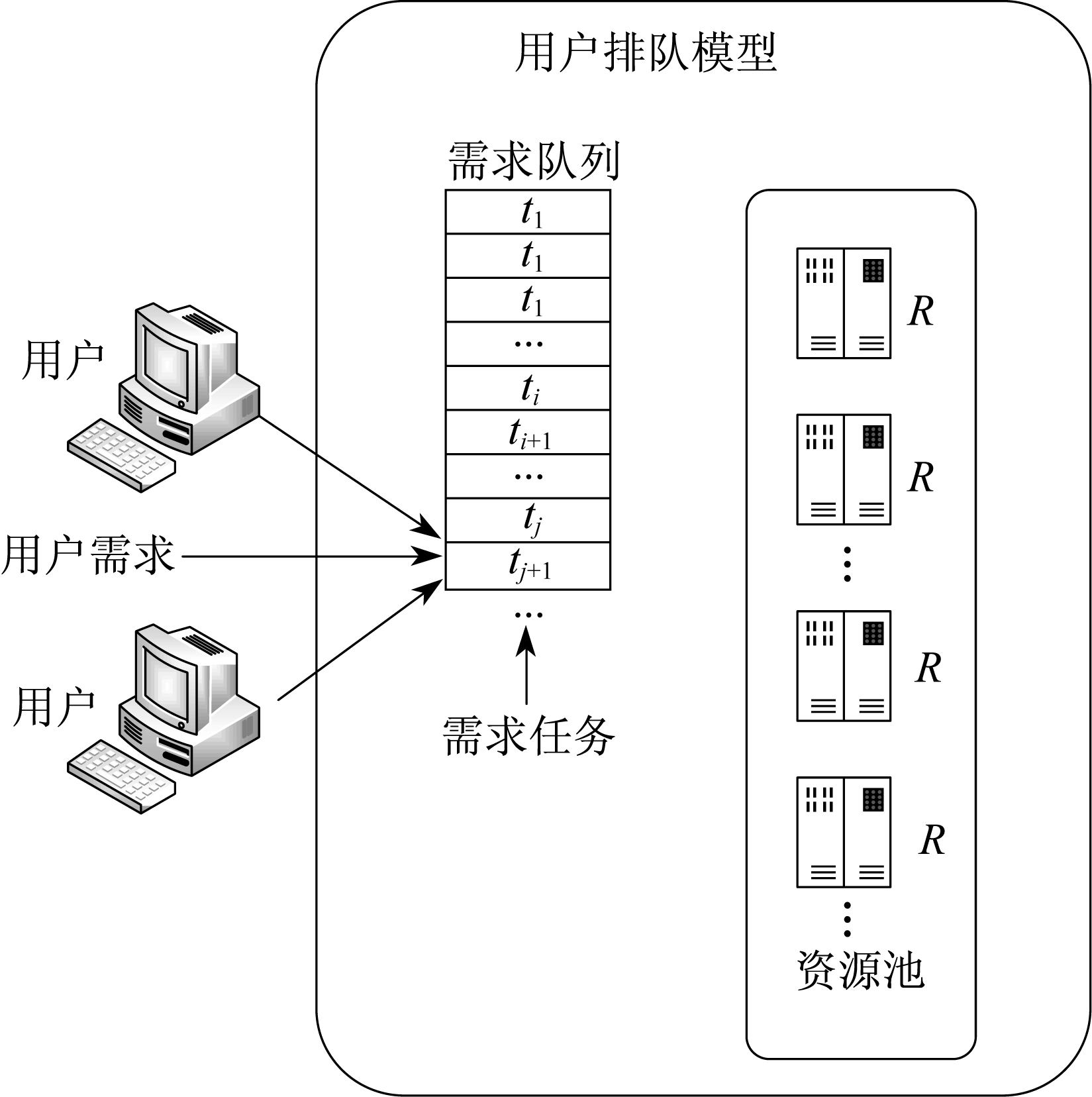

1.2 虚拟机决策模型
强化学习方法侧重于学习解决问题的策略。与一般机器学习方法相比, 强化学习算法更注重与环境的交互。本文构建的强化学习智能体将虚拟机资源调度问题转化为有限时间序列的马尔可夫决策过程, 智能体观测量为数据提取的特征。
马尔可夫决策过程具有马尔可夫性, 同时考虑动作和奖励的影响。基于马尔可夫决策过程, 本文定义了虚拟机调度策略问题, 在每个时间步长上, 智能体观测量包含强化学习中的状态st, 动作at和奖励函数rt。系统在当前状态st下采取动作at并通过P函数转移到下一状态st+1, 即
| $s_{t+1}=P\left(s_{t}, a_{t}\right), \forall t \in\{0,1,2, \cdots, T-1\}$ | (1) |
奖励函数rt与状态转移函数ρ相关联, 可表示为
| $r_{t}=\rho\left(s_{t}, a_{t}, s_{t+1}\right), \forall t \in\{0,1,2, \cdots, T-1\}$ | (2) |
本文研究的问题是寻找最优策略h*, 使得整个优化范围内获得的奖励Gt最大。Gt的表达式为
| $ G_{t}=-\sum\limits_{i=0}^{T-1} \gamma^{t} r_{t} $ | (3) |
式中:γ——折扣因子, 根据未来奖励在学习中的重要性而设定, γ∈[0, 1]。
当智能体采用策略h时, 累计回报服从一个分布, 累计回报在状态s处的期望值定义为状态-动作值函数Qh(s, a)。
| $ Q_{h}(s, a)=E_{h}\left(\sum\limits_{t=0}^{T-1} \gamma^{t} r_{t} \mid s_{t}=s, a_{t}=a\right) $ | (4) |
定义最优Q值函数为Q*(所有策略中最大的状态-动作效用值函数), 即
| $ Q^{*}(s, a)=\max\limits_{h} Q_{h}(s, a) $ | (5) |
若已知Q*, 则最优策略h*可通过直接最大化Q*(s, a)来确定, 即
| $h^{*}(a \mid s)=\underset{a \in A}{\arg \;\max } Q^{*}(s, a)$ | (6) |
2 虚拟机调度策略的实现
2.1 深度Q值强化学习过程
虚拟机资源调度问题的学习目标是通过使用调度系统模块的时间序列来添加或删除虚拟机作为决策变量, 利用智能体的反馈信号, 不断与环境互动, 调整和改善智能决策行为从而获得最佳调度策略。
文献[5-6]将强化学习引入到云计算虚拟资源的配置中, 文献[7-10]将强化学习引入到实际应用场景的综合研究中。本文采用深度Q值学习算法来解决虚拟机资源自动配置决策问题, 即通过当前云计算应用系统中的运行状态, 调度决策模块, 并根据特定标准从动作空间中选择最优动作, 以改善系统的状态和处理能力。对于Q值函数解, 即最优策略求解问题, 通常使用诸如神经网络的非线性函数逼近器来近似值函数或策略。
深度Q值强化学习算法使用的是双重Q值网络结构。图 2为双重Q值网络的培训流程图, 介绍了系统模型培训过程。由于双重Q值网络将动作选择和动作评估用不同的值函数来实现, 因此双重Q值网络解决了值函数的过估计问题, 如图 2所示。
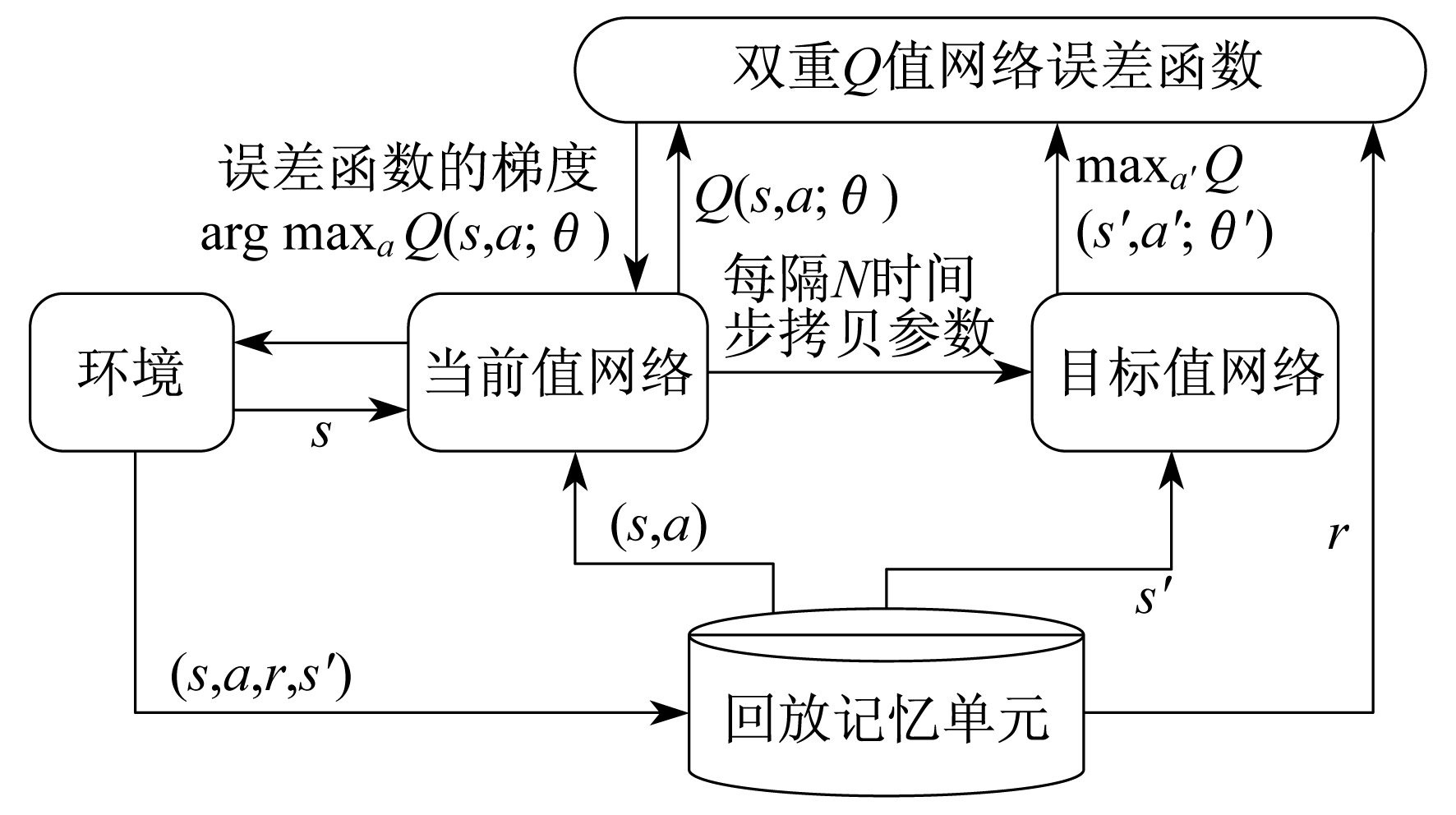
在值函数更新中, 目标值可以表示为
| $ Y_{t}^{\text {Double } Q}=R_{t+1}+\gamma Q\left(s_{t+1}, a^{*} ; \theta^{-}\right) $ | (7) |
当前值网络的参数θ是实时更新的, 每经过N轮迭代, 即可将当前值网络的参数复制给目标值网络。通过最小化当前Q值和目标Q值之间的均方误差来更新网络参数。误差函数θt为
| $ \theta_{t}=E_{\text {rror }}\left[\left(Y_{t}^{\text {Duble } Q}-Q\left(s, a ; \theta_{t}\right)\right)^{2}\right] $ | (8) |
强化学习过程中, Q值学习算法采用随机梯度下降法不断修正网络参数, 使网络计算的Q值不断接近目标值。最后, 更新动作值网络参数为
| $\begin{aligned} \theta_{t+1}=& \theta_{t}+\omega_{i}\left(Y_{t}^{\text {Double } Q}-\right.\\ &Q(s, a ; \theta)) \nabla_{\theta} Q(s, a ; \theta) \end{aligned}$ | (9) |
2.2 马尔可夫决策过程元组描述
2.2.1 状态空间
2.2.2 动作空间
2.2.3 奖励函数
由强化学习中的奖励函数可以立即得到动作和环境的优劣评估值。它是一种即时奖励函数[11]。在应用系统添加或删除虚拟机后, 虚拟机资源的系统状态(例如CPU, 内存和带宽利用率)会相应地发生变化。此时, 若增加应用系统的处理能力, 则可以满足云计算应用提供商所需的系统处理要求, 还可以满足用户的实时加载请求, 并设置较大的正奖励值; 反之, 经过调整后, 产生了负荷损失, 可设定为负的惩罚值。
| $r_{t}=r\left(a_{t}, d_{t}\right)=r^{+}\left(a_{t}, d_{t}\right)+r^{-}\left(a_{t}, d_{t}\right)$ | (11) |
式中:at——动作加值;
dt——负荷需求;
r+(at, dt)——满足用户负荷需求的奖励;
r-(at, dt)——不能满足负荷需求的惩罚。
令δt=at-dt, 当δt < 0时, r-(at, dt)=kδt。
即时奖励模型针对的是一个时间点信息做出的评价, 无法说明整体策略的好坏。因此, 需要定义状态-动作值函数来表征策略对于状态的长期效果。
| $ Q_{h}(s, a)=E_{h}\left(\sum\limits_{t=0}^{T-1} \gamma^{t} r_{t} \mid s_{t}=s, a_{t}=a\right) $ | (12) |
Q值函数是强化学习的学习目标, 选择的最优策略就是基于最大Q值的策略。
| $ h^{*}(a \mid s)=\underset{a \in A}{\arg \;\max } \;Q^{*}(s, a) $ | (13) |
3 仿真试验和分析
3.1 仿真试验
在电力系统云计算平台基础设施中, 服务器、存储和网络资源通过虚拟化形成了庞大的资源池。分布式算法通过分配资源, 消除了物理边界, 提高了资源利用率, 并统一了资源池分配。在实施云计算基础设施的过程中, 资源池的构建尤为重要, 将有助于实现云计算的最终目标——按需动态分配资源[11-12]。
本文以国家电网公司上海数据中心开展的“云平台”系统为例, 进行仿真分析, 采集的历史数据为小时级云平台服务器节点处的用户负荷量和剩余虚拟机数量, 如图 3所示。图 3中, 动作值线表示控制虚拟机数量的最优控制策略。试验结果表明, 强化学习算法提升了云平台虚拟机系统的资源使用率, 降低了云平台虚拟机系统的整体运维成本。
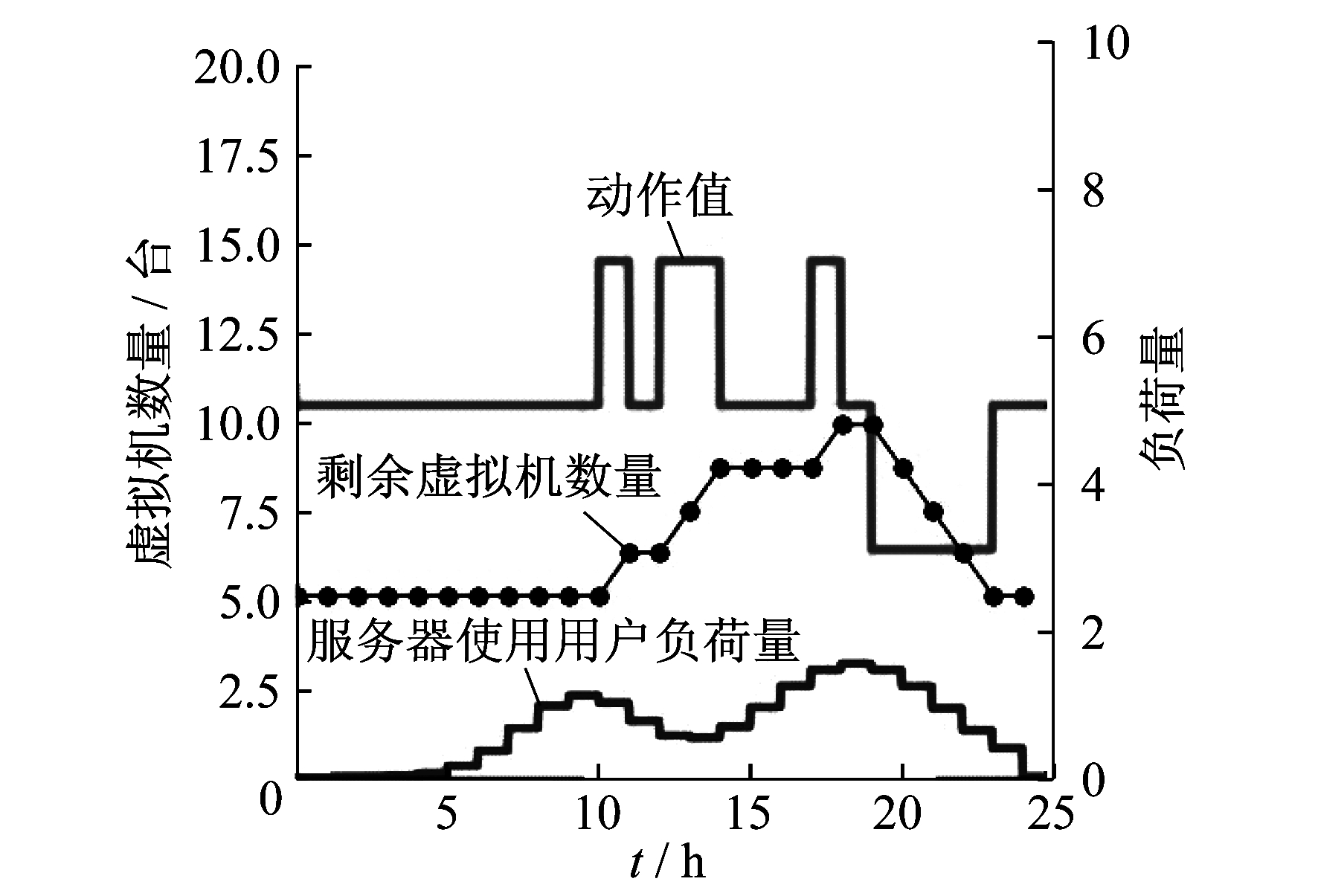
强化学习算法中, 学习率初始值设为0.000 5, 折扣因子初始值设为0.9, 贪婪策略概率ε初始值设为1。智能体通过增加折扣因子、减小学习率, 以获得更好的学习表现。
通过调度策略仿真结果可知:对于不同的用户负荷使用初始值, 服务器都能有效工作; 在负荷消耗量没有或较少时, 虚拟机的个数能够满足负荷需求, 虚拟机配置保持空闲; 当负载较多时, 开始增加虚拟机个数, 为后面的负荷消耗提供保障; 智能体观测量的有效信息有所增加, 使得智能体可以更加准确地选择动作, 从而使系统更有效地增减虚拟机个数, 提高调度策略的性能。因此, 智能体观测的有效信息越多, 则强化学习调度策略的性能越好。
4 结语
在深度强化学习机制的基础上, 提出了云计算虚拟机资源调度策略, 提取了有效特征, 构建了强化学习模型, 实现了云计算虚拟机资源的调度。首先, 以云计算虚拟机资源为环境信息, 以增减虚拟机为动作, 以状态环境收益奖励和动作奖励为奖励函数, 构建了强化学习模型; 然后, 提取输入数据的特征, 使用Q值强化学习算法计算Q值, 得到最优的虚拟机调度策略。试验结果表明, 在不同环境状态下, 强化学习算法都能充分发挥模型的自主性, 主动学习环境信息, 调整自身参数和网络结构, 获得较好的控制策略。
参考文献
-
[1]施杨斌.云计算环境下一种基于虚拟机动态迁移的负载均衡算法[D].上海: 复旦大学, 2011.
-
[2]SINGH A, KORUPOLU M, MOHAPATRA D. Server-storage virtualization: integration and load balancing in data centers.[C]//International Conference for High Performance Computing, Networking, Storage & Analysis, 2008: 1-12.
-
[3]基于云计算平台的移动IPTV系统设计及负载均衡技术研究[J]. 软件, 2011, 32(1): 46-53. DOI:10.3969/j.issn.1003-6970.2011.01.012
-
[4]深度强化学习综述[J]. 计算机学报, 2018(1): 1-27. DOI:10.11897/SP.J.1016.2019.00001
-
[5]TSOUMAKOS D, KONSTANTINOU I, BOUMPOUKA C, et al. Automated, elastic resource provisioning for NoSQL clusters using TIRAMOLA[C]//Ieee/acm International Symposium on Cluster, Cloud and Grid Computing. IEEE, 2013: 34-41.
-
[6]RAO J, BU X, XU C Z, et al. A distributed self-learning approach for elastic provisioning of virtualized cloud resources[C]//IEEE, International Symposium on Modeling, Analysis & Simulation of Computer and Telecommunication Systems. IEEE, 2011: 45-54.
-
[7]TESAURO G, JONG N K, DAS R, et al. Improvement of systems management policies using hybrid reinforcement learning[C]//European Conference on Machine Learning: ECML 2006. Heidelberg: Springer Berlin, 2006: 783-791.
-
[8]SONG X, ZHANG Q, SEKIMOTO Y, et al. Modeling and probabilistic reasoning of population evacuation during large-scale disaster[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2013: 1231-1239.
-
[9]基于逆向强化学习的舰载机甲板调度优化方案生成方法[J]. 国防科技大学学报, 2013, 35(4): 171-175. DOI:10.3969/j.issn.1001-2486.2013.04.030
-
[10]基于马氏决策过程模型的动态系统学习控制:研究前沿与展望[J]. 自动化学报, 2012, 38(5): 673-687.
-
[11]国产数字电液控制系统应用现状分析[J]. 上海电力学院学报, 2007, 23(2): 147-150.
-
[12]地面无线测控网在电力巡检中的应用[J]. 上海电力学院学报, 2009, 25(1): 4-6.


