|
|
|
发布时间: 2020-08-30 |
|
|
|
|


|
收稿日期: 2020-03-18
基金项目: 上海市自然科学基金(19ZR1420800)
中图法分类号: TP391.1
文献标识码: A
文章编号: 2096-8299(2020)04-0320-09
|
摘要
介绍了文本词向量及预训练语言模型的发展体系,系统整理并分析了其中重点方法的思想特点。首先,阐述了传统的文本词向量表征方法及基于语言模型的文本表征方法;然后,详述了预训练语言模型方法的研究进展,包括动态词向量的表征方法和基于Transformer架构的预训练模型;最后,指出了未来探究多模态间更有效的融合方式和迁移学习将成为该领域的发展趋势。
关键词
文本信息处理; 词向量; 预训练语言模型; Transformer架构
Abstract
This paper mainly introduces the development system of text word vectors and pre-trained language models, systematically organizes and analyzes the ideological characteristics of key methods.Firstly, we describe the traditional text word vector representation method and the language model-based text representation method, then we elaborate the research progress of the pre-trained language model method, including the dynamic word vector representation method and the Transformer architecture-based pre-training model.Finally, it is pointed out that in the future, exploring more effective fusion methods and transfer learning between multi-modalities will become a development trend in this field.
Key words
text information processing; word vector; pre-trained language model; Transformer architecture
自然语言是经人类抽象发展而来的数据, 含有丰富的语义信息, 计算机无法直接识别。因此, 自然语言处理的首要步骤就是将文本等非结构化的字符数据进行字词编码, 转换为可计算的数值数据, 从而确定文本和数字空间的对应关系。
文本向量化应当尽可能地包含原空间信息, 若在空间映射时丢失部分信息, 那么后续的处理任务中也不可能再重新获取。最早的研究方法是将文本划分为独立的单词, 每个单词被表示为词汇表中的一个索引, 或单词对应的索引位置为1, 其余为0的独热编码向量。该方法虽然简单, 但单词间无相似性, 且没有联系, 也不包含任何语义信息。另外, 独热编码是稀疏向量, 易造成维数灾难。针对以上问题, 有人提出了词的分布式表示法——词向量。词向量是一个维度较低且稠密的向量, 每个维度上都有实数。在词向量与神经网络结合后, 便广泛地应用于自然语言处理中, 例如命名实体识别、实体抽取、阅读理解和机器问答等。
在利用词向量解决了数据稀疏和计算复杂的问题后, 研究人员开始运用词向量进行自然语言处理的预训练。自然语言处理领域的预训练是受到图像处理领域预训练的启发, 目前已成为自然语言处理领域的热门研究方向。一般在开始训练模型时需要随机初始化参数, 但是存在两个方面的问题:一是如果训练的数据集不够大, 则有可能不足以训练复杂的网络; 二是模型随机初始化参数会使训练速度变慢, 即收敛速度变慢。基于上述问题, 预训练的概念应运而生。预训练模型的初始化参数是预先给定的, 从而使得模型在训练时可以找到较好的初始点, 进而加速优化过程。
1 词向量的发展
词向量分为静态词向量和动态(上下文)词向量。静态词向量是指无论上下文怎样变化只有唯一的词向量可以表示一个单词, 其最大的弊端是无法表达出该词汇的多义性; 而动态词向量指的是会根据上下文动态调整的词向量, 在一定程度上解决了单词的多义性。一般来说, 动态词向量可归类为预训练模型, 如ELMo(Embedding from Language Models), BERT(Bidirectional Encoder Representations from Transformers)模型等。
词向量生成技术就是将自然语言表示的单词转换成计算机能够理解的向量, 其表示方法包含了传统的表征方法和基于语言模型的表征方法。
1.1 传统的词向量表征方法
词袋模型是将文档表示成一个无序词汇的组合。最早的词向量表征采用的是“one - hot”编码, 是一种特殊的高维度到低纬度的映射。首先对语料库所有文档中的句子进行拆分, 并汇总得到包含所有词汇的词库[1], 假设总词汇有N个, 文档中每个词的向量都是n维, 若某词汇出现在该文档中, 则出现的维度标为1, 其余维度标为0。采用基于词频的方法统计当前文档中词汇出现的次数, 用词频作向量值。
文档-逆文档频率(Term Frequency - Inverse Document Frequency, TF - IDF)方法是用词汇的特征来表示文本的重要性[2], 用词汇的频率与逆文档频率的比值作为向量值[3]。其计算公式为
| $ {t_{{i_{p, q}}}} = {t_{p, q}}{i_{p, q}} = t\frac{{{\rm{ }}{n_{pq}}}}{{\sum\limits_{p = 1}^k {{n_{pq}}} }} \times {\rm{ }}\frac{{\left| {{D_p}} \right|}}{{\left| {{d_{p, q}}} \right|}} $ | (1) |
式中:
词袋模型生成的向量维度与语料库的大小相关, 当词汇数量很大时, 容易导致维数灾难, 且生成的向量极其稀疏, 计算时无法通过向量建立起词汇语义间的联系和词汇间语义上的相似度, 缺失了文本的顺序信息和语义信息[4]。潜在语义分析模型认为如果两个词汇多次出现在同一文本中, 那么这两个词汇的语义是相似的。其方法是构建词-文档共现矩阵, 行表示词汇, 列表示文本, 当前词在文本中出现的次数就是矩阵的值。对矩阵进行奇异值分解, 减少行数, 保留列信息, 选取前几个最大奇异值对应的向量作为降维后的文本向量表征。
1.2 基于语言模型的表征方法
语言模型(Language Model)是机器理解人类语言的途径, 是用来计算一个语句的概率的模型, 即
| $ \begin{array}{l} P{\rm{ }}({w_1}, {w_2}, {w_3}, \ldots , {w_n}) = \\ \;\;\;\;\;P({w_1})P({w_2}|{w_1})P({w_3}|{w_1}, {w_2}) \ldots \\ \;\;\;\;\;P({w_n}|{w_1}, {w_2}, {w_3}, \ldots , {w_{n-1}}) \end{array} $ | (2) |
| $ L = \sum\limits_{w \in C} {{\rm{log}}P(w\;|\;{\rm{context}}\left( w \right))} {\rm{ }} $ | (3) |
式中:
利用语言模型可以确定哪个词汇序列的可能性更大, 或者利用给定的若干个词来预测下一个最有可能出现的词汇。随着神经网络的发展, 学者们通过浅层神经网络实现的语言模型来获取词向量。语言表示模型的首次提出是在2003年, BENGIO Y等人[5]提出用神经网络建立概率语言模型(Neural Network Language Model, NNLM), 首先将词表示成词汇表中的一个索引, 通过映射矩阵将其转换为D维的向量, 即词向量, 然后将多个上文词汇的词向量串联起来, 通过3层的神经网络模型结合softmax函数层来不断地训练词向量; 但此模型只能处理定长的数据, 当词汇表过大时模型复杂度倍增, 训练缓慢。针对NNLM存在的问题, MIKOLOV T等人[6-7]在2010年提出了循环神经网络概率语言模型(Recurrent Neural Network Language Model, RNNLM), 在结构上, 运用循环神经网络(Recurrent Neural Network, RNN)代替NNLM中的隐藏层, 不仅减少了模型参数、提高了训练速度, 而且可以提供任意长度的输入, 并获得完整的历史信息; 同时, 引入RNN后也可以使用RNN的其他变体, 如长短期记忆神经网络(Long Short-Term Memory, LSTM)、双向长短期记忆神经网络(Bi-directional Long Short-Term Memory, BiLSTM)、门控循环单元(Gated Recurrent Unit, GRU)等, 从而在时间序列建模上进行更丰富的优化。
1.2.1 Word2vec模型
2013年, MIKOLOV T等人提出了Word2vec模型[8-9], 是一种分布式表示。这种表示方法的思想最早是由HINTON G E于1986年提出的[10]。此模型会对词汇间和词汇语义关系进行建模, 可以将文本中的词汇映射到一个N维的空间中, 从而将对文本的处理转换成为对N维实数向量的运算。该模型一经发布就受到国内外众多学者的关注, 被广泛运用于文本分类、聚类、标注和词性分析等任务中[11]。文献[12]使用Word2vec模型将维基百科中文数据转化为词向量并进行聚类, 将聚类的结果应用到TextRank的关键词抽取中, 提升了抽取效果。文献[13]将微博和新闻文本经Word2vec模型训练得到词向量, 并用K - means聚类抽取评论及新闻话题。文献[14]将用户的评论文本转化为词向量表示, 并对候选属性词集进行聚类, 最终得到细粒度的产品属性集。文献[15]挖掘了推特用户个人资料的文本集, 经向量化后聚类, 并提出了一种利用机器学习的方法探查用户的社会角色。文献[16]用BiLSTM取代Word2vec模型中的词向量矩阵, 并用BiLSTM对上下文进行编码, 从而获得词向量的表示。
Word2vec模型是从海量文本语料库中获取文本嵌入的模型, 对分词后的文本进行特征表示, 文本中的单词能快速便捷地映射成低维向量。文本集合组成词向量空间, 向量空间中词汇的位置代表了词汇的语义在空间中的位置, 两个词向量之间的距离可以用来计算对应词汇的语义相似度, 距离相近的词汇间可以称作词义相近。Word2vec模型采用了两种计算模型, 分别是连续词袋模型(Continuous Bag-of-Word, CBOW)和跳字模型(Skip-gram)。其中, CBOW输入的是词汇w的上下文context(w), 输出是关于当前词是某个词的概率, 即CBOW是从上下文到当前词的某种映射或预测。Skip-gram则相反, 是从当前词预测上下文, 模型的输入是某个词语w, 输出是语料库词表中每个词的概率。
1.2.2 GloVe模型
GloVe模型是由PENNINGTON J等人[17]在2014年提出的, 结合了语言模型与词共现矩阵的模型。首先, 根据语料库构建共现矩阵, 计算词向量与共现矩阵之间的近似关系; 然后, 根据近似关系构造出损失函数, 并用语言模型进行训练以获得词向量。该模型克服了Word2vec模型只关注上下文局部信息的缺点, 在利用上下文信息的同时, 通过矩阵奇异值分解方法使用了词汇共现的信息, 有效地结合了全局的统计信息和局部上下文信息。
2 预训练语言模型的发展
2.1 动态词向量表征方法
将静态词向量作为参数进行学习的方法有效地解决了维数灾难和计算量大的问题, 但仍存在一词多义的问题。解决该问题的关键在于如何有效利用上下文语境信息, 即输入的不再是单独的某个词汇, 而应包含该词所处的上下文信息, 然后再获得该词在当前语境下的向量表示。这是一种动态的词向量表征方法, 此时词向量不再是静态的模型参数, 而是动态的模型输出。ELMo[18]、生成式预训练(Generative Pre-Training, GPT)模型[19]、BERT模型[20]都是动态词向量表征方法。在特征提取时, ELMo使用双向LSTM网络; GPT模型和BERT模型使用Transformer网络[21], 有着很高的并行计算能力。
ELMo词向量表示法是PETERS M等人[18]在2018年提出的。它是一种新型深度语境化词表示方法, 通过使用双向语言模型进行预训练, 然后将中间结果融合作为词向量的表示。这种词向量会根据上下文的信息而发生变化。ELMo模型先在大语料上进行预训练, 预训练由一个BiLSTM构成, 使用双向模型的中间层和值或者最高层的输出作为ELMo的向量值, 不同层的输出会得到不同层次的词法特征。在有监督的自然语言处理任务中, 可以将ELMo的向量值与具体任务模型的词向量输入或其最高层表示进行联合, 在任务语料上进行最终训练。ELMo是在整个语料库上学习语言模型, 然后利用具体任务的语言模型获取词向量, 并根据具体任务进行变化。其计算结果比Word2vec模型更加准确。
2.2 基于Transformer的预训练模型
Transformer网络是在2017年Google机器翻译团队发表的“Attention is All You Need”一文中提出的[21]。在此之前, 语言模型都是通过RNN和LSTM来建模, 虽然可以学习到上下文间的关系, 但是无法并行化, 会给模型的训练和扩展带来了困难, 因此提出了一种完全基于Attention机制来建立的语言模型, 叫作Transformer模型。Transformer模型完全抛弃了RNN和LSTM等网络结构, 使用了Self - Attention的方式对上下文进行建模, 提高了训练和推理的速度, 因此Transformer成为后续更强大的自然语言处理预训练模型的基础。
2.2.1 Transformer模型架构
绝大多数的序列处理都采用了Encoder - Decoder结构, 给定输入序列
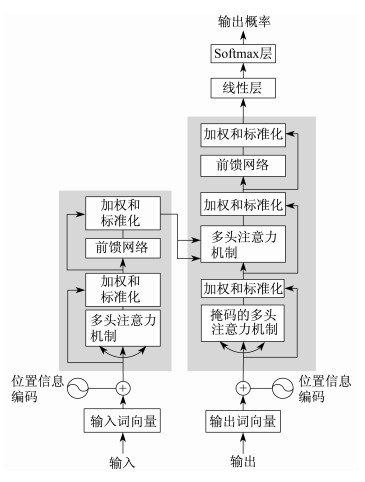

从模型可以看出, 输入的数据首先要转换成对应的词向量, 但这里的词向量是加入了位置信息的, 称为位置词向量。由于Transformer模型里没有循环神经网络这样的结构, 所以无法捕捉序列信息。序列信息代表了全局的结构, 因此必须将序列分词的相对或绝对位置信息计算进来。位置信息的计算公式如下
| $ {{P}_{p, 2i}}=\text{sin}~\left( \frac{p}{10\text{ }000\frac{2i}{{{d}_{\text{model}}}}{{\text{ }}^{~}}}\text{ } \right)~ $ | (4) |
| $ {{P}_{p, 2i+1}}=\text{cos}~\left( \frac{p}{10\text{ }000\frac{2i}{{{d}_{\text{model}}}}{{\text{ }}^{~}}}\text{ } \right)~ $ | (5) |
式中:
在Transformer模型中使用归一化的点乘Attention, 假设输入查询向量
| $ {\rm{Attention}}\left( {{\rm{ }}\mathit{\boldsymbol{Q}}{\rm{ }}, {\rm{ }}\mathit{\boldsymbol{K}}{\rm{ }}, {\rm{ }}\mathit{\boldsymbol{V }}} \right) = {\rm{softmax}}\left( {\frac{{\mathit{\boldsymbol{Q}}{{\rm{ }}^{\rm{T}}}{\rm{ }}\mathit{\boldsymbol{K}}}}{{\sqrt {{d_k}} }}} \right){\rm{ }}\mathit{\boldsymbol{V}} $ | (6) |
式(6)中的
| $ \begin{array}{l} {\rm{Attention}}\left( {{\rm{ }}\mathit{\boldsymbol{Q}}{\rm{ }}, \mathit{\boldsymbol{ K}}{\rm{ }}, {\rm{ }}\mathit{\boldsymbol{V}}{\rm{ }}} \right) = \\ {\rm{concat(hea}}{{\rm{d}}_{\rm{1}}}{\rm{, hea}}{{\rm{d}}_{\rm{2}}}{\rm{, \ldots , hea}}{{\rm{d}}_h}{\rm{) }}\mathit{\boldsymbol{W}}{^O}\\ {\rm{wherehea}}{{\rm{d}}_i} = \\ {\rm{Attention}}({\rm{ }}\mathit{\boldsymbol{QW}}{_i}^Q, {\rm{ }}\mathit{\boldsymbol{KW}}{_i}^K, {\rm{ }}\mathit{\boldsymbol{VW}}{_i}^{V{\rm{ }})} \end{array} $ | (7) |
在图 1中有3处多头注意力模块。首先是编码器模块中的Self - Attention, 其每层Self - Attention的输入
2.2.2 GPT模型
RADFORD A等人[19]提出的GPT模型, 是用一种半监督方式来处理语言理解的任务, 即无监督的预训练和有监督的微调。它使用单向语言模型学习一个深度模型, 通过引入针对不同任务的参数和对预训练参数进行微调来调整模型结构。GPT模型由12层Transformer模块组成, 使用最后的隐藏层来完成不同的任务, 主要应用于文本分类、关系判断、相似性分析、阅读理解等任务。其训练是在未标记的文本上进行的, 首先是通过前
| $ {L_1}\left( u \right) = \sum\limits_{i} {{\rm{ log}}P({u_i}\left| {{u_{i - k}}, \ldots , {u_{i - 1}};\mathit{\Theta} } \right.{\rm{ }})} $ | (8) |
式中:
然后, 输入词向量和位置向量, 通过12层的Transformer模块, 再经过一个全连接和Softmax层来预测第
| $ \left\{ \begin{array}{l} \mathit{\boldsymbol{h}}{\mathit{\boldsymbol{}}_0} = \mathit{\boldsymbol{ UW}}{{\rm{}}_{\rm{e}}} + \mathit{\boldsymbol{ W}}{_{\rm{p}}}\\ \mathit{\boldsymbol{h}}{\mathit{\boldsymbol{}}_l} = {\rm{Transformer}}\_{\rm{block}}({\rm{ }}\mathit{\boldsymbol{h}}{_{l - 1}})\\ \mathit{\boldsymbol{P}}\left( u \right) = {\rm{softmax}}({\rm{ }}\mathit{\boldsymbol{h}}{\mathit{\boldsymbol{}}_n}\mathit{\boldsymbol{W}}{{\rm{}}_{\rm{e}}}^T) \end{array} \right. $ | (9) |
式中:
最后, 利用12层Transformer模块输出的隐藏状态, 经过一个全连接和Softmax层来预测标签
| $ {L_3}\left( C \right) = {L_2}\left( C \right) + \lambda {L_1}\left( C \right) $ | (10) |
式中:
2.2.3 BERT模型
上述学习任务通常是从左向右的单向语言模型, 会使上下文建模能力受到限制, 只能学习上文信息, 无法学习后来的单词。因此, 在2018年底Google提出了基于双向语言模型的BERT[20], 是一项无监督预训练任务。该模型能从无标签语料中获得通用的语言建模, 使用了双向Transformer编码器模块, 整个模型可以分为预训练和微调两部分。在预训练部分, 不同的任务是在未标记数据集上进行训练; 微调时模型先对预训练的参数进行初始化, 然后在下游任务中用标记数据对所有参数进行微调。其模型结构如图 2所示。
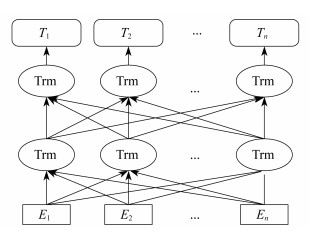
BERT模型由12个Transformer编码层组成, 有768个隐藏层, 12个Self - Attention中的头, 总参数有110 M个, 激活函数使用GELU。其预训练阶段包含掩码语言模型(Masked Language Model, MLM)和下一句子的预测(Next Sentence Prediction, NSP)两个任务。
为了训练深度双向模型, 使用一种随机掩盖一定百分比的输入词的方法, 然后去预测这些被掩盖的词, 叫作掩码语言模型。比如, 首先随机掩盖每一个句子中15%的词, 用其上下文来作预测, 然后采用非监督学习的方法来预测掩盖位置的词。虽然这样可以建立一个双向预训练模型, 但存在的问题是, 掩盖掉15%的词会导致某些词在微调阶段从未出现过, 从而导致预测结果不够精确。为了解决这一问题, 文献[20]作了如下的处理:80%的时间换成掩盖标记, 即掩盖掉; 10%的时间随机取一个词代替要掩盖的词(仍需预测正确的词); 10%的时间不变(仍需预测该位置的词)。
下一句子的预测训练任务中, 选择一些句子对A和B, 其中50%的时间B是A的真正下一个句子, 剩余50%的时间选择句子A和随机句子作为句子对。这使得语言模型能更好地理解两个句子之间的关系。
训练好的基础BERT模型, 通常需要经过两个步骤来进行微调:一是在无标签数据上继续进行无监督训练; 二是添加一个额外的层, 并在新目标上进行训练, 从而学习实际的任务。微调的时间长短取决于任务复杂度、数据大小和硬件资源。
BERT模型能够适配多任务下的迁移学习, 其中最为突出的研究趋势是在特定的语言处理任务中, 使用大型预训练模型进行微调。在迁移学习中可以重新使用预构建模型中的知识, 提高模型的性能和泛化能力, 同时大量减少具有标签的训练样本。
2.2.4 BERT扩展模型
随着BERT模型的提出, 自然语言处理转向更深度的知识迁移的学习, 即迁移整个模型到新任务上。目前, 基于BERT模型扩展出的诸多模型的方法及其特征如下。
(1) XLM模型[22] 它是Facebook在BERT模型的基础上提出的跨语言版本, 实现了多种语言的融合。它引入了一种新的无监督方法, 将不同语言的语句编码到一个共享的词向量空间, 用于训练多种语言的表征, 并提出了一种新的有监督方法, 使用平行语料, 来增强多语言预训练的表现。
(2) MT - DNN模型[23] 它是一种多任务深度神经网络, 结合了单句分类、句子对分类、文本相似度打分和相关度排序4种类型的任务。它用于跨多种自然语言理解任务的学习表示, 将BERT模型作为共享的文本编码层, 将多任务学习和语言模型预训练结合起来以提高文本表征效果。
(3) UniLM模型[24] 它是一种新型统一的预训练语言模型, 既可用于自然语言理解, 也可用于生成任务。它使用了共享的多层Transformer网络, 利用特定的自注意掩码来控制预测条件的上下文。UniLM模型的预训练使用了3种类型的语言建模, 包括单向模型(从左到右和从右到左)、双向模型和序列到序列预测模型。
(4) SpanBERT模型[25] 它是基于分词级别的预训练方法, 提出了一个新的分词边界目标进行模型训练。通过对分词添加掩码, 能够使模型依据其所在的语境预测整个分词。它对BERT模型进行了两种改进:一是对随机的邻接分词而非随机的单个词语添加掩码; 二是使用分词边界的表示来预测被添加掩码的分词内容。这些改进使得该模型能够对分词进行更好的表示和预测。
(5) RoBERTa模型[26] 它是BERT模型的一种改进版, 同样采用了屏蔽语言模型, 但舍弃了下句预测模型。它主要在3个方面做出了改进:一是模型的具体细节层面, 改进了优化函数; 二是训练策略层面, 改用了动态掩码的方式训练模型, 证明了下句预测模型训练策略的不足, 采用了更大的训练样本数; 三是数据层面, 使用了更大的数据集和双字节编码来处理文本数据。
(6) XLNet模型[27] 它是一种自回归语言模型, 使用了排列语言模型, 将句子随机排列, 用自回归的方法进行训练, 从而获得双向信息, 并且可以学习单词之间的依赖关系, 获得更多的上下文信息。采用Transformer - XL替代Transformer架构, 使用了更丰富的语料信息。
(7) ALBERT模型[28] 它是一种轻量级的BERT模型, 采用了一种因式分解的方法来降低参数量, 对Transformer模型中的全连接层和Attention层进行参数共享, 由于减少了参数量, 训练速度有了大幅提升。它对BERT模型参数量过大且难以训练的问题进行了优化, 对词向量矩阵进行分解, 并在层与层之间共享参数, 还将下句预测模型替换为句序预测任务, 即给定一些句子预测它们的排列顺序。
(8) ERNIE(Tsinghua)模型[29] 它是一种多信息实体增强语言表征模型。该模型同时聚合上下文和知识事实的信息, 并同时预测单词和实体, 从而构建了一种知识化的语言表征模型。用知识图谱增强BERT模型。它通过知识嵌入算法编码知识图谱的图结构, 将多信息实体嵌入作为输入。基于文本和知识图谱的对齐, 将知识模块的实体表征整合到语义模块的隐藏层中。
(9) KnowBERT模型[30] 它是在ERNIE模型的基础上添加实体信息链接器, 将知识库里的结构化信息融入到大规模预训练模型中。它设计了一个可插拔式的轻量级层(知识注意力和语境重组组件), 融入了外部知识的实体表示, 并整合了所有单词的表示。
2.2.5 基于BERT的其他模型
以下模型是采用大规模训练数据以及跨模态信息架构的模型。
(1) VideoBERT模型[31] 它是一种视频和语言表征的联合学习模型。从视频数据的向量量化和现有的语音识别输出结果上分别导出视觉token和语言学token, 然后在这些token的序列上学习双向联合分布, 预测视频内容。
(2) CBT模型[32] 它是一种新的视频和文本表征的联合学习模型。与VideoBERT模型不同的是, CBT模型中的视频输入和文本输入分成了两支。视频输入经过S3D网络得到视觉特征序列, 文本输入经过BERT模型得到文本特征序列, 两路序列经过交叉的Transformer层做注意力计算, 进行多任务的预训练。
(3) ViLBERT模型[33] 它是一个学习任务无关的图像内容与自然语言联合表征的模型。将BERT模型的架构拓展为一个支持两个流输入的多模态模型。在这两个流中分别预处理视觉和文本输入, 并在联合注意力Transformer层中进行交互。预训练任务包括掩码图像标签的预测任务、图文匹配任务以及掩码语言模型任务。
(4) VisualBERT模型[34] 它是一个简单有效的视觉和语言基准线模型。该框架可以对不同的视觉-语言任务进行建模, 且简单灵活。在无显式监督的情况下建立语言元素和图像中区域间的联系, 也可对句法关系和追踪有一定的敏感性。
(5) B2T2模型[35] 它是一种在统一架构中将视觉特征和文本分析相结合的神经网络, 可以合并处理视觉和自然语言数据。
(6) Unicoder - VL模型[36] 它是一个以预训练的方式学习视觉和语言的联合表征的通用编码器。该模型从基于语言和视觉内容输入的联合单词学习到内容相关的表征, 可以预测一张图像和一段文本描述之间是否相符。
(7) LXMERT模型[37] 它设计了一个大规模的Transformer模型, 包括一个对象关系编码器、一个语言编码器和一个跨模态编码器, 从Transformer结构中学习跨模态编码器表征。该模型用大量的图像和句子对模型进行预训练, 具备了联系视觉和语言语义的能力。
(8) VL - BERT模型[38] 它是一种新的用于视觉-语言任务的可预训练的通用表征, 以简单而强大的Transformer作为主干, 并将其扩展为以视觉和语言嵌入特征作为输入。输入中的每个元素可以是句子中的单词, 也可以是图像中一个感兴趣的区域。该模型能与所有视觉-语言的下游任务兼容。
(9) ERNIE(baidu)模型和BERT - wwm模型[39-40] 它们均通过对词、实体、先验语义知识等语义单元的掩码, 使得模型能够得到完整概念的语义表。ERNIE(baidu)模型是百度提出的基于知识增强的语义表示模型, 通过建模海量数据中的词、实体及实体关系, 学习真实世界的语义知识。该模型主要对BERT模型中掩码语言模型进行改进, 引入了对单词、实体、短语进行掩码的3种掩码方式, 直接对语义知识进行建模, 增强了模型的语义表示能力。BERT - wwm是一种基于全词遮罩技术的中文预训练模型。它在原始BERT模型的基础上引入全词遮罩, 用掩码标签替换一个完整的词而不是子词, 这是因为中文中最小的token是字, 包含了更多信息的词是由一个或多个字组成, 且每个词之间无明显分隔。
综上讨论的是预训练语言模型最新的研究进展。自然语言处理领域最新发展进程中的两个主要趋势就是迁移学习和Transformer的广泛应用。目前大量的预训练语言模型都是基于序列编码模块上的Transformer架构, 在没有更好的架构提出之前, 未来研究的方向更多的还是寻求模态之间更有效的融合方式, 以及在任务处理的创新上, 比如是否可以引入多模态内容检索、多模态内容之间的相关任务(如多文、多图的内容匹配等)。
3 结语
长久以来, 国内外学者们致力于让计算机能真正地了解人类的思维逻辑, 掌握人类的语言, 甚至赋予其一定的情感让它们更好地为人类服务。文本作为高级抽象的内容表达特征存在, 计算机首先要掌握文本的信息及涵义。经过长期的研究, 从词向量的出现到语言模型的提出以及预训练语言模型的发展, 自然语言处理已经有了质的飞越。本文按照文本信息抽象方法的发展历程, 介绍了自然语言文本特征处理的相关研究方法。未来随着Web3.0和5G技术的推广, 网络资源无疑是最大、最丰富的语料库, 同时语义网和关联数据的进一步发展, 网络文本资源越来越结构化、互联化, 因此新型的信息组织结构与信息之间的链接方式将会更多地应用到文本处理之中。
参考文献
-
[1]冀宇轩. 文本向量化表示方法的总结与分析[J]. 电子世界, 2018(22): 12-14.
-
[2]CHEN K, ZHANG Z, LONG J, et al. Turning from TF-IDF to TF-IGM for term weighting in text classification[J]. Expert Systems with Applications, 2016, 66: 245-260. DOI:10.1016/j.eswa.2016.09.009
-
[3]王本友.结合传统计数特征和基于词嵌入特征的中文问答方法[D].天津: 天津大学, 2017. http://cdmd.cnki.com.cn/Article/CDMD-10056-1018055743.htm
-
[4]徐健.基于字词对齐的中文字词向量表示方法[D].合肥: 中国科学技术大学, 2017. http://cdmd.cnki.com.cn/Article/CDMD-10358-1017065229.htm
-
[5]BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic languagemodel[J]. The Journal of Machine Learning Research, 2003(3): 1137-1155.
-
[6]MIKOLOV T, KARAFIÁT M, BURGET L, et al.Recurrent neural network based language model[C]//Proceedings of 2010 ISCA.Makuhari, Chiba, Japan, 2010.
-
[7]MIKOLOV T.Statistical language models based on neural networks[D].Brono, Czech Republic: Brno University of Technology, 2012. http://www.ixueshu.com/document/4d97238500d0f4dd318947a18e7f9386.html
-
[8]MIKOLOV T, CHEN K, CORRADO G, et al.Efficient estimation of word representations in vector space[EB/OL].(2013-01-16)[2020-01-03].https://arxiv.org/asb/1301.3781. https://arxiv.org/abs/1301.3781
-
[9]MIKOLOV T, SUTSKEVER I, CHEN K, et al.Distributed representations of words and phrases and their compositionality[C]//Proceedigns of the 26th International Coference on Neural Information Processing Systems.Stateline: ACM.2013: 3111-3119.
-
[10]RUMELHART D E, HINTON G E, WILLIAMS R J. Learning representations by back propagating errors[J]. Nature, 1986, 323: 533-536. DOI:10.1038/323533a0
-
[11]LI X, XIE H, LI L J. Research on sentence semantic similarity calculation based on Word2vec[J]. Computer Science, 2017, 44(9): 256-260.
-
[12]夏天. 词向量聚类加权TextRank的关键词抽取[J]. 数据分析与知识发现, 2017, 1(2): 28-34.
-
[13]林江豪, 周咏梅, 阳爱民, 等. 结合词向量和聚类算法的新闻评论话题演进分析[J]. 计算机工程与科学, 2016, 38(11): 2368-2374.
-
[14]周清清, 章成志. 在线用户评论细粒度属性抽取[J]. 情报学报, 2017, 36(5): 56-65.
-
[15]KIM M S, WAB S, PARIS C.Detecting social roles in Twitter[C]//Proceedings of The Fourth International Workshop on Natural Language Processing for Social Media.Austin, TX: Association for Computational Linguistics, 2016: 34-40.
-
[16]MELAMUDO, GOLDBERGER J, DAGAN I.Context2vec: learning generic context embedding with bidirectional LSTM[C].Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning.Berlin, Germany: Association for Computational Linguistics, 2016.
-
[17]PENNINGTON J, SOCHER R, MANNING C.Glove: global vectors for word repreentation[C]//Proceedgins of 2014 Conference on Empirical Methods in Natural Language Processing.Doha, Qatar: association for Computational Linguistics.2014: 1532-1543.
-
[18]PETERS M, NEUMANN M, IYYER M, et al.Deep contextualized word representations[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.New Orleans, Louisiana: Association for Computational Linguistics, Papers.Stroudsburg: ACL, 2018: 2227-2237.
-
[19]RADFORD A, NARASIMHAN K, SALIMANS T, et al.Improving language understanding by generative pre-training[EB/OL].(2018-11-22)[2020-02-26].https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf.
-
[20]DEVLIN J, CHANG M W, LEE K, et al.BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL].(2018-10-11)[2020-01-10].https: //arxiv.org/abs/1810.04805v1.https://arxiv.org/abs/1810.04805v1
-
[21]VASWANI A, SHAZEER N, PARMAR N, et al.Attention is all you need[EB/OL].(2017-06-12)[2019-11-15].https://arxiv.org/abs/1706.03762.
-
[22]LAMPLE G, CONNEAU A.Cross-lingual language model pretraining[EB/OL].(2019-01-22)[2019-12-20].https://arxiv.org/abs/1901.07291.
-
[23]LIU X, HE P, CHEN W Z, et al.Multi-task deep neural networks for natural language understanding[EB/OL].(2019-01-31)[2020-02-01].https://arxiv.org/abs/1901.11504?context=cs.
-
[24]DONG L, YANG N, WANG W, et al.Unified language model pre-training for natural language understanding and generation[C].Proceedings of the 33rd Conference on Neural Information Processing System.Vancouver, Canada.2019.
-
[25]JOSHI M, CHEN D, LIU Y, et al.SpanBERT: Improving pre-training by representing and predicting spans[EB/OL].(2019-07-24)[2020-02-23].https://arxiv.org/abs/1907.10529.
-
[26]LIU Y, OTT M, GOYAL N, et al.RoBERTa: a robustly optimized BERT pretraining approach[EB/OL].(2019-07-26)[2020-02-25].https://arxiv.org/abs/1907.11692.
-
[27]YANG Z, DAI Z, YANG Y, et al.XLNet: generalized autoregressive pretraining for language understanding[EB/OL].(2019-06-19)[2020-02-25].https://arxiv.org/abs/1906.08237.
-
[28]LAN Z, CHEN M, GOODMAN S, et al.ALBERT: a lite BERT for self-supervised learning of language representations[EB/OL].(2019-09-26)[2020-02-25].https://arxiv.org/abs/1909.11942.
-
[29]ZHANG Z, HAN X, LIU Z, et al.ERNIE: enhanced language representation with informative entities[EB/OL].(2019-05-17)[2020-02-25].https://arxiv.org/abs/1905.07129.
-
[30]PETERS M E, NEUMANN M, LOGAN Iv R L, et al.Knowledge enhanced contextual word representations[EB/OL].(2019-09-09)[2020-02-25].https://arxiv.org/abs/1909.04164.
-
[31]SUN C, MYERS A, VONDRICK C, et al.VideoBERT: a joint model for video and language representation learning[EB/OL].(2019-04-03)[2020-02-25].https://arxiv.org/abs/1904.01766.
-
[32]SUN C, BARADEL F, MURPHY K, et al.Learning video representations using contrastive bidirectional transformer[EB/OL].(2019-06-13)[2020-02-25].http://arxiv.org/abs/1906.05743.
-
[33]LU J, BATRA D, PARIKH D, et al.ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[EB/OL].(2019-08-06)[2020-02-25].https://arxiv.org/abs/1908.02265.
-
[34]LI L H, YATSKAR M, YIN D, et al.VisualBERT: a simple and performant baseline for vision and language[EB/OL].(2019-08-09)[2020-02-25].https://arxiv.org/abs/1908.03557.
-
[35]ALBERTI C, LING J, COLLINS M, et al.Fusion of detected objects in text for visual question answering[EB/OL].(2019-08-14)[2020-02-26].https://arxiv.org/abs/1908.05054.
-
[36]LI G, DUAN N, FANG Y, et al.Unicoder-VL: a universal encoder for vision and language by cross-modal pre-training[EB/OL].(2019-08-16)[2020-02-26].ttps://arxiv.org/abs/1908.06066.
-
[37]TAN H, BANSAL M.LXMERT: Learning cross-modality encoder representations from transformers[EB/OL].(2019-08-20)[2020-02-26].https://arxiv.org/abs/1908.07490.
-
[38]SU W, ZHU X, CAO Y, et al.VL-BERT: pre-training of generic visual-linguistic representations[EB/OL].(2019-08-22)[2020-02-26].https://arxiv.org/abs/1908.08530.
-
[39]SUN Y, WANG S, LI Y, et al.ERNIE: enhanced representation through knowledge integration[EB/OL].(2019-04-19)[2020-02-26].https://arxiv.org/abs/1904.09223.
-
[40]CUI Y, CHE W, LIU T, et al.Pre-training with whole word masking for Chinese BERT[EB/OL].(2019-06-19)[2020-02-26].https://arxiv.org/abs/1906.08101.


