|
|
|
发布时间: 2020-10-25 |
计算机技术 |
|
|
|


|
收稿日期: 2020-04-08
基金项目: 国家自然科学基金(61772327);奇安信大数据协同安全国家工程实验室开放课题(QAX-201803)
中图法分类号: TN47
文献标识码: A
文章编号: 2096-8299(2020)05-0511-06
|
摘要
针对硬件木马特征多样性以及激活效率低的现状,提出了一种基于随机森林的硬件木马检测方法,即在门级电路检测触发节点。首先,从已知网表中提取每个节点的特征值;然后,根据时序电路和组合电路两种情况,通过随机森林分类器赋予每种特征相应的权重并生成两种模型(双模型用于识别未知网表中的可疑触发节点,并且给出每个可疑触发节点的可疑度结果);最后,通过可疑度排名的前n%个可疑节点检测硬件木马。实验结果证明了该方法的优越性。
关键词
硬件木马检测; 门级网表; 随机森林; 可疑节点
Abstract
In view of the diversity of hardware Trojans features and low activation efficiency, a hardware Trojans detection method based on random forest is proposed, which is to detect the trigger node in the gate level circuit.First, we extract the feature value of each node from the known netlist.Then according to the two cases of sequential circuit and combined circuit, the random forest classifier is used to give each feature a corresponding weight and generate two models, which are used to identify suspicious trigger nodes in the unknown netlist, and gives each suspicious trigger node suspicious results.Finally, hardware Trojans are detected by the top n% suspicious nodes ranked by suspiciousness.The experimental results shows the superiority.
Key words
hardware Trojans detection; gate-level netlist; random forest; suspicious net
由于芯片设计和制造的全球化, 一些为了经济利益而将设计和制造外包的行为已经引起了人们对国家安全问题的关注。同时, 随着SoC(System on Chip)系统集体技术的发展以及大量第三方IP核的使用, 电路的安全性难以得到保证, 导致集成电路系统的可靠性下降[1]。
1 硬件木马及其检测方法
1.1 硬件木马结构
一般来说, 硬件木马被定义为对设计的任何有意修改, 从而改变设计的原有特性。它具有隐蔽性, 并且能够在特定条件下改变设计功能。图 1为硬件木马的结构。
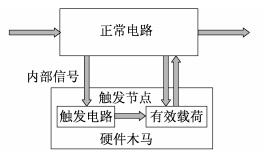

典型的硬件木马由触发电路和有效载荷组成。当内部信号满足触发条件时, 触发电路会通过硬件木马中的触发节点通知有效载荷电路。有效载荷电路包含多种功能。高性能硬件设备存在诸多缺陷, 如信息泄漏、系统故障和功耗大等。硬件特洛伊木马对人、公司和国家构成巨大威胁。硬件设备的内部通常是黑盒子, 因此用户别无选择, 只能信任其供应商。目前, 硬件木马的威胁和对策已得到了广泛的研究。
1.2 相关检测方法
由于硬件木马的种类繁多, 功能各异, 而且硬件木马的植入方式和触发方式也不完全相同, 因此对于硬件木马检测不存在通用的方法。集成电路安全是当前需要关注的一个焦点问题, 而硬件木马检测作为集成电路安全的一部分, 也备受全世界安全领域的关注。在过去的一段时间内, 硬件木马检测的焦点主要放在逻辑测试[2-3]和旁信号分析[4-5]两个方面。文献[6]针对安全性问题, 建立了辅助电路来帮助硬件木马的检测, 将电路冗余部分智能地应用到PIP3 cores中来对木马电路进行计数。文献[7]增加了认证技术信息来防止电路中插入硬件木马。文献[8]通过对目标电路施加随机测试向量, 并统计电路节点的翻转概率, 选取节点翻转概率临界阈值, 筛选出目标电路中的低活性节点作为木马触发节点; 然后利用格雷码的编码电路生成候选测试向量, 采用二分法对候选测试向量进行分组, 并统计每组测试向量下木马触发节点的翻转概率, 筛选出使木马触发节点翻转概率最大的测试向量作为生成的硬件木马测试向量; 最后再根据多参数旁路检测方法实现对硬件木马的检测。
近年来, 随着机器学习[9]和人工智能的崛起及快速发展, 硬件木马检测方法也发生了变化。文献[10]提出了新的检测方法——静态检测方法, 即通过检查给定电路是否含有硬件木马, 不模拟电路或实际运行状态, 而是使用硬件木马的相关信息进行检测。由于此方法实际上并不模拟电路运行状态, 因此不必生成输入测试模式, 而且检测结果不依赖于模拟结果。比如文献[10-11]通过门级网表分析硬件木马特征并自动识别无硬件木马的电路。
针对硬件木马检测难度高、检测效果不明显的特点, 本文提出了一种基于随机森林的硬件木马检测方法。首先, 从国外开源网站Trust-HUB[12]上下载门级网表数据, 通过分析门级网表提取14种硬件木马特征; 然后, 利用随机森林分类器[12]对每种特征赋予权重, 采用预处理方法解决木马触发节点数量少的问题; 最后, 基于随机森林对时序电路和组合电路不同的电路情况训练生成两种模型, 并对木马触发节点进行检测, 将检测结果与现有方法作比较, 以验证本文方法的优越性。
2 木马触发节点的检测
2.1 检测流程
本文采用随机森林算法来训练数据集, 并将触发节点与检测到的插入硬件木马的网表的正常节点区分开来。由于不同类型的硬件木马在结构上存在很大的差异, 将导致检测结果存在偏差, 因此本文将硬件木马分为两种类型进行训练:一是组合型木马, 其触发电路仅由组合电路组成; 二是时序型木马, 其触发电路包含时序电路。图 2为硬件木马检测流程。
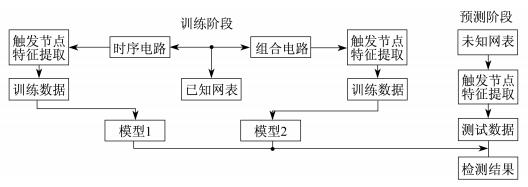
将整体检测流程分为两个阶段, 即训练阶段和预测阶段。在训练阶段中, 分别从组合型木马和时序型木马中提取每个节点的特征值, 并标注其节点是否为木马触发节点。在经过一些数据预处理操作后, 分别采用随机森林算法训练两种类型的训练数据并获得两个检测模型。在预测阶段, 存在未知类型且需要检测的网表, 同样提取需检测网表中每个节点的特征值作为测试数据, 并且将其输入到这两个模型中, 预测模型将会给出检测网表中每个节点是否为木马触发节点的结果。最后通过综合两个检测模型的结果, 获得最终可疑触发节点的检测结果。
2.2 木马触发节点检测
在插入硬件木马的电路中, 将没有插入硬件木马的部分称为正常电路, 插入硬件木马的部分称为木马电路。正常电路和木马电路的信号节点分别称为正常节点和木马节点。传统的静态硬件木马检测方法通常采用机器学习算法, 将网表中的节点分为一组木马触发节点和一组正常节点。对于两类机器学习算法, 当两种类型的训练数据之间的特征区分度和想分类的目标类别之间的特征差异较大时, 可以期望获得更好的特征模型和更准确的分类结果。但在正常电路和木马电路的交界处, 正常节点和木马节点非常相似, 会导致它们之间的特征值非常相似。此外, 木马节点之间的特征值也存在显著差异。因此, 将电路节点分为木马节点和正常节点的方法不利于判别式检测模型的训练, 难以保证检测结果的准确性。
本文改变以往检测思路, 将检测木马节点转移到木马触发节点, 因为木马触发节点是硬件木马电路中触发电路和有效载荷之间的互连。当满足特定的唯一触发条件时, 由触发节点激活硬件木马, 就意味着木马触发节点起着承前启后的作用, 触发节点激活后, 会驱动有效载荷实现恶意功能(这些功能通常包括对主要输出或内部注册值的一些修改), 因此触发节点在功能和结构上有明显的特殊性。基于这些特殊性, 触发节点的前后电路结构与正常节点的结构区别明显, 从而可以更好地构造检测模型, 并且通过机器学习算法获得更准确的检测结果。
2.3 触发节点特征
本文从Trust-HUB基准电路中选择了插入硬件木马的门级网表。这些门级网表由Verilog-HDL语言编写。由于本文选择将触发节点作为检测目标, 因此需要选取一些可以代表触发节点前后结构的特征。通过分析所选的门级网表, 发现可能与触发节点密切相关的结构特征如下。
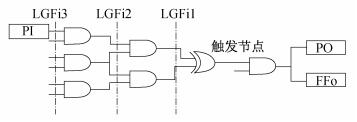
(1) 逻辑门扇入(LGFix)在组合电路触发的情况下, 尽管硬件木马具有非常少的触发条件, 但与正常节点相比, 触发节点处的逻辑门扇入数量必须大。因此, 本文选择LGFix, 它代表距触发节点x级的逻辑门扇入数量。本文将x级别设置在5之内, 因为当x级别到触发节点的距离达到5以上时, 就会导致它们与触发节点的关联性降低[13]。因此, 本文将它们定义为LGFi1, LGFi2, LGFi3, LGFi4, LGFi5。为了表示前级扇入级别之间的关系, 又定义了ΔLGFi, 表示LGFi1和LGFi5之间的数量差异。
(2) 触发器扇出(FFox)在时序电路中, 因为硬件木马电路始终很小, 所以时序电路的触发级别更小且更难检测。因此, 本文选择FFox表示从触发节点的输出侧到x级别的触发器数量。此外, 还选取了min(FFo)来表示距触发节点输出侧最近的触发器级别。同上述分析一样, 我们将x级别设置在5之内, 分别为FFo1, FFo2, FFo3, FFo4, FFo5。
(3)原始输入(PI)和原始输出(PO)硬件木马的触发点一般会选择电路中的原始输入和原始输出。当原始输入达到触发条件时, 硬件木马开始工作。此外, 对于具有更改信息功能的硬件木马, 通常选择IC的原始输出作为端口, 以实现更改内部信息的目的。可以看出, 原始输入和原始输出与硬件木马高度相关。因此, 本文将从任意原始输入到触发节点的最小逻辑门数量和触发节点到任意原始输出的最小逻辑门数量作为触发节点特征, 并将它们定义为PI和PO。
图 3为触发节点特征示意。对于图 3中的触发节点, 此时各特征系数为LGFi3=6, LGFi2=3, LGFi1=2, PI=1, PO=1, min(FFo)=1。
3 随机森林和数据预处理
从网表中提取出触发节点特征后, 需要基于随机森林算法构建检测模型, 以区分触发节点和检测网表的其他正常节点。随机森林就是通过集成学习的思想将多棵决策树集成的一种算法, 它可以有效地改善机器学习的结果。
本文将来自触发节点处的一组数据和来自正常节点的一组数据输入到随机森林模型中进行训练。因为网表数据中只有一个触发节点, 所以触发节点的训练数据集比正常节点的训练数据集要少得多, 由此会产生训练阶段的不平衡问题。因此, 本文引入了两个数据预处理操作来平衡两个训练数据集。首先, 搜索特征值相同的节点, 保留其中一个特征值并删除其余特征。然后, 将剩余正常节点的总数计为N1, 将触发节点总数记为计为N2, 并复制触发节点的所有训练数据(N1/N2), 形成与正常节点训练数据集相同数量的触发节点数据集。这样就解决了触发节点和正常节点不平衡的问题。
4 实验环境及实验结果比较
4.1 实验环境配置
实验中, 使用表 1中列出的16个Trust-HUB门级基准电路, 并且每个门级基准电路都插入了硬件木马, 每一个硬件木马中包含一个触发节点; 采用具有128 GB内存的Intel Xeon E5-2667计算机环境, 采用通过scikit-learn[14]机器学习库在Python中实现的随机森林分类器。
表 1
TrustHUB基准电路类型和节点总数
| 基准电路 | 类型 | 节点总数 |
| RS232-T1000 | 组合电路 | 284 |
| RS232-T1100 | 组合电路 | 285 |
| RS232-T1200 | 组合电路 | 288 |
| RS232-T1300 | 组合电路 | 280 |
| RS232-T1400 | 组合电路 | 284 |
| RS232-T1500 | 组合电路 | 287 |
| RS232-T1600 | 组合电路 | 280 |
| s15850-T100 | 时序电路 | 2 207 |
| s35932-T100 | 时序电路 | 5 881 |
| s35932-T200 | 组合电路 | 5 878 |
| s35932-T300 | 组合电路 | 5 903 |
| s38417-T100 | 组合电路 | 5 486 |
| s38417-T200 | 组合电路 | 5 486 |
| s38417-T300 | 组合电路 | 5 515 |
| s38584-T100 | 组合电路 | 6 855 |
| s38584-T200 | 时序电路 | 7 027 |
利用留一法交叉验证方法[15]来验证检测方法的有效性。分批次的检测16种基准电路。方法是:先将其中15种基准电路作为训练集, 剩下的一种作为测试集, 然后选择下一种基准电路作为测试集, 剩下的15种作为训练集, 以此类推, 直至检测完所有的16种基准电路为止。
4.2 实验结果比较
在训练步骤之后, 预期将获得两种类型的检测模型。然后通过目标检测网表中每个节点的特征数据, 将其输入到检测模型中进行预测。期望每个检测模型都给出每个怀疑是触发节点的可疑值, 再根据这些值取前n%个节点标记为可疑触发节点。最后通过标记来自两个检测模型的可疑节点来计算结果。
由于是二分类, 所以本文采用TN, TP, FN, FP这4种值来计算分类器判定数据的结果。其中:TN代表正常节点被分类器判定为正常节点的数量; TP代表触发节点被分类器判定为触发节点的数量; FN代表触发节点被分类器错判为正常节点的数量; FP代表正常节点被分类器错判为触发节点的数量。基于这4种值, 为了衡量分类模型的好坏, 引出4种新的评估指标来判断分类模型的效果, 即TPR, TNR, Precision, F-score。其中:TPR=TP/(TP+FN), 表示触发节点被分类正确的概率; TNR=TN/(TN+FP), 表示正常节点被分类正确的概率; Precision=TP/(TP+FP), 表示分类器预测是触发节点的所有结果中预测正确的概率; F-score=2×Precision×TPR/(Precision+TPR), 表示Precision和TPR的加权调和平均, 它是统计学中的一个标准。
对于获得的可疑值, 本文为每个检测模型计算出真实触发节点的可疑等级, 并使用它们之间的较高等级来估计适当的n%值, 用以准确标记可疑的触发节点。为了有效地识别可疑节点, 使用前面的TPR, TNR, Precision, F-score作为评价结果指标。
针对表 1中16个门级网表进行了实验。通过训练出来的两个检测模型给出的真实触发节点的可疑度排名, 计算出可疑度排名率, 这代表着较高可疑度的触发节点占总节点数量的比值, 并估计n%的适当值, 结果如表 2所示。
表 2
各基准电路可疑度排名
| 基准电路 | 可疑度排名 | 可疑度排名率/% | |
| 模型1 | 模型2 | ||
| RS232-T1000 | 1 | 149 | 0.352 |
| RS232-T1100 | 2 | 170 | 0.702 |
| RS232-T1200 | 2 | 159 | 0.694 |
| RS232-T1300 | 1 | 201 | 0.357 |
| RS232-T1400 | 1 | 175 | 0.352 |
| RS232-T1500 | 3 | 134 | 1.045 |
| RS232-T1600 | 6 | 163 | 2.143 |
| s15850-T100 | 872 | 437 | 19.801 |
| s35932-T100 | 4 503 | 1 | 0.017 |
| s35932-T200 | 1 | 11 | 0.017 |
| s35932-T300 | 1 | 1 | 0.017 |
| s38417-T100 | 1 | 2 951 | 0.018 |
| s38417-T200 | 197 | 4 294 | 3.591 |
| s38417-T300 | 1 | 2 976 | 0.018 |
| s38584-T100 | 534 | 2 482 | 7.790 |
| s38584-T200 | 2 038 | 1 381 | 19.653 |
由于在每个需检测的门级网表中都有一个真实的触发节点, 因此, 如果正确标记为真实的触发节点, 则TPR的值会为100%;但如果标记错误, 则TPR的值就会为0。因此, 16种门级基准电路的平均TPR的值就是正确标记为真实触发节点的门级网表与总16种网表的比值。此外, 当将每个检测模型的前n%个可疑节点标记为真实可疑节点时, 随着n%系数的不断增大, 其被标记为真实触发节点的数量也会增加, 从而会降低TNR的值, 但是Precision和F-score的值会增加。根据以上分析和表 2中的可疑度排名, 为获得更好的TPR, TNR, Precision, F-score的结果, 本文将n%设置为5%, 7%, 10%, 来计算出平均TPR, TNR, Precision, F-score的值, 并将本文方法与现有的多层神经网络方法[16]作比较, 结果如表 3所示。
表 3
实验结果比较
| 评价指标 | 随机森林 | 多层神经网络 | ||
| 5% | 7% | 10% | ||
| 平均TPR | 86 | 90 | 95 | 85 |
| 平均TNR | 90 | 82 | 69 | 70 |
| 平均Precision | 85 | 91 | 98 | 82 |
| 平均F-score | 85 | 90 | 96 | 83 |
由表 3可知, 将n%设置为7%时检测触发节点, 本文实验获得了最佳结果, 此时, 平均TPR为90%, 平均TNR为82%, 平均Precision为91%, 平均F-score为90%。实验结果表明, 本文方法在检测触发节点方面更有优势, 而且由于FP的值只能为1或0, 这标志着本文方法将更少的正常节点误判为触发节点。在未来的工作中, 我们将主要研究在增大触发节点准确率的基础上, 适当地提高正常节点误判的准确率。
5 结语
本文提出了一种基于随机森林的硬件木马检测方法。从Trust-HUB上的已知门级网表中为每个节点提取出了14种木马触发节点特征, 通过随机森林赋予每种触发节点特征权重值, 并借用预处理手段解决了木马触发节点数量少的问题。然后结合随机森林算法, 依据时序电路与组合电路的不同电路情况, 训练两种类型的检测模型。检测模型会给出未知门级网表中每个检测到为可疑触发节点的结果及特征值。通过根据可疑度排名对前n%的可疑触发节点进行标记。当n%设置为7%时, 16种网表的实验结果如下:平均TPR为90%, 平均TNR为82%, 平均Precision为91%, 平均F-score为90%。由此可见, 对比现有的方法, 更显示了本方法的优越性。
参考文献
-
[1]苏静, 赵毅强, 何家骥, 等. 旁路信号主成分分析的欧式距离硬件木马检测[J]. 微电子学与计算机, 2015(1): 1-4.
-
[2]FLOTTES M, DUPUIS S, BA P, et al.On the limitations of logic testing for detecting Hardware Trojans Horses[C]//201510th International Conference on Design & Technology of Integrated Systems in Nanoscale Era (DTIS), Naples, 2015: 1-5.doi: 10.1109/DTIS.2015.7127362.
-
[3]WU T F, GANESAN K, HU Y A, et al. TPAD:hardware Trojan prevention and detection for trusted integrated circuits[J]. IEEE Trans Comput -Aided Design Integr Circuits Syst, 2016, 35(4): 521-534. DOI:10.1109/TCAD.2015.2474373
-
[4]NOWROZ A N, HU K, KOUSHANFAR F, et al. Novel techniques for high-sensitivity hardware Trojan detection using thermal and powe rmaps[J]. IEEE Trans Comput -Aided Design Integr, 2014, 33(12): 1792-1805. DOI:10.1109/TCAD.2014.2354293
-
[5]XUE M, LIU W, HU A, et al. Detecting hardware Trojan through time domain constrained estimator based unified subspace technique[J]. IEICE Trans Inf Syst, 2014(3): 606-609.
-
[6]FARAG M M, EWAIS M A.Smart employment of circuit redundancy to effectively counter Trojans(SECRET) in third-party IP cores[C]//2014 International Conference on ReConFigurable Computing and FPGAs.Cancun, Mexico, 2014: 1-6.
-
[7]XIAO K, FORTE D, TEHRANIPOOR M. A novel built-in selfauthentication technique to prevent inserting hardware Trojans[J]. IEEE Trans Comput-Aided Design Integr Circuits Syst, 2014, 33(12): 1778-1791. DOI:10.1109/TCAD.2014.2356453
-
[8]LIU H F, LUO H W, WANG L W, et al. Survey on hardware Trojan horse[J]. Microelectronics, 2011, 41(5): 709-713.
-
[9]许智, 李红娇, 陈晶晶. 基于机器学习的用户窃电行为预测[J]. 上海电力学院学报, 2017, 33(4): 389-393.
-
[10]KULKARNI A, PINO Y, MOHSENIN T.Adaptive real-time Trojan detection framework through machine learning[C]//2016 IEEE International Symposium on Hardware Oriented Security and Trust.Mclean, VA, USA, 2016: 120-123.
-
[11]NASR A A, ABDULMAGEED Z M. Automatic feature selection of hardware layout:a step toward robust hardware Trojan detection[J]. J Electron Test, 2016, 32(3): 357-367. DOI:10.1007/s10836-016-5581-5
-
[12]陈晶晶, 李红娇, 许智. 基于随机森林的用电行为分析[J]. 上海电力学院学报, 2017, 33(4): 331-336.
-
[13]WAKSMAN A, SUOZZO M, SETHUMADHAVAN S.Fanci: identification of stealthy malicious logic using boolean functional analysis[C]//Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications Security, 2013: 697-708.
-
[14]PEDREGOSA F, VAROQUAUX G, GRAMFORT A, et al. Scikit-learn:machine learning in python[J]. The Journal of Machine Learning Research, 2011, 12: 2825-2830.
-
[15]KOHAVI R.A study of cross-validation and bootstrap for accuracy estimation and modelselection[C]//Proceeding Softhe 14th International Joint Conference on Artificial Intelligence, 1995: 1137-1145.
-
[16]HASEGAWA K, YANAGISAWA M, TOGAWA N.Hardware trojans classification for gate-level netlists using multi-layer neural networks[C]//2017 IEEE 23rd International Symposium on On-Line Testing and Robust System Design (IOLTS), The Ssaloniki, Greece, 2017.


