|
|
|
发布时间: 2021-06-25 |
智能电网 |
|
|
|


|
收稿日期: 2020-10-10
中图法分类号: TM726
文献标识码: A
文章编号: 2096-8299(2021)03-0217-04
|
摘要
电力设备的安全运行是保证电力系统长期稳定工作的重要基础,因此需要对电力设备的运行状态进行实时监测。实现对电力设备实时监测的关键是对电力设备进行准确的识别和定位。传统的图像检测算法受环境和复杂背景的影响,无法对电力设备进行准确的定位和识别。基于深度学习的目标检测在电力设备运行状态实时监测中具有更广阔的发展前景。针对电力设备红外图像的识别提出了基于Faster R-CNN识别方法。实验结果表明,该方法准确率高,能够准确定位和识别红外图像中的电力设备。
关键词
电力设备; 红外图像; 深度学习; 图像识别
Abstract
The safe operation of power equipment is an important basis to ensure that the power system can work stably for a long time.Therefore, real-time monitoring of the operating status of power equipment is required.The key to real-time monitoring of power equipment is to accurately identify and locate power equipment.Traditional image detection algorithms are affected by the environment and complex background, and cannot accurately locate and identify power equipment.Target detection based on deep learning has broader development prospects in the real-time monitoring of power equipment operating status.The identification method based on Faster R-CNN is launched for the recognition of infrared images of power equipment.Experimental results show that the method has high accuracy and can accurately locate and identify electrical equipment in infrared images.
Key words
power equipment; infrared image; deep learning; image recognition
随着计算机视觉和电力巡检机器人的快速发展, 巡检机器人和计算机视觉技术相结合在智能电网中的应用需求越来越多。近年来, 红外热成像仪搭载在电力巡检机器人、无人机等检测平台上对电力设备进行智能巡检, 减少了运维人员采集电力设备红外图像的工作量。但在巡检机器人和无人机拍摄电力设备的过程中, 由于拍摄角度和拍摄距离的因素, 在图像上显示的尺寸较小且目标模糊[1]。传统的图像分割识别方法, 由于其二值化阈值的选取存在较多人为干扰因素, 对拍摄角度距离差异、光照影响和复杂背景干扰较为敏感, 很难对红外图像中的电力设备进行有效识别[2]。随着深度学习的迅速发展以及硬件水平的提高, 深度卷积神经网络在计算机视觉领域取得了巨大的成功, 为深度学习在电力设备识别和定位中的应用奠定了基础[3]。
深度学习可以处理大规模的文本和图像等数据[4]。现代的图像识别将深度学习应用其中, 通过提取并学习识别物体的特征来适应复杂的环境, 减少了外界因素对物体识别的影响, 提高了图像识别的准确性。图像处理算法改进过程中会出现各种数据集, 如ImageNet训练集、VOC(Visual Object Classes)数据集和人脸检测数据集(Face Detection Data Set and Benchmark, FDDB)等。这些数据集数量很大, 种类很多, 在训练过程中可以在很大程度上解决过拟合问题[5]。
1.1 RCNN系列模型
卷积神经网络从最初的CNN(Convolutional Neural Networks)开始, 由R-CNN, Fast R-CNN逐渐发展为Faster R-CNN。
R-CNN的识别分为3个步骤: 首先, 得到多个候选区域并缩放到统一大小; 其次, 使用CNN分别对每个候选区域进行特征提取; 最后, 通过支持向量机(Support Vector Machine, SVM)对提取到的特征向量进行分类。R-CNN在提取候选区域使用选择性搜索算法, 由于对提取的候选框都需要进行CNN操作, 因此增加了计算量, 使得相应的训练步骤十分繁杂, 训练耗时长, 且每一步要进行数据的保存, 也需要较大的空间。
Fast R-CNN在取代SVM的基础上, 加入了边框回归, 解决了R-CNN的空间开销, 提高了测试速度。但是Fast R-CNN在提取候选区域依然使用的是选择性搜索算法。由于该算法运行速度较慢, 因此不能做到实时检测。
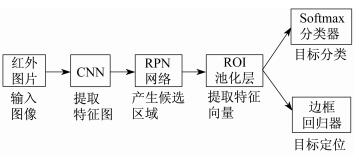
Faster R-CNN在提取候选区域时, 采用区域生成网络(Region Proposal Network, RPN)[11]来取代选择性搜索算法。RPN采用滑动窗口, 通过以窗口为中心, 不断创建出不同大小的中心框, 然后映射到原图片上, 形成候选区。RPN可以批量生成候选区域, 解决了候选框批量生成时间太长的问题。与OLO(Only Look Once)和SSD(Single Shot multiBox Detector)算法相比, RPN精度高, 但速度慢。因此, Faster R-CNN将网络结构分为2部分: 第一部分用于生成候选区域的RPN; 第二部分用于对候选区域中的目标进行识别。2部分共享权值从而提高了训练的效率。Faster R-CNN的网络结构如图 1所示。

1.2 YOLO系列模型
YOLO系列模型逐渐从YOLOv1, YOLOv2发展到YOLOv3。
YOLOv1进行了20多次卷积、4次最大池化, 其中3×3卷积用于提取特征, 1×1卷积用于压缩特征, 最后将图像压缩到7×7×30的大小, 相当于将整个图像划分为7×7的网格, 每个网格负责自己区域的目标检测。
YOLOv2使用了一个新的分类网络作为特征提取部分, 网络使用了较多的3×3卷积核, 在每一次池化操作后使通道数翻倍。借鉴network in network思想, 将1×1卷积核置于3×3卷积核之间来压缩特征。使用批归一化(Batch Normalization)稳定模型训练, 加速收敛, 正则化模型。除此之外, YOLOv2借鉴了R-CNN系列中锚框的理念, 引入了先验框。
YOLOv3改进较大, 主要体现在3个方面: 采用多特征层进行目标检测, 一共提取3个特征层, 分别为(13, 13, 75), (26, 26, 75), (52, 52, 75);采用反卷积UmSampling2d设计, 可以更多更好地提取出特征; 使用了容易优化的残差网络(Residual Network), 能够通过增加深度来提高准确率。其内部的残差块使用了跳跃连接, 缓解了在深度神经网络中因深度增加而带来的梯度消失问题。
1.3 SSD模型
SSD使用了不同层次与尺度的特征图进行检测: 大尺度特征图保留了较多的空间位置信息, 可以用来检测小物体; 小尺度特征图具有更为丰富的语义信息, 可以用来检测大物体。SSD使用VGG-16(Visual Geometry Group Network 16)作为主干网络, 并且将VGG-16最后的2个全连接层替换成卷积核大小为3×3和1×1的卷积层, 同时采用空洞卷积扩张卷积视野, 然后移除分类层并增加一系列卷积层用于检测。
综上所述, 在特征提取方面, Faster R-CNN模型采用共享卷积层提取特征, 由于卷积层层数较深, 可提取更多的目标特征, 对小目标也具有较高的识别精度。YOLO系列和SSD模型虽然在速度上略胜一筹, 但识别准确率相对较低。因此, 本文采用Faster R-CNN模型进行电力设备红外图像识别。
2 Faster RCNN模型预测过程
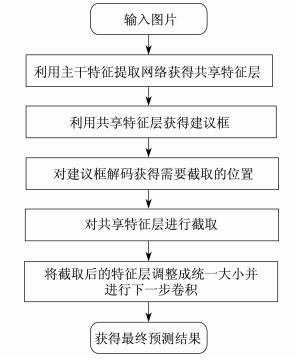
Faster R-CNN模型预测过程主要分为以下3部分。
(1) 特征提取 搭建Faster R-CNN卷积神经网络模型, 由卷积和池化组成的共享卷积层对各幅图像提取目标特征。
(2) 候选区域生成 提取的特征图像通过RPN网络, 将前景和背景各生成9个不同尺寸的候选框, 用非极大值抑制算法微调候选框位置和尺寸, 批量生成候选框。RPN的核心思想是使用CNN直接产生候选框。具体操作是在CNN卷积层后加滑动窗口以及2个卷积层完成候选区域提取。第一个卷积层将特征图每个滑动窗口位置编码成一个特征向量, 使用一个小网络在最后卷积层得到的特征图中进行滑动操作, 即通过卷积操作得到H×W个256维特征向量。第二个卷积层对应2个全连接层, 对H×W个256维特征向量进行2次全连接操作, 即可得到RPN的输出: 2k个分数以及4k个坐标。2k个分数是指候选框中物体是前景的概率以及是背景的概率, 4k个坐标是指候选框相较于原图的偏移[11]。RPN结构如图 2所示。

(3) 分类与回归 采用全连接层处理各个候选区域图片。使用Softmax分类器对候选区域进行分类识别, 并使用回归器对候选区域向量进行处理, 将候选区域优化为一个候选框, 从而得到目标位置信息。
Faster R-CNN模型整体的执行流程如图 3所示。
3 基于深度学习的电力设备红外图像识别
3.1 数据集
本文采用的数据集为各地变电站和多个高压实验室的电力设备红外图像。数据集的制作过程为: 首先对最初始的红外图片进行重命名、图片格式转化和图片尺寸变换; 然后利用图像标注软件对原始红外图片中的电力设备进行标注。创建完成后的电力设备红外图像检测数据库一共包含300张电力设备红外图像, 标注出4类电力设备。将所有红外图片的90%作为训练集, 10%作为测试集。
3.2 环境搭建
操作系统为Windows 10, 运行内存16 G。在操作系统上安装Anaconda3, Visual Studio2015和TensorFlow1.3.0, 以Python为编程语言。利用VGG-16网络结构对电力设备红外图像检测数据库重新进行训练, 将训练后得到的新VGG-16网络结构嵌入到Faster R-CNN模型中, 使用电力设备红外图像检测数据库中的测试图片进行测试, 并观察实验结果。
3.3 结果分析
本文对YOLOv3, SSD和Faster R-CNN模型在测试集上进行了对比试验, 评价指标为识别准确率和测试速度, 不同方法电力设备识别结果如表 1所示。
表 1
不同方法电力设备识别结果
| 模型 | 识别准确率/% | 测试速度/s |
| YOLOv3 | 82 | 1.1 |
| SSD | 86 | 0.8 |
| Faster R-CNN | 95 | 4.0 |
从表 1可以看出, 针对电力设备的识别, YOLOv3和SSD为代表的one-stage模型识别准确率分别为82%和86%, 测试速度分别为1.1 s和0.8 s; 以Faster R-CNN为代表的two-stage模型识别准确率为95%, 测试速度为4.0 s。这说明Faster R-CNN模型在特征提取方面可以提取到更多有用特征, 对目标识别准确率高。YOLOv3和SSD模型虽然对目标的识别准确率不高, 但测试速度远远高于Faster R-CNN模型。
3.4 效果展示
电力设备红外图像的识别效果如图 4所示。

4 结语
本文针对目前的电力设备红外图像识别准确率不高的缺点, 提出了一种基于Faster R-CNN的电力设备红外图像识别方法。结果发现, Faster R-CNN的识别准确率达到了95%, 远远高于YOLOv3和SSD的识别准确率。但Faster R-CNN的检测速度慢于YOLOv3和SSD, 后续可以在提升Faster R-CNN的检测速度上开展进一步研究。
参考文献
-
[1]宋庆武, 王昊炜, 蒋超. 电力巡检机器人综合管理平台开发与应用[J]. 价值工程, 2020, 39(14): 205-207.
-
[2]陈飞. 改进的交互式Otsu红外图像分割算法[J]. 计算机测量与控制, 2020, 28(9): 248-251.
-
[3]曹渝昆, 何健伟, 鲍自安. 深度学习在电力领域的研究现状与展望[J]. 上海电力学院学报, 2017, 33(4): 341-345. DOI:10.3969/j.issn.1006-4729.2017.04.007
-
[4]韩小虎, 徐鹏, 韩森森. 深度学习理论综述[J]. 计算机时代, 2016(6): 107-110.
-
[5]周宇杰. 深度学习在图像识别领域的应用现状与优势[J]. 中国安防, 2016(7): 75-78.
-
[6]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
-
[7]GIRSHICK R. Fast R-CNN[C]//IEEE Conference on Computer Vision and Pattern Recognition. Santiago, Chile: IEEE, 2015: 1440-1448.
-
[8]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149.
-
[9]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Washington: IEEE, 2016: 779-788.
-
[10]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//Proceedings of European Conference on Computer Vision. Amsterdam: ECCV, 2016: 21-37.
-
[11]马静怡, 崔昊杨. 基于改进RPN网络的电力设备图像识别方法研究[J]. 供用电, 2020, 37(1): 57-61.


