|
|
|
发布时间: 2021-06-25 |
图像技术 |
|
|
|


|
收稿日期: 2020-02-28
中图法分类号: TP311.1;TM08
文献标识码: A
文章编号: 2096-8299(2021)03-0303-05
|
摘要
在工人伤亡事故中头部受伤占伤亡事故的绝大部分。针对工人安全帽检测传统方法与检测场景关联性低、实用性差等问题,提出了一种采用面部特征与神经网络相结合的算法。该算法以多任务级联卷积神经网络(MTCNN)提取脸部特征与VGG深度卷积神经网络相结合进行安全帽检测,并且检测模型占用内存小、识别准确性高、算法实用性强,能有效监督安全帽佩戴情况,给工人施工提供安全保障。
关键词
安全帽检测; 卷积神经网络; 面部特征
Abstract
In worker casualties, head injuries account for the vast majority of casualties.Aiming at the problems of worker safety helmets with low correlation between traditional methods and detection scenarios and poor practicability, this paper proposes an algorithm that combines facial features and neural networks.The algorithm uses MTCNN to extract facial features and VGG convolutional neural networks to detect helmets.The detecting model is of small memory consumption high detection accuracy, and strong algorithm practicability.It can effectively supervise the wearing of helmets and provide workers with construction security guarantee.
Key words
hard hat detection; convolutional neural network; facial features
在我国, 大量的施工工人在施工场所进行长时间的劳动工作。由于施工工人自身安全意识薄弱, 应急处置能力亟待提高[1], 在施工场所难免出现意外事故, 其中施工工人头部受伤是造成伤亡的主要原因之一。安全帽能给施工工人一定程度的安全防护, 是施工现场必不可少的防护工具。尽管相关企业三令五申要求施工人员增强安全意识, 及时佩戴安全帽, 但由于安全意识不强, 安全帽佩戴不严格, 安全事故频频发生, 所以必须采取监督措施。现实情况中, 人工监督费时费力, 不仅造成人力资源的浪费, 而且由于场景多变及检测人员自身原因等因素很容易造成误检和漏检[2]。随着计算机技术、机器视觉和模式识别技术的发展, 安全帽佩戴自动监测及预警系统的研究成为热点。
安全帽检测作为目标检测的一种, 对于安全生产有着重要的意义和应用价值, 目前国内外学者已经做了大量的工作。杜思远[3]在背景差分法提取的前景目标基础上, 根据人体长宽比特点, 采用最小矩形图像分割法对前景目标区域进行分割, 实现作业人员安全帽佩戴状态区域的初步定位, 然后利用方向梯度直方图(Histogram of Oriented Gradient, HOG)特征的可变形部件模型完成安全帽佩戴状态识别判断。PARK M W等人[4]首先通过HOG特征提取来检测人体, 接着采用颜色直方图识别安全帽。刘晓慧等人[5]采用肤色检测的方法定位到人脸区域, 然后提取脸部以上的Hu矩特征向量, 最后利用svm完成对安全帽的识别。赵震[6]提出基于OpenCV的图形图像处理技术, 在人体识别的基础上, 辨别出施工人员安全帽配带情况, 在一定程度上降低安全隐患。但基于Haar级联分类器训练的安全帽检测算法精度低且受环境影响明显, 难以区分安全帽是否已经佩戴。李琪瑞[7]提出了基于人体识别的安全帽视频检测系统的理论和算法, 包括基于背景减除法的运动目标检测以及背景减除法的特点与适用场景, 研究了如何定位头部区域的方法以及安全帽颜色特征的计算, 但该算法的精度过于依赖人体识别的准确性, 施工作业现场环境复杂, 且设备繁多, 人体过多被设备遮挡住, 因此人体识别的准确度会低于通常状态。总之, 以上算法的实现效果可以在一定程度上满足施工场地安全帽检测的要求, 但存在检测精度较低、泛化能力差等问题, 且这些方法的共同特点是基于人为设计选取的底层特征, 采用传统的机器学习算法进行识别分类, 要求算法设计者有较高的图像知识和丰富的实验经验, 不但费时费力, 而且泛化能力较差[8]。
近年来, 随着神经网络的发展, 深度学习技术已经广受学术界和工业界的关注[9], 出现了很多基于卷积神经网络(Convolutional Neural Networks, CNN)的安全帽检测算法, 例如基于R-CNN等局部候选框分类算法或者类似于YOLO等基于端到端的目标检测算法, 由端到端模式的算法相对于前一种基于局部候选框分类的模式, 在牺牲部分精度的基础上实现实时检测速度的提高。
从目前的研究进展来看, 想要找到一种能够在无论何种场景下都能自动识别安全帽佩戴与否的算法比较困难。上班期间, 在厂区入口处集中进入的人员较多, 要求安全帽检测系统准确且速度要快; 而施工现场人员姿势不统一, 或站立或蹲着亦或互相遮挡, 给检测增加了难度。针对以上问题, 本文提出一种采用面部特征与神经网络相结合的算法, 在厂区入口处将考勤和安全帽检测功能结合在一起, 利用工人在进入厂门口时正好是正面照的特点, 基于面部特征进行脸部定位, 再利用VGG深度卷积神经网络进行安全帽佩戴检测。
1 面部检测与安全帽定位
1.1 人脸检测算法
人脸检测的目标是自动检测人脸位置, 并输出人脸框在图像中的坐标。人脸检测与识别技术在考勤、智能人机交互、固定场所出入等众多应用领域中具有重要的应用价值, 目前已成为计算机技术应用与模式识别领域中的一大研究热点。
本文采用多任务级联卷积神经网络(Multi-task Convolutional Neural Network, MTCNN)算法对人脸进行检测和关键点的粗略定位[10]。MTCNN算法稳定, 在不同光照条件、人脸较大幅度偏转、俯仰以及部分遮挡的情况下, 依然能够准确检测到人脸并实现特征点的精确定位。该算法主要有3个阶段组成: 第1阶段(P-Net), 利用浅层的CNN网络快速产生候选窗体; 第2阶段(R-Net), 通过更复杂的CNN网络精炼选择丢弃大量的候选窗体, 并根据得分高低去除重叠窗体; 第3阶段(O-Net), 再次通过CNN网络实现候选窗体精炼, 最后保留最终候选窗口并显示5个面部关键点。算法3阶段结构相似, P-Net和R-Net在产生候选框与初步筛选时只通过2个3×3卷积层, 最后在O-Net候选框精炼时通过3个3×3卷积层。具体网络结构如图 1所示。
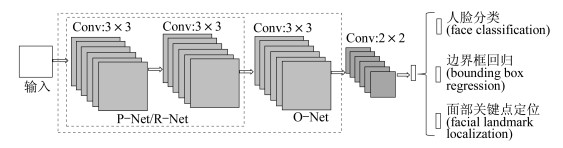

1.2 头部安全帽定位
在人脸检测完成后进行头部安全帽定位。本文设计算法不仅检测安全帽, 而且要检测安全帽是否佩戴。如果单独检测安全帽, 无法辨别安全帽是否已经佩戴(比如安全帽只是出现在施工工人手中), 就不能避免基于现象产生的误检, 因此先检测人脸矩形区域, 根据矩形区域计算人脸长度, 然后按照安全帽工业标准尺寸与人脸检测区域按比例扩大重新定义选取, 进行后续安全帽佩戴检测处理。
2 VGG深度卷积神经网络
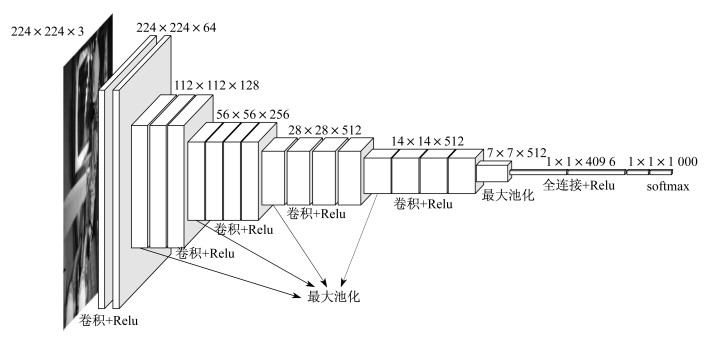
VGGNet是一种典型的图像分类网络, 是由牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司研究工作人员联合开发的深度CNN。其主要贡献是展示出网络的深度, 即算法优良性能的关键部分, 并探索了网络深度与网络性能之间的关系。较常用的有VGG16(13层conv+3层FC)和VGG19(16层conv+3层FC)。其中, VGG16网络更简单, 应用最广泛。VGGNet可以看成是加深版的AlexNet, 但不同的是VGGnet中使用的都是小尺寸的卷积核, 大小都是3×3;池化层采用统一的2×2的最大值池化, 步长为2, 通过不断加深网络结构提高性能[11]。
VGGNet中使用几个小滤波器卷积层的组合比一个大滤波器卷积层得到的效果更好。2个3×3的卷积核与1个5×5的卷积核所获得的感受野相同, 而3个3×3卷积核和1个7×7的卷积核所获得的感受野相同。虽然使用小的卷积核时, 需要的层数会更多, 但3×3涉及的学习参数更少, 层数增多可以带来更多的网络结构, 引入更多的非线性因素, 从而使网络对特征的学习能力更强, 最终使决策函数的判别力更强[11], VGGNet网络结构如图 2所示。
3 安全帽检测算法设计
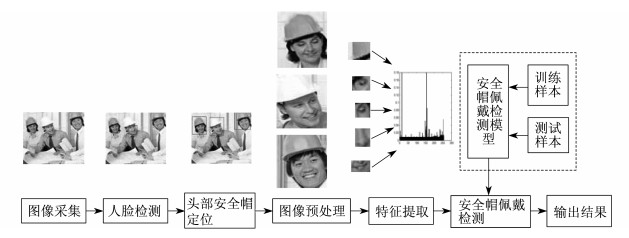
安全帽检测算法流程如图 3所示。该算法可以将动态视频数据转化为静态检测, 检测效果良好, 检测精度大幅度提高, 有效减少参数过多、内存占用过大等问题, 具有较强的实际利用价值。
4 实验结果与对比分析
4.1 实验环境及样本
实验硬件环境为Ubuntu16.04, Inter酷睿i5-8300H四核2.3GHz, 8GB RAM, NVIDIA RTX 2080ti。
本文采用的数据集来自实际工人场景图片和网络收集图片, 将图片分为佩戴安全帽与未佩戴安全帽两类, 确立数据集后通过仿射变换(旋转、加入噪声等)来扩大样本数, 最终生成4 207张可用图片。将数据集按照9∶1的比例分为训练集与测试集, 模型分别训练测试3次, 准确率取3次平均值。
在图片预处理过程中, 首先, 对图片进行尺寸处理, 尺寸大小选择为100×100, 输入VGG网络, 训练预测模型; 其次, 设置图片标签用以分类处理; 最后, 对算法的准确率、测试速度及模型的鲁棒性进行评估, 并测试算法对现场实时采集图像识别的效果。图 4为部分样本数据图片。

4.2 网络参数
4.3 实验结果
算法检测过程中, 结合MTCNN进行特征提取, 首先定位检测场景中的人脸及关键点, 同时按照比例对脸部检测框进行扩大框选, 定位安全帽位置, 以便后续进行安全帽检测。MTCNN检测当前场景生成5个关键点坐标分别为(245, 168), (172, 118), (120, 82), (84, 56), (58, 38), 人脸关键点检测及扩大框选流程如图 5所示。

VGG网络参数在训练初期随着迭代次数的增加, 损失下降速度较快, 后期损失下降速度变慢并逐渐趋于平稳。对训练模型进行测试, 3次测试结果如表 2所示。
表 2
安全帽佩戴测试结果
| 测试 | 训练样本数 | 测试样本数 | 准确率/% |
| 测试1 | 2 510 | 1 697 | 99.18 |
| 测试2 | 2 139 | 1 223 | 99.05 |
| 测试3 | 1 737 | 1 174 | 99.02 |
由表 2可知, 测试结果良好, 网络预测准确率较高。对被检测人员进行了面部检测以及扩大框选处理后输入已训练好的神经网络模型中进行安全帽佩戴识别。实时检测效果如图 6所示。

通过图 6中检测效果可以看出, 得出了正确的识别结果。
4.4 实验对比
实验过程中MTCNN 3部分P-Net, R-Net, O-Net模型所需储存空间分别为56 kB, 429 kB, 1.52 MB, 安全帽检测模型97 MB, 总计占用内存空间99 MB。实验采用文献[12]中的YOLOv3和文献[13]中的Faster rcnn目标检测算法与本文提出的算法进行对比, 以模型体积(Size)和每秒识别的帧数(FPS)作为评价标准。测试结果如表 3所示。
表 3
测试结果
| 算法 | Size/MB | FPS/(帧·s-1) |
| YOLOv3 | 237 M | 26.37 |
| Faster rcnn | 522 M | 18.8 |
| 本文提出的算法 | 99 M | 39.35 |
由表 3可以看出, 本文提出的算法模型更小, 检测帧率更高, 更加适合实际检测场景。实验过程中, 通过与文献[6]中采用OpenCV级联分类器检测算法进行对比发现, 本文提出的算法优点比较明显。OpenCV级联分类器训练网络检测时只针对安全帽, 无法辨别安全帽是否已经佩戴, 若安全帽只是出现在施工工人手中, 基于此类算法便会出现误检现象, 而本文提出的算法将面部特征与安全帽特征联合进行检测, 有效避免此类情况的发生, 使用MTCNN进行面部信息采集, 准确率高, 结合神经网络进行安全帽检测效果良好。同时, 通过OpenCV级联分类器进行训练难以附加施工现场所需的其他功能, 比如身份信息、疲劳检测、性别等, 而本文算法充分与考勤工作系统相结合, 实现系统功能丰富的同时增强工人工作的安全性, 更符合实际环境需求。
5 结论
本文在人脸检测的基础上提出了安全帽自动检测算法, 得出如下结论。
(1) 实验使用tensorflow与keras进行VGG神经网络搭建。对采集到的图片进行数据处理与数据增强, 建立数据集进行训练与测试, 检测模型占用内存小, 识别准确率高, 所以可以有效对施工人员进行安全帽检测, 改善施工现场安全状况, 给予施工人员更多的安全保障。
(2) 结合面部特征进行检测可以实时准确地对视频中出现的工作人员进行安全帽检测, 并确定人员信息, 在实际应用中具有可行性, 同时可以在识别系统中添加多重特征辅助定位、多人检测、疲劳检测、工人身份信息等功能, 将更有利于保障施工工人的人身安全, 给施工工人提供有序的工作环境。
参考文献
-
[1]王海峰, 吕政权, 陈怡君, 等. 典型电力安全突发事件演化及推演方法研究[J]. 上海电力学院学报, 2019, 35(5): 459-464. DOI:10.3969/j.issn.1006-4729.2019.05.010
-
[2]黄愉文, 潘迪夫. 基于并行双路卷积神经网络的安全帽识别[J]. 企业技术开发, 2018, 37(3): 24-27.
-
[3]杜思远. 变电站人员安全帽佩戴识别算法研究[D]. 重庆: 重庆大学, 2017.
-
[4]PARK M W, PALINGINIS E, BRILAKIS I. Detection of construction workers in video frames for automatic initialization of vision trackers[C]//Construction Research Congress. West Lafayette, Indiana, USA, 2012: 940-949.
-
[5]刘晓慧, 叶西宁. 肤色检测和Hu矩在安全帽识别中的应用[J]. 华东理工大学学报(自然科学版), 2014(3): 99-104.
-
[6]赵震. 基于OpenCV的人体安全帽检测的实现[J]. 电子测试, 2017(14): 26-27. DOI:10.3969/j.issn.1000-8519.2017.14.012
-
[7]李琪瑞. 基于人体识别的安全帽视频检测系统研究与实现[D]. 成都: 电子科学大学, 2017.
-
[8]徐守坤, 王雅如, 顾玉宛, 等. 基于改进Faster RCNN的安全帽佩戴检测研究[J]. 计算机应用研究, 2020, 37(3): 267-271.
-
[9]曹渝昆, 何健伟, 鲍自安. 深度学习在电力领域的研究现状与展望[J]. 上海电力学院学报, 2017, 33(4): 341-345. DOI:10.3969/j.issn.1006-4729.2017.04.007
-
[10]XIANG J, ZHU G. Joint face detection and facial expression recognition with MTCNN[C]//20174th International Conference on Information Science and Control Engineering. Changsha, China: IEEE, 2017: 424-427.
-
[11]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014(15): 1556-1563.
-
[12]REDMON J, FARHADI A.YOLOv3: an incremental improvement[EB/OL].(2018-04-08)[2020-02-20].https://arxiv.org/pdf/1804.02767.pdf.
-
[13]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.


