|
|
|
发布时间: 2022-02-28 |
智能电网技术 |
|
|
|


|
收稿日期: 2020-02-24
基金项目: 国家自然科学基金(61672337)
中图法分类号: TP391.4
文献标识码: A
文章编号: 2096-8299(2022)01-0040-08
|
摘要
在遮挡物较多的变电站场景下, 传统的目标跟踪算法容易出现人员跟丢、身份变换、目标被遮挡无法识别等情况, 无法做到对目标的准确实时跟踪。针对此问题, 提出了融合度量学习与卡尔曼滤波的变电站运动目标跟踪方法。首先, 采用融合多尺度特征的YOLOv3算法检测目标, 利用带权值的匈牙利算法匹配目标的历史运动轨迹; 然后, 通过卡尔曼滤波进行轨迹预测, 并应用度量学习匹配预测轨迹与历史运动轨迹, 结合目标外观特征信息, 以实现变电站内运动目标的跟踪; 最后, 以变电站场景下的人员为例进行实验, 结果表明, 人员跟踪准确率高, 且能满足变电站应用场景下的鲁棒性和实时性要求。
关键词
多尺度特征; 人员跟踪; 度量学习; 卡尔曼滤波; 变电站场景
Abstract
The traditional target tracking algorithm is easy to have tracking loss, identity transformation and other situations in the substation scene with more obstructions, so it can't track the target accurately in real time.To solve this problem, a method of moving target tracking in substation is proposed, which combines metric learning and Kalman filter.In this method, firstly, You Only Look Once algorithm is used to detect the target, and then Hungary algorithm with weights is used to match the historical trajectory of the target, then Kalman filter is used to predict the trajectory, and metric learning is used to match the predicted trajectory with the historical trajectory, and the tracking of the moving target is realized in the substation combined with the appearance feature information of the target.Taking the personnel in the substation as an example, the experiment shows that the method has high tracking accuracy and can meet the requirements of robustness and real-time in the substation application scenario.
Key words
multi-scale feature; human tracking; metric learning; Kalman filter; substation scene
近年来, 随着智能电网的提出及快速发展, 无人值守或少人值守变电站在一定程度上决定了电网的智能化发展, 而变电站场景下的运动目标检测和跟踪技术是实现变电站无人值守或少人值守的必要条件[1]。通过对变电站场景内移动目标(例如人员、动物或者车辆等)的自动检测和跟踪, 可以解决当前变电站内存在的安全隐患[2], 同时也能快速准确地检测出变电站由移动目标的非法侵入、无意进入警戒区域或禁止区域以及未穿着安全服造成的安全问题, 提高变电站的自动识别水平并进行实时预警, 极大地降低了监控人员的工作量, 为电力系统安全提供了充分的保障。在目标跟踪问题中, 算法需要根据每一帧图像中目标的检测结果, 匹配已有的目标轨迹; 对于新出现的目标, 需要生成新的目标; 对于已经离开摄像机视野的目标, 需要终止轨迹的跟踪。
文献[3]采用Siamese对称卷积网络训练并计算两个输入图像的匹配程度, 通过基于梯度下降提升算法的分类器将目标的运动信息与相似度相融合, 最后利用线性规划优化算法得到多目标跟踪结果。文献[4]针对多目标跟踪中的互相遮挡问题, 提出了基于时间空间关注模型(Spatial-Temporal Attention Mechanism, STAM)用于学习遮挡情况, 并判别可能出现的干扰目标。文献[5]设计了基于长短期记忆循环网络模型的特征融合算法来学习目标历史轨迹信息与当前检测之间的匹配相似度。文献[6]提出卷积网络递归训练跟踪方法(Sequentially Training Convolutional Tracking, STCT), 将卷积神经网络(Convolutional Neural Network, CNN)看成一个整体, 每个通道的卷积层被看作一个基学习器, 通过新的loss独立更新, 将在线跟踪转化成了每个整体中的前景背景分割问题。文献[7]提出了一种基于非稀疏线性表示的视觉跟踪器, 以在线方式学习马氏距离度量, 并将学习到的度量合并到优化问题中获得线性表示。
综上所述, 目前多目标跟踪算法主要是融合多种信息, 如目标的运动信息、外观信息, 以及交互信息等来对跟踪目标进行跟丢的再识别。本文算法也采用这一思路, 以融合变电站内移动目标的运动及表观信息的方式来实现对目标的跟踪。
针对变电站中可能出现的遮挡问题, 本文提出了一种融合度量学习与卡尔曼滤波[8]的变电站内目标跟踪方法。该方法首先采用融合多尺度特征的实时目标检测算法YOLOv3(You Only Look Once, YOLO)[9]对变电站内运动目标进行检测, 然后结合目标的运动信息和外观信息实现对运动目标的跟踪。实验证明, 该方法准确率高, 且能满足变电站应用场景下的鲁棒性和实时性要求。
1 算法描述
变电站运动目标跟踪算法流程如图 1所示。
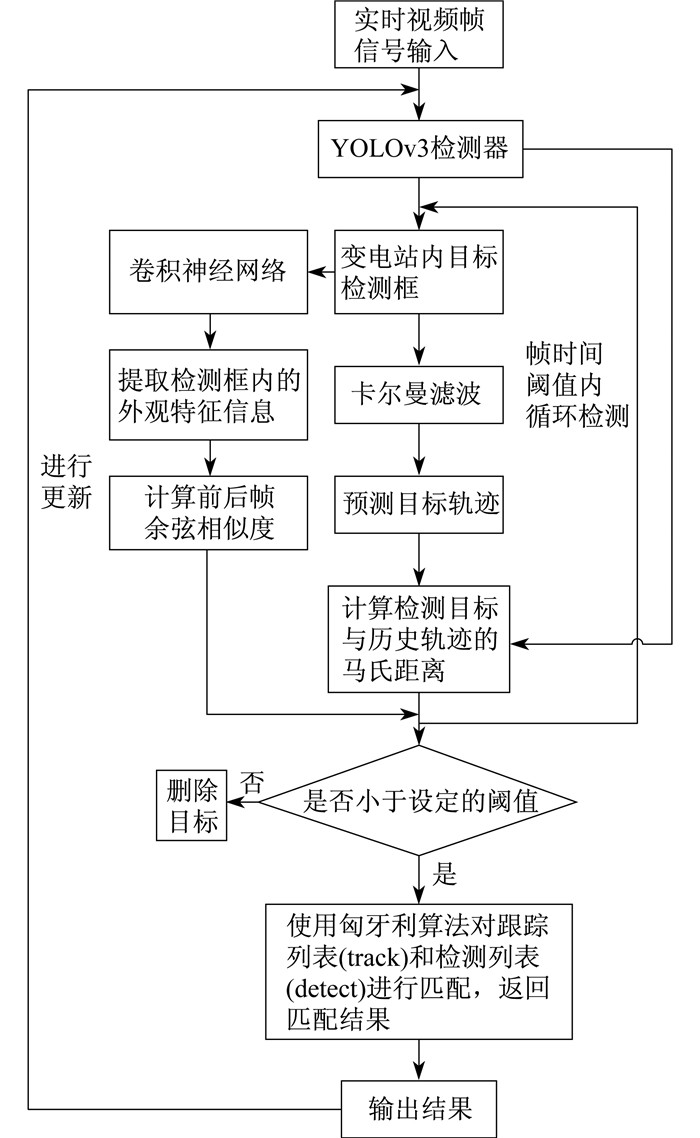

首先, 对输入的实时视频帧信号进行简单的预处理, 再通过融合多尺度特征的实时目标检测算法YOLOv3对变电站内运动目标进行检测, 从而得到视频序列中目标的检测框, 并建立与其对应的跟踪列表。同时采用预训练好的卷积神经网络提取目标检测框内的外观特征信息, 计算当前目标外观特征信息与之前帧目标的平均外观特征信息的余弦距离。然后, 采用卡尔曼滤波算法对检测到的运动目标进行轨迹预测, 用马氏距离来表示目标的预测状态与目前状态之间的运动匹配程度。最后, 通过匈牙利算法对之前的运动轨迹和当前检测对象进行匹配, 形成目标的运动轨迹。针对遮挡问题, 本文设定了帧时间的阈值, 该阈值的意思是若当前帧时间与目标在上一次成功匹配到的帧时间之差大于阈值的话, 就认为目标的轨迹终止, 在后续的跟踪中删除目标轨迹, 如果小于的话就认为该目标轨迹没有丢失。
2 变电站运动目标检测
在变电站场景中, 由于摄像机的安装高度较高, 并且需要实时监控变电站内运动目标来保证站内人员及财产的安全, 所以需要采用实时性与检测小目标效果比较好的检测算法。为了提升目标检测定位与分类精度, YOLOv3算法融合了多尺度特征, 设计了更深的卷积神经网络作为骨干网络, 一共有53个卷积层, 命名为Darknet-53。YOLOv3模型结构如图 2所示, 主要由Darknet-53特征提取网络、多尺度融合特征网络构成。y1, y2, y3代表YOLOv3在3种不同尺度特征图的输出、输出目标位置和类别。Darknet-53主要由53个卷积层构成, 大量地采用3×3和1×1的卷积核, 同时借鉴深度残差网络(ResNet)的设计思想, 在卷积层间构建残差模块并设置跳跃连接。具体结构如图 3所示。
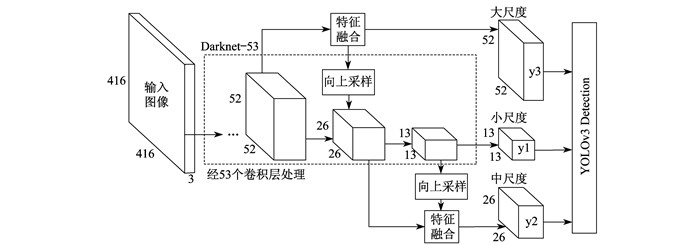

YOLOv3采用3种不同尺度的预测结果, 对于输入的变电站实时视频图像信息, 例如输入416×416的图像信息, 基础特征图尺度为13×13×N, 通过上采样得到26×26×N的特征图, 将它与前一卷积层输出融合得到第2个尺度特征图 26×26×M; 之后采用相同的方法得到第3个尺度特征图 52×52×W; 在每个特征图上预测由检测框、目标评分、类别预测3种信息编码的3d张量。检测时采用9个聚类获得的先验框辅助进行坐标的预测, 并将这9个先验框分为3组应用在3个不同尺度的特征图中, 使得每个尺度特征图预测3组信息, 最后采用逻辑回归的方式对每个检测框的预测目标打分。
3 变电站运动目标跟踪
本文基于YOLOv3检测到目标的坐标信息(x, y, w, h)以及图像中的目标检测框信息, 采用卡尔曼滤波对检测到的运动目标进行轨迹预测, 应用度量学习将预测轨迹与目标运动轨迹进行匹配, 结合通过检测提取到的目标表观特征信息, 实现对变电站内运动目标的跟踪。
3.1 卡尔曼滤波器预测过程
选取变电站内的运动目标作为跟踪对象, 以检测框底边中点(dx(k), dy(k))作为跟踪的特征点, 同时选取检测框的长度w和高度h作为另两个特征变量, 共同构成一个四维状态变量, 进而利用卡尔曼滤波算法的工作流程预测底边中点和检测框的长度w和高度h这个四维状态变量。卡尔曼滤波的工作过程如图 4所示。

图 4中: X′k-1为历史状态变量值; X′k, k-1为状态变量预测值; Pk为历史状态变量值的协方差; Pk, k-1为状态变量预测值的协方差; A和B为状态估计矩阵; H为观测矩阵; Q和R分别为其协方差矩阵; uk为c维向量; Zk为下一时刻的状态观测量。
具体步骤如下。
步骤1 对模型进行初始化。假设输入控制的c维向量uk的误差是方差为1的高斯白噪声, 协方差矩阵Q和R及A和H是对角线为1的单位阵, 模型中位置的初始值为目标初始检测框底边中点坐标(dx(k), dy(k)), 检测框长度w和高度h的初始值为目标初始检测框的长度和高度, 速度变量初始值为零。
步骤2 状态与目标位置预测。计算状态变量和误差协方差, 同时用观测值对预测值进行调整, 得出最优观测值。
步骤3 状态更新。更新状态变量, 然后回到步骤2, 开始下一次的目标位置预测。
3.2 度量学习
本文将视频前后帧检测到的目标看成两个独立的对象, 采用度量学习的方法, 结合运动信息和外观信息计算前后帧两个独立对象的关联程度, 同时引入权重系数κ且设定阈值, 从而实现对变电站内运动目标的跟踪。
3.2.1 运动信息
考虑到当前帧的检测目标状态是由四维状态变量构成, 因此本文采用马氏距离来对当前帧的检测目标和历史目标轨迹进行相似度度量。
本文是要计算第i帧检测到的目标与第i-1帧目标在卡尔曼滤波器预测目标的马氏距离M(i-1, i), 即
| $ M(i - 1, i) = \sqrt {{{\left( {{t_i} - {g_{i - 1}}} \right)}^{\rm{T}}}\mathit{\boldsymbol{S}}_{i - 1}^{ - 1}\left( {{t_i} - {g_{i - 1}}} \right)} $ | (1) |
式中: ti——第i帧检测到的目标状态(dx(k), dy(k), w, h);
gi-1——第i-1帧目标轨迹在第i帧的预测观测量;
Si-1——目标轨迹由卡尔曼滤波器预测得到的在第i帧时观测空间的协方差矩阵。
由于视频帧中的运动是连续的, 故可以采用马氏距离M(i-1, i)对检测到的目标进行筛选, 设定3.08作为筛选的阈值, filter为筛选函数。
| $ \begin{array}{l} \;\;\;\;\;\;\;\;a(i - 1, i) = \\ \left\{ {\begin{array}{*{20}{c}} {{\rm{filter}}(M(i - 1, i) \le 3.08)}&{i \ge 2}\\ 0&{0 < i \le 0} \end{array}} \right. \end{array} $ | (2) |
3.2.2 外观信息
变电站内电气设备众多, 若单独采用马氏距离进行度量匹配的话, 不能解决站内出现的遮挡问题, 此时就需要依靠外观信息进行补救。对于每帧检测到的目标检测框, 我们利用深度卷积神经网络提取出检测框中的特征向量来代表外观信息, 然后使用余弦距离作为度量函数。
余弦距离的表示方法为
| $ \cos \;{\mathop{\rm dis}\nolimits} ( \cdot ) = 1 - \frac{{\sum\limits_{i = 1}^n {{\mathit{\boldsymbol{A}}_i}} {\mathit{\boldsymbol{B}}_i}}}{{\sqrt {\sum\limits_{i = 1}^n {\mathit{\boldsymbol{A}}_i^2} } \cdot \sqrt {\sum\limits_{i = 1}^n {\mathit{\boldsymbol{B}}_i^2} } }} $ | (3) |
式中: A, B——属性向量。
本文采用特征提取的网络是深度卷积神经网络, 以变电站人员为例提前在一个大规模的行人数据集上预训练得到了外观模型, 输出256维的特征向量ri, 网络结构如表 1所示。
表 1
深度卷积神经网络结构
| 层 | 卷积核 | 步长 | 输出大小 |
| 卷积层1 | 3×3 | 1 | 32×128×64 |
| 卷积层2 | 3×3 | 1 | 32×128×64 |
| 卷积层3 | 3×3 | 1 | 32×128×64 |
| 最大池化层4 | 3×3 | 2 | 32×64×32 |
| 残差块5 | 3×3 | 1 | 32×64×32 |
| 残差块6 | 3×3 | 2 | 64×32×16 |
| 残差块7 | 3×3 | 2 | 128×16×8 |
| 残差块8 | 3×3 | 2 | 256×8×4 |
| 全连接层 | 256 | ||
| 批量正则化 | 256 |
对于b物体第i帧之前每帧的特征向量rk(b), 创建一个集合{r1(b), r2(b), r3(b), …, rk(b)}。考虑到是连续跟踪, 可能会因为跟踪时间长导致人员外观特征发生变化, 故只保留b物体第i帧之前f次成功跟踪后物体检测框对应的特征向量均值, 即
| $ \mathit{\boldsymbol{\overline r}} _k^{({\rm{b}})} = \frac{{\sum\limits_{k = 1}^f {\mathit{\boldsymbol{r}}_k^{({\rm{b}})}} }}{f} $ | (4) |
余弦距离为
| $ \cos \;{\mathop{\rm dis}\nolimits} (k, i) = 1 - \mathit{\boldsymbol{r}}_i^{\rm{T}}\mathit{\boldsymbol{\overline r}} _k^{({\rm{b}})} $ | (5) |
同理, 余弦距离度量同样需要设定一个阈值t, 此阈值通过训练得到, 当两者的余弦距离小于特定阈值t, 则表示两者关联成功, 即
| $ c(k, i) = {\rm{ filter}}\{ \cos \;{\mathop{\rm dis}\nolimits} (k, i) \le t\} $ | (6) |
3.2.3 融合度量学习
采用融合度量学习的方法, 设置权重系数κ, 对两种度量方式进行加权平均, 即
| $ u = \mathit{\kappa }a(i - 1, i) + (1 - \mathit{\kappa })c(k, i) $ | (7) |
最终采用匈牙利算法[10]对track和detect进行最优分配。
3.3 跟踪算法实现过程
融合度量学习与卡尔曼滤波的变电站运动目标跟踪算法流程如下。
步骤1 检测变电站运动目标。采用YOLOv3算法对实时视频帧信号进行检测。将当前帧检测到的目标坐标信息存入detection集合中, 将历史检测到的目标坐标信息存入track集合中。如果detection集合为空集, 就将丢失帧计数加1, 若丢失帧计数超过设定阈值时, 就认为该目标已消失, 然后将该目标的历史坐标信息从track中删除, 重新进行检测。如果detection集合不为空, 将丢失帧数计数置为零, 继续下一步。
步骤2 卡尔曼滤波器进行预测。使用一个基于匀速模型和线性观测模型的标准卡尔曼滤波器对目标的运动状态进行预测, 也即对track集合进行预测得到包含预测结果的track_pre集合。
步骤3 融合运动信息与外观信息计算detection与track的距离。同时计算包含track预测结果的track_pre集合与detection集合之间的马氏距离以及detection中提取到的特征向量与历史轨迹track中提取到的特征向量平均值的余弦距离。
步骤4 分配及更新。若步骤3计算的距离大于设定的阈值, 则从track中删除目标; 若小于设定的阈值, 则说明前后帧目标匹配成功, 采用匈牙利算法对track和detect进行最优分配, 并返回匹配结果, 使用匹配成功点的坐标信息来对目标位置进行更新, 重复步骤1, 从而实现对变电站内运动目标的跟踪。
4 实验及结果分析
4.1 实验数据及环境
以变电站内运动的人员为例, 将采集到的变电站监控视频分成两组, 光照条件相同, 但是遮挡情况不同, 以评价变电站内运动目标跟踪方法的性能, 详细参数如表 2所示。其中: 视频1的遮挡物较少, 环境较为空旷; 视频2的遮挡物较多, 环境较为复杂。
表 2
变电站场景数据集情况统计表
| 视频 | 视频时间/s | 帧数/帧 | 平均人数/人 | 光照 | 摄像机向下倾斜角度/(°) |
| 1 | 42.0 | 631 | 5 | 较强 | 向下30° |
| 2 | 52.8 | 793 | 2 | 较强 | 向下30° |
实验选用性能比较高的图形处理服务器, 其基本配置是Intel(R) Core(TM) i7-8086K CPU @ 4.00 GHz, 基于x64的处理器, 16 G内存, GPU为RTX2080 Ti; 算法开发使用Linux操作系统、Python语言和TensorFlow框架。
4.2 实验结果分析
将本文的跟踪算法分别在2组变电站监控视频中进行实验。考虑到算法的实时性, 本文采用的图像为灰度化之后的图像(本文算法也适用于彩色图像)。图 5和图 6为本文算法在2组视频中的跟踪效果。


从图 5可以看出, 监控视频1在遮挡情况不严重的情况下, 能够实现变电站多名工作人员的精准跟踪, 虽然出现了少许的人员交叉、重叠及遮挡的情况, 但是也能实现对人员的再跟踪。
从图 6可以看出, 监控视频2中的绝缘子、杆塔比较多, 造成的遮挡情况比较严重。但本文算法在遮挡严重的情况下, 依然能实现对于人员的精准跟踪。由于本文算法不单单只有人员的运动信息, 还有外观信息, 增强了人员丢失再识别的能力, 具有很强的鲁棒性。
本文的跟踪算法能够实现多目标在线跟踪, 因此为了验证本文算法, 根据多目标跟踪算法评价指标: 多目标跟踪准确率(MOTA)、所有跟踪目标的平均边框重叠率(MOTP)、目标大部分被跟踪到的轨迹占比(MT)、目标大部分跟丢轨迹占比(ML)、一条跟踪轨迹改变目标标号的次数(IDS)及每秒传输帧数(FPS)作为实时性指标, 来分析不同多目标在线跟踪算法在2组变电站监控视频上的性能, 结果如表 3和表 4所示。表 3和表 4中: ↑表示得分越高越好; ↓表示得分越低越好; *表示每个视频对应的每项指标最优算法。
由表 3和表 4可知, 本文算法在遮挡物较少的变电站监控视频1中, 跟踪精度相较于文献[11]算法、文献[12]算法和文献[4]算法更好, 略低于文献[5]算法, 但在跟踪的实时性方面远远超过了文献[5]算法, 也比其他算法效果更好。在遮挡物较多的监控视频2中, 本文算法的跟踪准确率比其他4种算法中准确率最低的文献[11]算法要高14.8%, 相较于视频1中效果较好的文献[5]算法, 准确率只低了0.3%, 但实时性却高出近7倍, 同时在遮挡物比较多的情况下, 人员ID转换次数相较于其他算法也较少。由此可知, 在变电站场景下对人员进行跟踪时, 本文算法能够获得较好的跟踪效果, 同时具有很强的鲁棒性和实时性。
表 3
跟踪器在视频1下的跟踪性能(遮挡物较少)
5 结语
本文提出的融合度量学习与卡尔曼滤波的变电站人员跟踪方法, 结合了人员的运动信息和外观信息, 实现了对变电站内人员轨迹的描绘。引入了YOLOv3算法和卡尔曼滤波器, 前者通过对混合数据集的训练, 提升了变电站内人员检测的准确性, 后者对检测到人员的状态进行预测, 并结合卷积神经网络提取到人员的外观信息, 刻划出变电站内人员的运动轨迹, 也能较好地解决变电站内复杂的遮挡情况。实验结果表明, 本文算法跟踪的实时性较好, 同时在复杂环境下的鲁棒性较强, 能有效地应用于现实场景。本研究是在变电站可视条件较好的情况下开展的, 未开展可视条件不佳情况下的人员跟踪。后续工作将融合图像处理技术, 对变电站内可视条件不佳情况下的人员跟踪问题开展深入研究。
参考文献
-
[1]顾波, 刘新宇, 张红涛. 复杂环境下变电站运动目标跟踪技术研究[J]. 电测与仪表, 2012, 49(1): 63-66.
-
[2]李祥, 崔昊杨, 曾俊冬, 等. 变电站智能机器人及其研究展望[J]. 上海电力学院学报, 2017, 33(1): 15-19.
-
[3]LEAL-TAIXÉ L, CANTON-FERRER C, SCHINDLER K. Learning by tracking: siamese CNN for robust target association[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Las Vegas, NV, USA: IEEE 2016: 418-425.
-
[4]CHU Q, OUYANG W, LI H, et al. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE. 2017: 4846-4855.
-
[5]SADEGHIAN A, ALAHI A, SAVARESE S. Tracking the untrackable: learning to track multiple cues with long-term dependencies[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE. 2017: 300-311.
-
[6]WANG L J, OUYANG W L, WANG X G, et al. STCT: sequentially training convolutional networks for visual tracking[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE. 2016: 1373-1381.
-
[7]LI X, SHEN C H, SHI Q F, et al. Non-sparse linear representations for visual tracking with online reservoir metric learning[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE. 2012: 1760-1767.
-
[8]STEPANOV O A. Kalman filtering: past and present.An outlook from Russia[J]. Gyroscopy and Navigation, 2011, 2(2): 99-110.
-
[9]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE. 2016: 779-788.
-
[10]张旭辉, 朱宏辉, 郑启忠. 最优指派问题匈牙利算法的探讨与C_(++)实现[J]. 物流技术, 2004(5): 72-74.
-
[11]BAN Y T, BA S, ALAMEDA-PINEDA X, et al. Tracking multiple persons based on a variational bayesian model[M]. European Conference on Computer Vision. Cham, Switserland: Springer International Publishing, 2016: 52-67.
-
[12]SANCHEZ-MATILLA R, POIESI F, CAVALLARO A, et al. Online multi-target tracking with strong and weak detections[M]. European Conference on Computer Vision. Cham, Switserland: Springer International Publishing, 2016: 84-99.


