|
|
|
发布时间: 2024-04-28 |
其他研究 |
|
|
|


|
收稿日期: 2023-12-26
中图法分类号: TM02
文献标识码: A
文章编号: 2096-8299(2024)02-0185-06
|
摘要
在核电企业数字化转型过程中,人工识别图纸误差较高,易造成企业损失,有必要利用自动化提取表格信息技术代替人工。表格结构识别是表格信息提取的关键技术,但核电施工图纸表格结构复杂且样本少,影响了识别效果。针对这一问题,提出了结合高效注意力机制的多尺度扩展模型EPNet,引入了渐进式尺度扩展模块,增强了有效特征通道权重,实现了少样本的有效特征信息获取。另外,利用局部特征中的文本区域和全局特征中单元关系的视觉信息来获得可靠的单元格边界,提高边缘拟合的精细度。实验结果表明,该模型在识别核电施工图纸中的表格单元格结构方面表现出色,与Mask R-CNN模型相比,精确度提高了1%,F1值提高了3%,具有较高的准确性和鲁棒性。
关键词
核电施工图纸; 表格; 单元格结构; 多尺度特征
Abstract
Table structure recognition is a key technology for table information extraction. The structure of the table of nuclear power construction drawings is complex and the sample is small, which affects the recognition effect. To solve this problem, EPNet, a multi-scale extension module combined with efficient attention, is proposed, and a progressive scale expansion module is introduced to enhance the weight of effective feature channels and realize the acquisition of effective feature information with fewer samples. The visual information of the text area in the local feature and the cell relationship in the global feature is used to obtain reliable cell boundaries and improve the fineness of edge fitting. Experimental results show that the proposed model performs well in identifying the table cell structure in nuclear power drawings, and the accuracy is improved by 1% and the F1 value is increased by 3% compared with the previous algorithm, which has high accuracy and robustness.
Key words
nuclear power construction drawings; table; cell structure; multi-scale features
在数字化转型的时代背景下,用数字化技术驱动业务变革是核电企业必然的发展战略[1]。核电企业经常使用光栅图作为作业信息的载体,在企业数字化转型过程中,越来越多的数据需要从光栅图纸中提取,而传统的人工提取方式,容易出现信息提取错误、效率低下等问题。随着人工智能技术的发展,自动识别并提取核电施工图纸中的作业信息,对核电企业的数字化施工具有重要意义。
目前,国内外提出了诸多方法来解决表格结构识别问题。文献[2]提出了一种基于语义分割的表格结构识别方法,通过语义分割得到表格中列的位置信息,并使用启发式方法得到行信息。文献[3]提出了一种分割‒合并模型,首先将表格图像进行细致分割,然后对分割结果进行同行、列的合并,由此得到表格结构信息。文献[4]提出了使用循环卷积网络进行表格结构识别,利用分割行列分隔符的方法获取表格结构信息。文献[5]提出了基于Faster R-CNN结构的端到端系统DeepDeSRT,利用深度学习技术对文档图像进行处理,采用可变卷积网络检测行、列、单元格,并根据单元格的特点恢复单元格结构。文献[6]提出了一种基于目标检测的模型,以各目标框的中心点为基础,推理出边界框尺寸和位置信息,从而获得表格的结构信息。文献[7]研究了一种直接定位表格中单元格边界的方法,但该方法需要额外的后处理步骤。文献[8]将图神经网络(Graph Neural Network,GNN)引入表格结构识别领域,在对表格进行图建模的基础上,使用GNN预测文本块之间的同行、同列、同单元格关系,以此得到表格结构。文献[9]在光学字符识别(Optical Character Recognition,OCR)的基础上建立图模型,用以预测文本块间的行、列位置关系。
上述表格识别方法均是针对样本数量充足的规则表格,对于有密集单元格、无框线、单元格跨行跨列等非规则的表格研究依旧欠缺。本文研究的非规则表格指的是结构复杂的核电施工图纸中的材料表。由于核电行业的特殊性,无法获取大量的表格样本,且核电施工图纸的材料表是包含大量密集单元格的复杂结构,导致了现有的表格信息提取方法在核电施工图纸上表现不佳。
针对上述问题,本文提出了结合高效注意力机制的多尺度扩展模型EPNet,在主干网络中加入渐进式尺度扩展模块(Progressive Scale Expansion,PSE),检测核电施工图纸材料表中的密集单元格。引入高效注意力机制,解决了现有核电施工图纸表格样本数量少导致密集单元格检测效果不佳的问题,从而实现了少样本条件下核电施工图纸材料表格的单元格结构识别。
1 问题描述与数据集介绍
1.1 问题描述

1.2 数据集介绍
目前,表格分析领域的竞赛数据集和公开数据集内容包括:扫描页面图像,如UNLV[11](2010)、FUNSD[12](2019)、Tablebank[13](2020)等;文档页面图像,如ICDAR2019[14](2019)、WTW[6](2021)、PubTabNet[15](2020)、FinTab[9](2021)等;电子表格,如ICDAR2013[16](2013)、DECO[17](2019)等。但是上述数据集中缺少工程图纸类表格图像数据集,并且缺少针对表格单元格结构识别的标注样本。
本文收集了800份核电施工图纸材料表。这些表格均来自实际的核电建造工程项目,保证了数据集的真实性。对收集到的表格进行数据清洗和预处理操作,去除重复和损坏的表格,以确保数据集的质量和一致性。对每个表格样本进行人工标注,包括标记单元格、边界和内容信息,为后续的算法训练和评估提供准确的标签数据。本文将上述表格数据集命名为E‒Tab数据集。
2 模型设计及方法改进
2.1 EPNet模型
EPNet模型网络结构如图 2所示。其中,Fv1、Fv2、Fv3、Fv4为通道特征图;G为全局平均池化操作;σ为sigmoid函数;
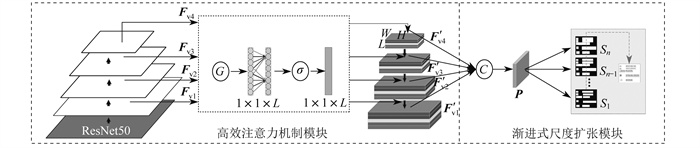

2.2 渐进式尺度扩展模块
在图像处理任务中,采集多尺度信息对于提高模型鲁棒性等性能是至关重要的,而传统的单一尺度处理方法往往会忽视图像中不同尺度的细节和上下文信息,从而导致模型性能下降。引入渐进式尺度扩展模块可以在不同尺度上逐步扩展、递增模型的感受野,从而更好地捕捉和利用图像的多尺度信息。具体来说,渐进式尺度扩展模块一般由多个尺度的卷积层或特征提取器组成,每个尺度对应一种不同的感受野大小,用于进行特征提取。本文使用ResNet50[19]作为图像特征提取模块,通过深度架构,ResNet50可以学习到更丰富、更高级的图像特征,从而提供更准确的表示能力。渐进式尺度扩展模块结构如图 3所示。其中,RPN(Region Proposal Network)为候选框生成网络,ROI Align为双线性插值算法,Head为目标检测头,FC(Fully Connected Layer)为全连接层。
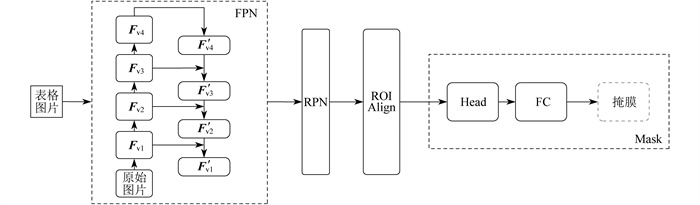
由ResNet50提取4个不同尺度的通道特征图:
| $ \begin{gathered} \boldsymbol{F}_{\mathrm{v} 1} \in \mathbf{R}^{\frac{H}{4} \times \frac{W}{4} \times \frac{C}{4}}, \boldsymbol{F}_{\mathrm{v} 2} \in \mathbf{R}^{\frac{H}{8} \times \frac{W}{8} \times \frac{C}{8}}, \\ \boldsymbol{F}_{\mathrm{v} 3} \in \mathbf{R}^{\frac{H}{16} \times \frac{W}{16} \times \frac{C}{16}}, \boldsymbol{F}_{\mathrm{v} 4} \in \mathbf{R}^{\frac{H}{32} \times \frac{W}{32} \times \frac{C}{32}} 。\end{gathered} $ |
为了进一步将语义特征组合成更高层次的特征,采用特征融合函数将4个特征映射进行融合,得到1 024个通道的特征图P为
| $ \begin{gathered} \boldsymbol{P}=C\left(\boldsymbol{F}_{\mathrm{v} 1}, \boldsymbol{F}_{\mathrm{v} 2}, \boldsymbol{F}_{\mathrm{v} 3}, \boldsymbol{F}_{\mathrm{v} 4}\right)= \\ \boldsymbol{F}_{\mathrm{v} 1}\left\|U_{\mathrm{p} \times 2}\left(\boldsymbol{F}_{\mathrm{v} 2}\right)\right\| U_{\mathrm{p} \times 4}\left(\boldsymbol{F}_{\mathrm{v} 3}\right) \| U_{\mathrm{p} \times 8}\left(\boldsymbol{F}_{\mathrm{v} 4}\right) \end{gathered} $ | (1) |
式中:Upx2,Upx4,Upx8——2倍、4倍、8倍上采样。
这种特征融合方法能够将高层特征的语义信息与底层特征的细粒度信息融合在一起,在有效地感知图像文本块分布的同时,也保证了对文本边界更加精细的检测。
渐进式尺度扩展模块通过引入不同尺度的处理分支,逐渐扩大感受野,以捕获图像的全局信息和局部信息。但是其参数数量较多,需要通过大量样本进行调整和优化。由于核电行业的特殊性,无法获取大量训练样本,导致模型参数难以调整,无法捕捉密集单元格数据的复杂模式和深层规律,从而影响模型性能。
2.3 少样本条件下的单元格识别
由于核电行业无法获取大量训练样本,因此如何提高模型对少量样本的利用效率至关重要。本文提出的结合高效注意力机制的多尺度扩展模块EPNet是在每个特征图上应用高效注意力机制,以增强有效特征通道的权重,并融合多尺度渐进扩展模块捕获的全局和局部信息,有效提升模型性能。EPNet模块识别流程如图 4所示。
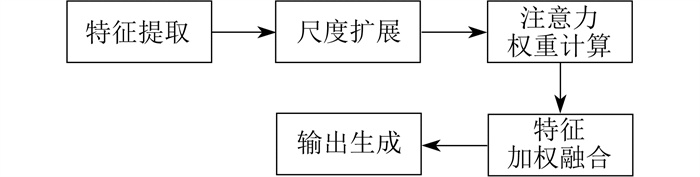
高效注意力机制能够帮助模型筛选特征中的关键信息,过滤掉无关信息[20],减少噪声和冗余,并提高模型对任务相关特征的表示能力。在自适应的注意力机制下进行权重分配,权重ω计算式为
| $ \omega=\sigma\left[\mathrm{C} 1 \mathrm{D}_k(y)\right] $ | (2) |
式中:C1Dk——卷积核大小为k的一维卷积;
y——全局平均池化结果。
在EPNet模块中,输入多尺度图像特征 Fvi (i = 1,2,3,4),对特征图进行全局平均池化操作,以及卷积核大小为k的1维卷积操作,并经过Sigmoid激活函数得到各个通道的权重ω,最终输出多尺度模态融合特征
| $ \boldsymbol{F}_{\mathrm{v} i}^{\prime}=\boldsymbol{F}_{\mathrm{v} i} \times \omega $ | (3) |
| $ \begin{gathered} \boldsymbol{P}=C\left(\boldsymbol{F}_{\mathrm{v} 1}^{\prime}, \boldsymbol{F}_{\mathrm{v} 2}^{\prime}, \boldsymbol{F}_{\mathrm{v} 3}^{\prime}, \boldsymbol{F}_{\mathrm{v} 4}^{\prime}\right)= \\ \boldsymbol{F}_{\mathrm{v} 1}^{\prime}\left\|U_{\mathrm{p} \times 2}\left(\boldsymbol{F}_{\mathrm{v} 2}^{\prime}\right)\right\| U_{\mathrm{p} \times 4}\left(\boldsymbol{F}_{\mathrm{v} 3}^{\prime}\right) \| U_{\mathrm{p} \times 8}\left(\boldsymbol{F}_{\mathrm{v} 4}^{\prime}\right) \end{gathered} $ | (4) |
这种局部性计算避免了在所有通道上的计算,参数量为通道数的k倍,计算更快捷、高效。在所有通道上共享权重信息,将4个不同权重通道的特征图融合后得到P,并利用渐进式尺度算法得到密集单元格识别结果。通过自适应的注意力权重分配,可以提高模型对少量样本的利用效率,同时提高密集单元格的识别精度,对输入的变化和干扰具有一定的鲁棒性。
3 实验结果评估
3.1 评价指标
E-Tab数据集共包含800张图纸表格图像,训练集、测试集、验证集的比例设置为600∶100∶ 100。本文实验环境为Linux系统,采用PyTorch开发框架对E-Tab数据集进行训练、验证和测试。使用计算精确率、召回率以及F1值来衡量模型的有效性,采用交并比(Intersection Over Union,IOU)作为评价指标。该评价指标的公式为
| $ K_{\mathrm{IOU}}=\frac{S_i \cap S_j}{S_i \cup S_j} $ | (5) |
式中:Si,Sj——模型的预测值和真实值。
3.2 实验结果
分别采用ReS2TIM模型[21]和文本所提EPNet模型,对表格单元格结构检测效果进行实验对比。经过模型检测后,输出表格中各个独立单元格的表格图像,并与原始表格中的单元格一一对应。实验结果如表 1所示。
表 1
两种模型的检测实验结果
| 模型 | 精确率 | 召回率 | F1值 |
| ReS2TIM | 0.929 4 | 0.710 0 | 0.805 0 |
| EPNet | 0.973 9 | 0.918 1 | 0.945 2 |
由表 1可以看出,EPNet模型的精确率、召回率和F1值均优于ReS2TIM模型。与目前常见的数据集相比,E‒Tab数据集的表格结构更加复杂,单元格格式更加多样,但EPNet模型能更好地获取局部特征,进而验证了本文提出的结合注意力机制的多尺度扩展模型的有效性和可行性。
为了验证本文所提模型针对密集单元格识别的有效性,使用E‒Tab数据集进行消融实验,并与基于Mask R‒CNN的不同改进方法[22]进行对比分析。消融实验结果如表 2所示。
表 2
E-Tab数据集上消融实验结果
| 模型 | 精确率 | 召回率 | F1值 |
| Mask R-CNN | 0.424 3 | 0.460 5 | 0.441 3 |
| Mask R-CNN+PSE | 0.967 4 | 0.858 5 | 0.909 7 |
| EPNet | 0.973 9 | 0.918 1 | 0.945 2 |
由表 2可以看出:初始模型Mask R‒CNN的性能一般,精确率为0.424 3,F1值为0.441 3;加入渐进式尺度扩展模块后整体性能大大提升,在E‒Tab数据集上的精确率提升到0.967 4,F1值提升到0.909 7;加入高效注意力机制模块后形成的EPNet模型,精确率进一步提升至0.973 9,F1值提升至0.945 2。上述结果验证了本文提出的EPNet模型能够实现对表格特征的有效提取,得到更有用的通道信息,提升了对密集单元格识别的精确度。
对密集表格的单元格进行识别,表格原图如图 5所示。
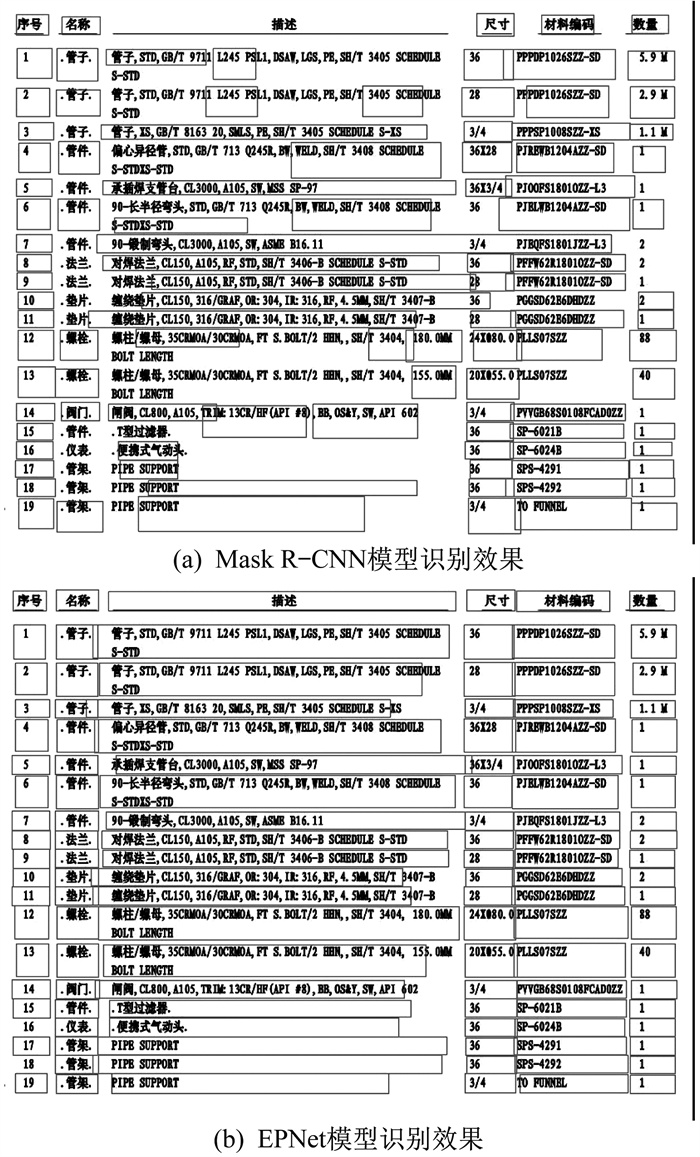
两种模型的识别效果如图 6所示。针对一些复杂微小的单元格,Mask R‒CNN模型在文本分割时会出现交叉和误检漏检,且单元格边缘拟合效果较差。由图 6可以看出:在加入渐进式尺度扩展模块后,Mask R‒CNN+PSE模型可以检测复杂微小的单元格结构模块,但边缘拟合效果不佳,仍存在空隙和边缘不平滑的问题;EPNet模型可以有效提升掩膜边缘的拟合程度,使分割效果得到提升,且能够准确分割出不同单元格及其边界,使边缘更加平滑。
4 结语
本文针对核电施工图纸材料表中密集单元格识别的问题提出了结合高效注意力机制的多尺度渐进式扩展模型EPNet。该方法在少样本条件下解决了密集单元格识别问题,并取得了令人满意的结果。EPNet模型对核电施工图纸材料表的识别具有良好的鲁棒性,降低了人工采集的风险,提升了资产信息采集的安全级别,为建立完善的贯穿整个生命周期的工程材料档案库提供了技术手段,能够有效地提升资产管理和运行管理的自动化水平。
本文模型复杂,训练时间长,内存消耗大,在低端设备上运行缓慢,并且在泛化性上还有待提高。因此,进一步降低模型复杂度,提升表格单元格检测性能是接下来研究的重点。
参考文献
-
[1]张静晓, 赵飞叶, 李慧, 等. 建筑企业数字化竞争力提升研究[J]. 建筑经济, 2023, 42(12): 93-98.
-
[2]PALIWAL S S, VISHWANATH D, RAHUL R, et al. TableNet: deep learning model for end-to-end table detection and tabular data extraction from scanned document images[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 128-133.
-
[3]TENSMEYER C, MORARIU V I, PRICE B, et al. Deep splitting and merging for table structure decomposition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 114-121.
-
[4]KHAN S A, KHALID S M D, SHAHZAD M A, et al. Table structure extraction with Bi-directional gated recurrent unit networks[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 1366-1371.
-
[5]SCHREIBER S, AGNE S, WOLF I, et al. DeepDeSRT: deep learning for detection and structure recognition of tables in document images[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Kyoto: IEEE, 2017: 1162-1167.
-
[6]LONG R J, WANG W, XUE N, et al. Parsing table structures in the wild[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 924-932.
-
[7]PRASAD D, GADPAL A, KAPADNI K, et al. CascadeTabNet: an approach for end to end table detection and structure recognition from image-based documents[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 2439-2447.
-
[8]QASIM S R, MAHMOOD H, SHAFAIT F. Rethinking table recognition using graph neural networks[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 142-147.
-
[9]LI Y R, HUANG Z, YAN J C, et al. GFTE: graph-based financial table extraction[C]//Pattern Recognition. ICPR International Workshops and Challenges. Cham: Springer, 2021: 644-658.
-
[10]孟月波, 石德旺, 刘光辉, 等. 多维度卷积融合的密集不规则文本检测[J]. 光学精密工程, 2021, 29(9): 2210-2221.
-
[11]SHAHAB A, SHAFAIT F, KIENINGER T, et al. An open approach towards the benchmarking of table structure recognition systems[C]//Proceedings of the 9th IAPR International Workshop on Document Analysis Systems. Boston: ACM, 2010: 113-120.
-
[12]JAUME G, EKENEL H K, THIRAN J P. FUNSD: a dataset for form understanding in noisy scanned documents[C]//2019 International Conference on Document Analysis and Recognition Workshops (ICDARW). Sydney: IEEE, 2019: 1-6.
-
[13]LI M H, CUI L, HUANG S H, et al. TableBank: table benchmark for image-based table detection and recognition[C]//Proceedings of the Twelfth Language Resources and Evaluation Conference. Marseille: European Language Resources Association, 2020: 1918-1925.
-
[14]GAO L C, HUANG Y L, DÉJEAN H, et al. ICDAR 2019 competition on table detection and recognition (cTDaR)[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 1510-1515.
-
[15]ZHONG X, SHAFIEIBAVANI E, JIMENO-YEPES A. Image-based table recognition: data, model, and evaluation[C]//16th European Conference on Computer Vision. Glasgow: Springer, 2020: 564-580.
-
[16]GÖBEL M, HASSAN T, ORO E, et al. ICDAR 2013 table competition[C]//2013 12th International Conference on Document Analysis and Recognition. Washington: IEEE, 2013: 1449-1453.
-
[17]KOCI E, THIELE M, REHAK J, et al. DECO: a dataset of annotated spreadsheets for layout and table recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 1280-1285.
-
[18]LI Y, WU Z, ZHAO S, et al. PSENet: psoriasis severity evaluation network[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 800-807.
-
[19]SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inceptionv4, inception-ResNet and the impact of residual connections on learning[C]//Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. San Francisco: AAAI, 2017: 4278-4284.
-
[20]WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11531-11539.
-
[21]CHI Z W, HUANG H Y, XU H D, et al. Complicated table structure recognition[DB/OL]. (2019-08-28)[2023-07-10]. https://arxiv.org/abs/1908.04729.
-
[22]XUE W Y, LI Q Y, TAO D C. ReS2TIM: reconstruct syntactic structures from table images[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). Sydney: IEEE, 2019: 749-755.


