|
|
|
发布时间: 2024-08-28 |
其他研究 |
|
|
|


|
收稿日期: 2024-03-26
中图法分类号: TP393
文献标识码: A
文章编号: 2096-8299(2024)04-0377-06
|
摘要
针对并列门控循环神经网络(GRU)算法在处理序列信息时无法直接交流和共享信息,导致模块之间信息流动受限,从而影响准确率的问题,提出了一种基于融合注意力机制的并列GRU应用层协议识别方法。该方法利用注意力机制获得并列GRU算法中不同时间点输出之间的重要关系,使得模型能更好地捕获序列数据的特征信息,从而提高算法的准确率。在UNSW-NB15数据集上进行实验,结果表明:与并列GRU算法相比,所提算法的识别准确率提升了9.3%,且与其他代表性算法相比,准确率均有所提高。
关键词
门控循环神经网络; 注意力机制; 协议识别
Abstract
In order to solve the problem that the parallel GRU(gated recurrent unit)algorithm cannot directly communicate and share information in the processing sequence information, resulting in the limited information flow between modules, thus affecting the accuracy, a parallel GRU application layer protocol recognition method based on fusion attention mechanism was proposed. In this method, the attention mechanism is fused on the basis of parallel GRU, and the important relationship between the output of different time points in the parallel GRU algorithm is obtained by using the attention mechanism, so that the model can better capture the important relationship between the feature information of the sequence data and the time points, so as to improve the accuracy of the algorithm. The experimental results show that the accuracy of the proposed method is improved by 9.3% compared with the parallel GRU algorithm, and the accuracy is improved compared with common algorithms.
Key words
gated recurrent unit; attention mechanism; protocol identification
近年来,随着物联网和通信技术的不断进步与发展,物联网相关的网络设备类别不断增多,网络流量激增,应用层协议种类的增长也变得异常迅猛[1]。应用层协议是一种计算机网络协议,用于规定不同网络应用之间如何有效交换数据,主要通过处理序列化数据,即以特定顺序组织和传输的数据,确保信息能够被准确地发送和接收,并按预定格式和顺序解析[2]。这些协议包括但不限于HTTP、DNS、FTP、SMTP、SNMP、SSH等。在物联网环境中,各种不同类型设备的数据上传到云端时,使用不同的应用层协议进行通信,为了正确处理这些数据,就需要按照应用层协议对其进行分类和识别。
目前,应用层协议识别方法的研究重点主要是如何确定协议数据的特征子集。针对应用层协议数据特征子集信息冗余的问题,文献[3]首先对特征向量进行聚类,选取聚类中心作为每一类的代表,然后根据特征的信息增益和增益率对所有聚类中心进行排序,以进一步简化特征的数量,最后按照排序选择最优特征子集,虽然该方法能有效剔除冗余特征,但是识别准确率并不理想。文献[4]借鉴了卷积神经网络在图像识别领域的成功应用经验,将网络流量特征转化为像素点,并进一步生成代表这些特征的“图像”,这些“图像”随后被用作卷积神经网络模型的输入,该方法在二分类及多分类任务中的识别准确率较高。文献[5-6]提出了一种将卷积神经网络与长短时记忆相结合的深度学习结构,其原理是从网络流量数据中提取关键特征,并将这些数据按组分配,把连续的N条流量记录转化为二维数据结构,利用卷积神经网络分析数据的空间特性,同时采用长短时记忆网络,从序列化的网络数据包中提炼出时间序列特征。
现有方法基本都存在参数选择困难、内部机制复杂、容易过拟合等问题,影响应用层协议识别效果。门控循环神经网络(Gated Recurrent Unit,GRU)[7]参数对应用层协议的序列数据建模能力强,且有更好的泛化能力。文献[8]提出了基于并列GRU分类模型的算法,借助多个输入序列之间的相关性,使得模型更适用于处理多源信息任务[9],提高了模型的性能,但每个模块只能看到自身处理的序列的部分信息,无法直接交流和共享信息,导致模块之间的信息流动受限[10],从而影响准确率。因此,本文将注意力机制引入并列GRU算法中,利用注意力机制自动定位序列中各个时间点的关键部分[11],以识别并列GRU算法的输出在不同时间点的关键联系,不仅有助于模型更有效地捕获数据特征与时间点之间的重要关联,还能提升算法的整体准确性。
1 应用层协议识别模型构建
1.1 GRU基本结构
GRU作为循环神经网络的一种变体,具有优秀的学习能力,能够快速有效地从大量数据中学习并提取特征。GRU是用于处理序列数据的深度学习模型,其内部具有更新门和重置门机制[9],可以更好地获得序列数据之间的长期依赖关系,同时解决了传统循环神经网络中的梯度消失和爆炸问题。相比于长短时记忆神经网络,GRU模型更简单、训练速度更快,在语言建模、机器翻译等序列建模任务中取得了良好的性能。其基本结构如图 1所示。其中,rt为重置门,zt为更新门,xt为当前时刻的输入,kt为当前时刻的输出,kt-1为上一时刻的输出,k't为候选隐藏状态,σ为激活函数。
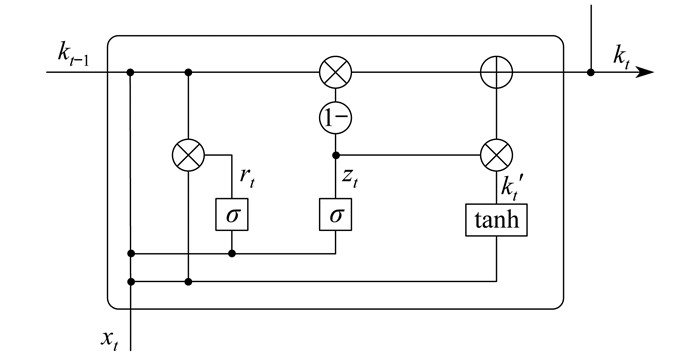

各个门控单元和传递状态的计算公式为
| $ r_t=\sigma \boldsymbol{W}_{\mathrm{r}}\left[k_{t-1}, x_t\right] $ | (1) |
| $ z_t=\sigma \boldsymbol{W}_{\mathrm{z}}\left[k_{t-1}, x_t\right] $ | (2) |
| $ \tilde{k}_t=\tanh \boldsymbol{W}\left[r_t k_{t-1}, x_t\right] $ | (3) |
| $ k_t=\left(1-z_t\right) k_{t-1}+z_t \tilde{k}_t $ | (4) |
式中:Wr,Wz——重置门和更新门的权重矩阵;
W——隐藏状态的权重矩阵。
1.2 并列GRU算法
并列GRU算法是一种用于处理时序数据的神经网络结构,可以同时使用多个独立的GRU层处理输入数据,从而更好地捕捉数据的多方面信息。该算法通常由多个GRU单元组成,每个单元都有各自的输入、输出和记忆单元。这些单元可以并列运行,每个单元的输出汇聚到下一层或输出层。这种结构有助于提高模型的并行性,从而加速训练和推理过程。但并列GRU在处理应用层协议的序列信息时无法直接交流和共享信息,导致模块之间的信息流动受限。
1.3 注意力机制
注意力机制是深度学习中的一项关键技术,通过仿照人类专注于关键信息的能力,使模型在处理大量数据时识别并聚焦于最关键的部分。通过为输入数据的不同部分分配权重,突出对当前任务最为重要的信息,从而提高模型的准确性和效率。注意力机制结构如图 2所示。其中,ht表示t时刻的状态向量,et表示ht的相似度权重,αt表示ht归一化后的结果,i表示状态向量的数量,R表示加权求和得到的注意力输出。
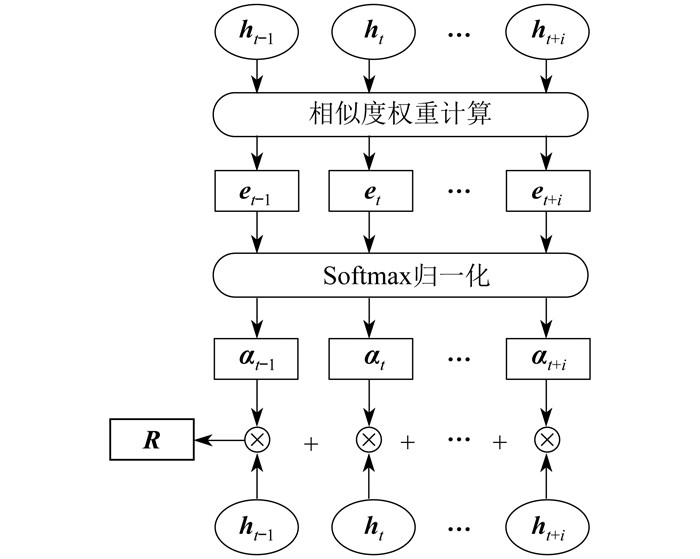
在处理应用层协议时,注意力机制可以分析时序数据在不同时间节点之间的相互作用,以及时序特征在各个子空间中的关联,从而提高模型的精度。
1.4 融合注意力机制的并列GRU模型
针对并列GRU在处理应用层协议时信息流动受限问题,本文提出了一种融合注意力机制的并列GRU模型。通过在并列GRU的基础上引入注意力机制,协助模型更好地捕捉应用层协议的序列特征,从而提高模型的准确度和性能。该模型由5个部分组成,分别为输入、并列GRU模块、注意力机制模块、特征融合模块以及分类结果模块。模型整体结构如图 3所示。
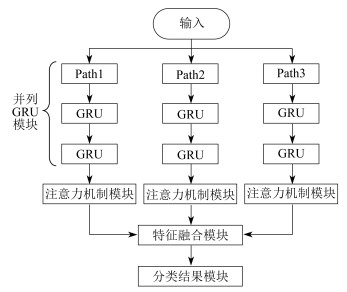
首先,通过并列GRU模块对应用层协议数据进行时序特征提取,得到对应的隐藏状态记为{ ht-1,ht,…,ht+i},这些隐藏状态对应时间步的输入,能够动态地表示输入序列中的内容。然后,将隐藏状态作为注意力机制的输入,注意力机制基于内容的重要性对隐藏状态进行加权求和。最后,生成注意力输出。
注意力机制中加权求和的计算过程具体步骤如下。
步骤1 将多个输入转化成文本嵌入矩阵X = { x1,x2,x3,…,xn}。
步骤2 利用嵌入矩阵乘以3个权重矩阵
| $ \left\{\begin{array}{l} \boldsymbol{q}=\text { Linear }(\boldsymbol{X})=\boldsymbol{X} \boldsymbol{W}_{\mathrm{Q}} \\ \boldsymbol{k}=\text { Linear }(\boldsymbol{X})=\boldsymbol{X} \boldsymbol{W}_{\mathrm{K}} \\ \boldsymbol{v}=\text { Linear }(\boldsymbol{X})=\boldsymbol{X} \boldsymbol{W}_{\mathrm{V}} \end{array}\right. $ | (5) |
式中:Linear——线性映射函数。
步骤3 计算每个输入向量的注意力得分,并根据得分确定权重分布。计算公式为
| $ s_i=\boldsymbol{q}_i \boldsymbol{k}_i^{\mathrm{T}} $ | (6) |
式中:si——第i个向量的注意力分数;
qi——第i个向量的查询向量;
ki——第i个向量的键向量。
步骤4 为保证梯度稳定性,将si归一化处理。计算公式为
| $ \tilde{s}_i=\frac{\boldsymbol{q}_i \boldsymbol{k}_i^{\mathrm{T}}}{\sqrt{d_{\mathrm{k}}}} $ | (7) |
式中:
dk——向量纬度。
步骤5 利用Softmax函数激活
| $ \operatorname{soft} \max \left(\tilde{s}_i\right) \frac{\mathrm{e}^{\tilde{s}_i}}{\sum\limits_{i=1}^C \mathrm{e}^{\tilde{s}_i}} $ | (8) |
式中:C——
将
| $ z_i=\frac{\sum\limits_{i=1}^C \mathrm{e}^{\tilde{s}_i} \boldsymbol{v}_i}{\sum\limits_{i=1}^C \mathrm{e}^{\tilde{s}_i}} $ | (9) |
式中:vi,zi——第i个输入向量的值向量和注意力计算结果。
在特征融合模块,将各个通道的权重与相应的注意力机制输出特征相结合,得到有权重信息的输出特征,并将有权重信息的多通道特征整合为一维向量,最终输出模型的分类结果。
1.5 算法实现过程
该算法的实现过程主要包括以下步骤。
步骤1 输入需要识别的数据。
步骤2 数据归一化处理。为了加速训练损失函数的收敛,调整训练集和测试集数据,使其分布的均值为0,方差为1。处理方法可表示为
| $ X_{\text {train }}=\frac{x_{\text {train }}-\mu_{\text {train }}}{\delta_{\text {train }}} $ | (10) |
| $ X_{\text {test }}=\frac{x_{\text {test }}-\mu_{\text {train }}}{\delta_{\text {train }}} $ | (11) |
式中:Xtrain——调整后的训练集;
xtrain——训练集数据;
μtrain——训练集数据的均值;
δtrain——训练集的方差;
Xtest——调整后的测试集;
xtest——测试集数据。
步骤3 通过融合注意力机制的并列GRU模型对训练集进行训练。
步骤4 计算损失函数,得到模型输出结果与真实结果之间的误差。
步骤5 每次训练周期结束后,评估模型是否已达到收敛状态。如果模型收敛,则完成模型训练;否则,重新执行相应训练步骤直至模型收敛。
步骤6 利用训练好的参数对测试集进行测试,得到最终结果。
2 实验验证和结果分析
2.1 实验环境和数据
本文实验环境部署在Windows 11操作系统中,CPU为Intel core i5-11260H处理器,GPU为NVIDIA RTX3050,专用GPU内存为4 GB。环境基于Python3.9软件进行搭建,深度学习框架采用Pytorch,版本为1.12.1。
应用层协议识别中常用的数据集是KDD CUP99数据集[12],但随着网络服务高速发展,网络架构更加复杂,该数据集的使用效果无法满足需求。为此,澳大利亚安全中心新建了UNSWNB15数据集[13],该数据集反映了现代网络流量模式[11],包含257 673个数据实例。相较于KDD CUP99数据集,UNSW-NB15数据集在数据更新、规模,以及多样性和特征丰富性等方面更加优越。
数据集分为训练集(82 332条)和测试集(175 341条),每条数据有49个维度的特征,这些特征描述了网络流量的各个方面。每条数据的维度特征如表 1所示。
表 1
数据维度特征
| 类别编号 | 所属维度/维 | 特征 |
| 1 | 1~5 | 流特征 |
| 2 | 6~18 | 基本特征 |
| 3 | 19~26 | 内容特征 |
| 4 | 27~36 | 时间特征 |
| 5 | 37~47 | 额外生成特征 |
| 6 | 48~49 | 标签特征 |
2.2 评价指标
实验结果的评价指标主要包括准确率A、精确率P、召回率R和F1值,公式为
| $ \left\{\begin{array}{l} A=\frac{T_{\mathrm{p}}+T_{\mathrm{N}}}{T_{\mathrm{p}}+F_{\mathrm{p}}+F_{\mathrm{N}}+T_{\mathrm{N}}} \times 100 \% \\ P=\frac{T_{\mathrm{p}}}{T_{\mathrm{p}}+F_{\mathrm{p}}} \times 100 \% \\ R=\frac{T_{\mathrm{p}}}{T_{\mathrm{p}}+F_{\mathrm{N}}} \times 100 \% \\ F_1=\frac{2 P R}{P+R} \times 100 \% \end{array}\right. $ | (12) |
式中:Tp——正确分类为X类别的实例数;
TN——正确分类为Not-X类别的实例数;
Fp——错误分类为X类别的实例数;
FN——错误分类为Not-X类别的实例数。
准确率表示正确预测的样本数与总样本数的比例;精确率用于量化模型对整体数据集识别能力的高低,反映了模型的总体识别效率;召回率表示所有正确实例中被模型识别出的比例;F1值通过加权平均调和精确率和召回率,为评估模型在单一类别识别性能上提供了一个综合指标。通过上述指标的综合分析,可以全面评价所提方法在应用层协议识别任务上的效果,确保评估的全面性与准确性。
2.3 实验结果
为了评估本文提出的基于融合注意力机制的并列GRU应用层协议识别方法的准确率,将其与并列GRU算法进行比较。为确保实验的准确率,对数据集进行200次epoch,1个epoch意味着算法用整个数据集完成1次正向传递和反向传递。两种算法的准确率比较如图 4所示。
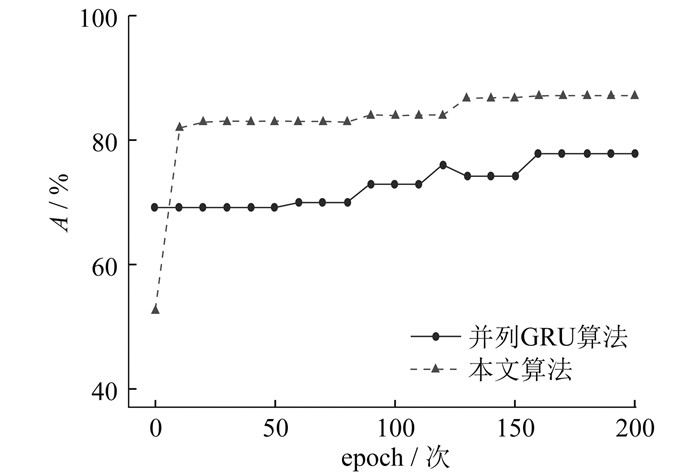
由图 4可以看出,开始时并列GRU算法的总体准确率要高于本文算法,但随着迭代次数的增加,本文算法的准确率超过了并列GRU算法。两种算法的评价指标结果如表 2所示。
表 2
两种算法的评价指标结果
| 算法 | 准确率 | 精确率 | 召回率 | F1 |
| 并列GRU | 75.3 | 77.8 | 77.8 | 86.4 |
| 本文 | 86.1 | 87.1 | 87.1 | 92.0 |
由表 2可以看出,本文算法的精确率最高可达87.1%,相较于并列GRU算法,精确率提高了9.3%。同时,准确率、召回率和F1值均有明显的提高。本文提出的基于融合注意力机制的并列GRU算法要明显优于并列GRU算法。
再将本文算法与决策树(Decision Tree,DT)算法、哈密顿蒙特卡罗(Hamiltonian Monte Carlo,HMC)算法、基于朴素贝叶斯的因子分析(NaiveBayes-based Factor Analysis,NB+FA)算法、长短时记忆网络(Long Short-Term Memory,LSTM)算法、基于随机森林的独立成分分析(Random Forest-based Independent Component Analysis,RF+ICA)算法以及基于随机森林的主成分分析算法(Principal Component Analysis algorithm based on Random Forest,RF+PCA)等代表性算法进行比较。不同算法的准确率比较如 图 5所示。
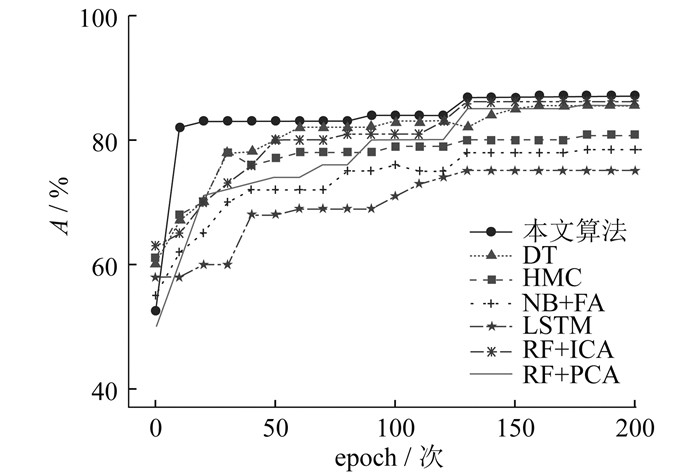
由图 5可以看出,本文算法的准确率依然最高,且在训练过程中能够较早地达到较高的准确率。不同算法的评价指标结果如表 3所示。
表 3
不同算法的评价指标结果
| 算法 | 准确率 | 精确率 | 召回率 | F1 |
| DT | 83.3 | 85.56 | 83.0 | 90.1 |
| HMC | 78.8 | 80.78 | 79.1 | 85.4 |
| NB+FA | 76.2 | 78.2 | 75.3 | 82.5 |
| LSTM | 74.3 | 75.1 | 73.2 | 80.1 |
| RF+ICA | 85.6 | 86.1 | 85.1 | 89.7 |
| RF+PCA | 84.2 | 85.5 | 83.2 | 87.7 |
| 本文 | 86.1 | 87.1 | 87.1 | 92.0 |
通过表 3可以得到:相较于目前的常见算法,基于融合注意力机制的并列GRU算法具有更高的准确率、精确率、召回率和F1值。
3 结语
目前物联网应用层协议种类繁多,常见的分类算法精确率不够高。本文基于并列GRU算法,提出了一种融合注意力机制的并列GRU应用层协议识别方法,通过注意力机制得到每个GRU层的注意力权重,提取应用层协议的关键特征,从而提高识别性能。实验结果表明:本文所提算法相较于并列GRU算法精确率提高了9.3%,同时准确率、召回率、F1值均有所提升;与DT、HMC、NB+FA、LSTM、RF+ICA、RF+PCA等代表性算法进行比较,本文所提算法的性能更好,再次验证了本文算法的有效性。
参考文献
-
[1]王丽娜, 赖坤豪, 杨康. CARINA: 一种高效的解决IoT互操作性的应用层协议转换方案[J]. 计算机科学, 2024, 51(2): 278-285.
-
[2]李麒鑫, 田秀霞. 基于深度特征合成和关联规则的数据库异常访问检测[J]. 上海电力大学学报, 2022, 38(2): 203-207.
-
[3]MAO J W, HU Y Q, JIANG D, et al. CBFS: a clusteringbased feature selection mechanism for network anomaly detection[J]. IEEE Access, 2020, 8: 116216-116225. DOI:10.1109/ACCESS.2020.3004699
-
[4]王伟. 基于深度学习的网络流量分类及异常检测方法研究[D]. 合肥: 中国科学技术大学, 2018.
-
[5]PEKTAŞ A, ACARMAN T. A deep learning method to detect network intrusion through flow-based features[J]. International Journal of Network Management, 2019, 29(3): e2050. DOI:10.1002/nem.2050
-
[6]YANG S D, YU X Y, ZHOU Y. LSTM and GRU neural network performance comparison study: taking yelp review dataset as an example[C]//International Workshop on Electronic Communication and Artificial Intelligence. Shanghai: IEEE, 2020: 98-101.
-
[7]杨丽, 吴雨茜, 王俊丽, 等. 循环神经网络研究综述[J]. 计算机应用, 2018, 38(增刊2): 1-6.
-
[8]周建国, 戴华, 杨庚, 等. 基于并列GRU分类模型的日志异常检测方法[J]. 南京理工大学学报, 2022, 46(2): 198-204.
-
[9]梁锦, 覃树宏, 马可靠. 多源网络信息跨空间融合风险预测仿真[J]. 计算机仿真, 2023, 40(11): 361-364.
-
[10]王雪健, 赵国磊, 常朝稳, 等. 信息流格模型的非法流分析[J]. 计算机科学, 2019, 46(2): 139-144.
-
[11]李海豹, 张帅, 赵江滨. 高端装备单元化制造系统时间序列重要度分析[J]. 西北工业大学学报, 2023, 41(5): 969-977.
-
[12]余华鸿, 周凤艳, 陈毛毛. 基于机器学习的KDD-CUP99网络入侵检测数据集的分析[J]. 计算机工程与科学, 2019, 41(增刊1): 91-97.
-
[13]高忠石, 苏旸, 柳玉东. 基于PCA-LSTM的入侵检测研究[J]. 计算机科学, 2019, 46(增刊2): 473-476.


