|
|
|
发布时间: 2019-12-10 |
|
|
|
|


|
收稿日期: 2019-01-11
中图法分类号: TM9;TM6
文献标识码: A
文章编号: 1006-4729(2019)06-0562-05
|
摘要
风力发电场发电功率的超短期预测越精确, 越有利于电力系统的稳定运行和优化调度。为提高风电场发电功率超短期预测的准确率, 提出了一种基于主成分分析(PCA)和轻量梯度提升树(LightGBM)的风电场发电功率超短期预测方法。该方法首先进行主成分分析, 将与风电功率相关程度低的维度剔除, 降低数据的冗余性。然后利用LightGBM建模, 实现风电场发电功率的超短期预测。实验结果表明, 基于LightGBM的风电场发电功率超短期预测效果良好, 优于传统机器学习方法在风电场超短期功率预测上的精度。
关键词
LightGBM; 风电功率预测; 特征筛选; 主成分分析
Abstract
The more accurate in the ultra-short-term prediction of wind farm power generation, the more favorable on the stable operation and optimal dispatch of the power system.In order to improve the accuracy of ultra-short-term prediction of wind farm power generation, an ultra-short-term prediction method for wind farm power generation based on principal component analysis and gradient boosting macheine(GBM) algorithm is proposed.The method first performs PCA to eliminate the low dimension with correlation on wind power, and reduces data redundancy.Then GBM algorithm is used to model the ultra-short-term prediction of wind farm power generation.The experimental results show that the wind power generation power based on GBM algorithm has a good short-term prediction effect, which is better than the traditional machine learning method in the ultra-short-term power prediction of wind farms.
Key words
LightGBM; wind power prediction; feature screening; principal component analysis
可再生能源风能发电并网的发展, 给电力系统的安全稳定运行带来了严峻的挑战。风力发电场发电功率的预测越精确, 越有利于电力系统的稳定运行及优化调度。风电功率预测分为短期预测和超短期预测, 其中超短期预测是对风电场未来数小时内的出力进行预测, 时间分辨率不小于15 min, 并且每15 min自动执行一次, 主要用于单日内的计划滚动。超短期预测能够动态调节短期的预测误差而引起的功率波动, 有助于缓解系统调峰、调频压力, 对电网安全运行有着重要的影响[1]。
随着风电场监测数据精度的增加, 风电场发电功率的超短期预测愈加火热。现有关于风电场发电功率超短期预测的方法大致可分为物理方法和统计方法两类。物理方法主要是依据风电场周边的地貌信息, 建立合理的热力学及流体力学模型, 通过求解非线性方程组得到风速风向等信息, 再根据风机功率曲线得到输出功率来实现预测。这类方法本质上是描述大气运动, 不依托历史数据, 适合在建的风电场功率预测。由于物理方法不太容易对特殊的地理环境以及自然现象精确描述, 且对模型和参数选择的依赖性强, 所以没有广泛用于风电场的超短期功率预测[2]。统计方法主要是依据风电场历史数据的统计规律, 建立历史样本之间的非映射关系, 其中最常见的方法就是人工神经网络、支持向量机等人工智能预测方法[3], 比较适合风电功率的超短期预测。因此, 为提高风电场发电功率超短期预测的准确率, 本文提出一种基于主成分分析(Principal Component Analysis, PCA)和轻量梯度提升树(Light Gradient Boosting Maching, LightGBM)的风电场发电功率超短期预测方法。
1 基于LightGBM的风电场发电功率超短期预测模型
图 1是基于LightGBM的风电场发电功率超短期预测建模流程图。由图 1可以看出, 要想实现风电场发电功率的超短期预测, 首先要做风机数据采集与监视控制系统(Supervisory Control And Data Acquisition, SCADA)数据的特征工程, 将对风机中的SCADA检测系统数据提取后进行数据清洗, 将故障时间内的数据剔除, 清洗后将数据标准化到固定区间以保证结果的可靠性。由于工业数据维度较高, 故采用PCA实现降维, 将数据集精简到最适合模型训练的状态。随后将降维度后的数据进行分组, 分为训练样本和测试样本。训练样本代入LightGBM模型中训练, 并采用网格搜索的方法进行调参, 直到整个模型训练到最佳, 最终将测试样本代入到训练好的超短期预测模型中实现功率预测。
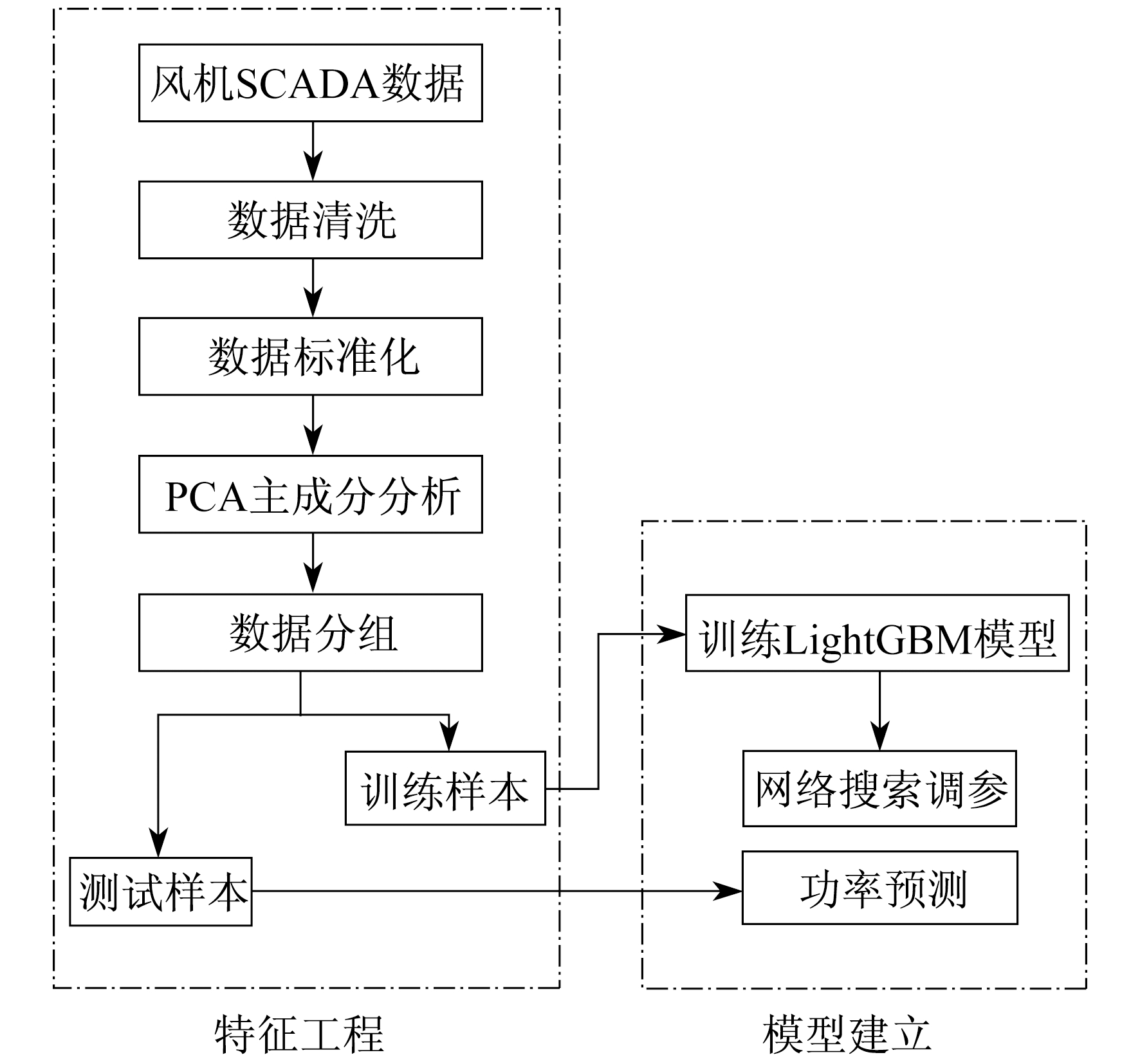

2 PCA简介
风电机组SCADA系统的监控数据是每隔7.5 s记录一次的风机重要部件传感器的监测参数, 包括发电机转速、网侧有功功率、机舱温度等28个维度。由于工业数据维度较高, 且影响功率的因素主要集中在温度、风向、风力等上, 所以常采用PCA实现降维, 一方面在一定程度上去噪, 另一方面将数据精简到最适合模型学习的状态[4]。
PCA是比较常用的一种降维方法。作为一种统计方法, 该方法通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量, 转换后的这组变量称为主成分。PCA的原理是线性映射, 即将高维空间数据投影到低维空间上; 在数据分析上, 将数据的主成分(包含信息量大的维度)保留下来, 将数据描述不重要的成分予以忽略。即将主成分维度组成的向量空间作为低维空间, 将高维数据投影到该空间而实现降维。算法的主要思想是选取数据差异最大的方向作为第一个主成分, 第二个主成分选择方差次大的方向, 并且与第一个主成分正交, 不断重复这个过程直到找到n个主成分。在风机SCADA监测数据26个维度的基础上, 经过清洗, 将工况参数等维度剔除后再进行主成分分析, 将数据降维至K维。
3 基于LightGBM的风电场发电功率超短期预测
GBM的全称是Gradient Boosting Machine, 一般叫做梯度提升树, 属于Boosting算法的一种[5]。Boosting算法是一类将弱学习器提升为强学习器的集成学习算法, 主要是通过改变训练样本的权值, 学习多个分类器, 并将这些分类器进行线性组合, 提高泛化性能。如果一个分类存在一个多项式能够学习且有较高的准确率, 那么这个算法就叫做强学习器; 反之, 若准确率只稍稍大于50%, 那么这个算法就叫做弱学习器。Boosting就是从更容易得到的弱学习器出发, 经反复训练得到一系列弱学习器, 再组合这些弱学习器, 从而构成一个强学习器。大多数Boosting算法会改变数据的概率分布(数据权值), 即通过提高前一轮训练中被错分类的数据的权值, 降低正确分类数据的权值, 使得被错误分类的数据在下一轮的训练中更受关注, 再将这些学习器线性组合。具体方法是增大误差率小的学习器的权值, 减小误差率大的学习器的权值。Boosting算法可以看作一个加法模型, 其公式为
| $ f(x)=\sum\limits_{m=1}^{M} \alpha_{m} T\left(x, \theta_{m}\right) $ | (1) |
式中:αm——基学习器权系数;
M——学习器的个数;
m——第m个学习器;
θm——学习器分类的参数, 即分类树或者回归树模型参数;
T(x, θm)——学习得到的第m个基学习器。
在给定训练数据和损失函数形式后, Boosting学习模型可以定义为一个损失函数极小化的问题, 优化的目标函数为
| $ \arg \min \sum\limits_{i=1}^{N} L\left(y_{i}, f\left(x_{i}\right)\right) $ | (2) |
式中:N——样本个数;
L——损失函数;
yi——实际函数值。
GBM为基于梯度下降算法得到的提升树模型, 具体步骤如下:
(1) 输入训练数据(xi, yi);
(2) 构建提升树模型fm(x);
(3) 初始化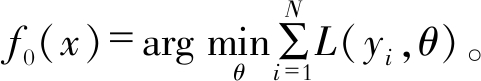
从m=1到M的迭代中:
(1) 计算损失函数的负梯度在当前模型的值, 将它作为残差的估计, 即
| $r_{i m}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{m-1}(x)} \\ i=1,2,3, \cdots, N$ | (3) |
(2) 估计回归树叶节点区域, 以拟合残差的近似值;
(3) 利用线性搜索估计叶节点区域的值, 使损失函数极小化[6], 即
| $ \gamma_{j m}=\arg \min\limits _{\gamma} \sum\limits_{x_{i} \in R_{j m}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\gamma\right) $ | (4) |
(4) 更新回归树[6], 即
| $ f_{m}(x)=f_{m-1}(x)+\sum\limits_{j=1}^{J_{m}} \gamma_{j m} I\left(x \in R_{j m}\right) $ | (5) |
由此得到最终的模型f(x)。
基于梯度下降算法去更新残差方式, 随着迭代次数的增加, 使之可以拟合比较复杂的非线性关系。在这种情况下, 通过训练好的GBM模型去实现超短期功率预测的准确率也愈来愈高。通过GBM算法的演变, XGBoost算法应运而生。不同于GBM的是, XGBoost算法对于模型的目标函数的处理方式为:XGBoost将目标函数作二阶泰勒展开, 从中得出下一次迭代需要预测的目标叶节点权重, 并根据损失函数计算分裂后的节点损失, 最后依据节点损失筛选适当的特征进行下一步迭代。作为针对XGBoost的一些缺点而改进和演变的LightGBM是速度快、性能高的梯度提升算法。其具体的优化如下:在数据结构方面, LightGBM采取了histogram算法, 这类算法相较于XGBoost的Pre-sorted算法更有优势; 由于histogram算法对稀疏数据的处理时间及复杂度没有pre-sorted好, 因此LightGBM采用特征捆绑(Exclusive Feature Bunding, EFB)的方式来处理稀疏数据。LightGBM则利用了基于梯度的单边采样(Gradient-based One-Side Sampling, GOSS)作为采样算法。
EFB和GOSS这两个创新点正是LightGBM的可贵之处。EFB降低了数据特征规模, 提高了模型的训练速度。GOSS巧妙地在保证信息增益的同时减小训练量, 提高了模型的泛化能力。从实验的效果来看, LightGBM在速度和精度上都要优于XGBoost。
4 实验验证部分
4.1 实验数据集描述
本文采用的数据集来自国内某风电机组15#单机正常运行状态下SCADA的部分数据。15#单机数据采集的时间为2015年11月1日20:20至2016年1月1日21:38, 采样频率为7.5 s/次, 共计373 196×29组数据。在对比实验中引入21#单机正常运行状态下的数据, 采集时间相同, 采样频率为7.5 s/次, 共计179 646×29组数据。其中有28个连续数值型变量, 涵盖风点机组的工况参数、环境参数和状态参数等多个维度。由于实验验证与功率预测相关, 其中的工况参数以及部分状态参数对功率的预测影响不大, 所以人工剔除其中的维度, 保留表 1中的维度。
表 1
风电机组SCADA数据集维度说明
| 字段名 | 说明 |
| time | 时间唯 |
| wind_speed | 风速 |
| generator_speed | 发电机转速 |
| pitch1_ng5_tmp | 变除樞电源1温度 |
| pitch2_ng5_tmp | 变奖樞电源2温度 |
| pitch3_ng5_tmp | 变奖樞电源3温度 |
| power | 网侧有功功率 |
| environment_tmp | 环境温度 |
| int_tmp | 机舱温度 |
| pitch1_moto_tmp | 变闲电机1温度 |
| pitch2_moto_tmp | 变奖电机2温度 |
| pitch3_moto_tmp | 变奖电机3温度 |
4.2 主成分分析
处理后数据集的维度定格在12维。由于15#单机的数量达到30多万条, 所以整个数据集的量算较多, 故采取PCA降维方式将原始数据维度降到K维, 在保证模型训练效果不变的情况下提升预测速度, 达到超短期功率预测的目的。“time”时间戳维度属于非连续的数值型变量, 在输入模型训练的过程中会大大增加模型的复杂度, 所以在训练模型中依照索引的方式描述时间序列。从序列1到序列2刚好一个采样频率7.5 s。K值的选取问题属于一个数据压缩的问题, 即在保留95%~99%信息的基础上的K值, 在调用sklearn封装的PCA方法时, 其中的n_components参数, 如果设置为整数, 则n_components=k。如果将其设置为小数, 则说明降维后的数据可以保留信息。在具体的实验中, 将n_components参数设置为float数据, 从而间接解决K值选取的问题。
4.3 数据集的划分及LigntGBM模型的训练
在经过数据人工降维及PCA降维后, 数据集已经具有一定的完整性。随后将处理后的15#机组数据集按照90%训练集以及10%测试集划分。在LightGBM模型训练的输入和输出上, 将处理后的90%训练集作为模型的输入来训练模型, 模型训练的输出目标是标签“power”字段, 即网侧有功功率。LightGBM模型训练完成后, 以同样方式处理10%测试集, 并代入训练好的模型, 得到预测的“predict”结果, 再根据原始的正确“power”数值与预测的“predict”结果的误差去评估模型的效果。其具体的流程如图 2所示。
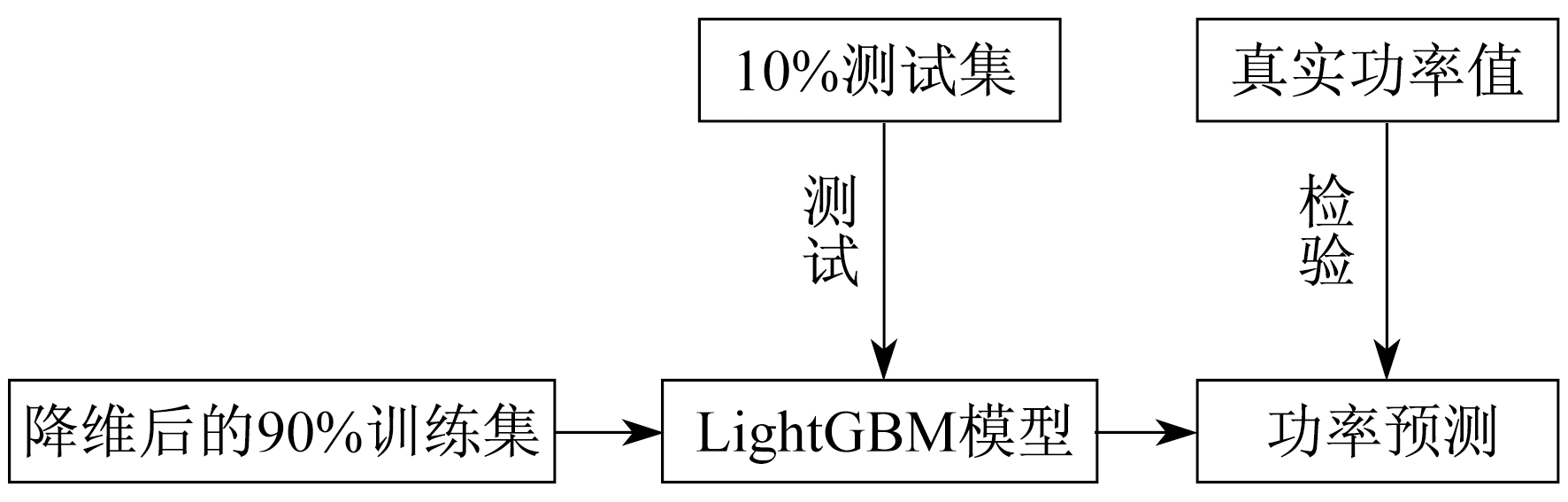
4.4 模型的误差分析
在将处理后的15#机组数据的90%训练集训练LightGBM模型完成后, 需要去检验模型训练的效果。将处理后的10%测试集同样作为可以输出理论的功率预测结果, 再将其与实际的功率真实值比较, 得出模型训练的优劣。回归模型采用均方误差(Mean Squared Error, MSE)、均方根误差(Root Mean Squared Error, RMSE)及平均绝对误差(Meqan Absolute Error, MAE)进行评价。MSE, RMSE, MAE的计算公式为
| $ M_{\mathrm{SE}}=\frac{1}{N} \sum\limits_{t=1}^{N}\left(o_{t}-p_{t}\right)^{2} $ | (6) |
| $ R_{\mathrm{MSE}}=\sqrt{\frac{1}{N} \sum\limits_{t=1}^{N}\left(o_{t}-p_{t}\right)^{2}} $ | (7) |
| $ M_{\mathrm{A E}}=\frac{1}{N} \sum\limits_{i=1}^{N} \mid\left(f_{i}-y_{t}\right) $ | (8) |
式中:ot——真实值;
pt——估计值;
fi——预测值;
yt——真实值。
4.5 实验结果验证
将15#机组原始数据经过人工降维并经PCA降维后, 将90%训练集和10%测试集代入LightGBM模型训练, 根据回归模型误差分析的评价标准, 得到的预测结果如表 2所示。
表 2
基于PCA和LightGBM的风电超短期功率预测
| 误差分析 | 数值大小 |
| MSE | $3.72298 \mathrm{e}-05$ |
| RMSE | 0.006102 |
| MAE | 0.004247 |
由表 2可知, 基于PCA和LightGBM的风电超短期功率预测训练效果优异。
分别采用传统的Logistic回归、随机森林算法和XGBoost算法作对比实验, 得到4种算法的实验效果如表 3所示。
表 3
15#机组4种算法不同数据集规模实验效果对比
| 数据集 | 评价指标 | Logistic回归 | 随机森林 | XGBoost | LightGBM |
| 100%数据集(373 196×29) | MSE | 0.078 451 | 0.003 072 | 4.126 54e-05 | 3.722 98e-05 |
| RMSE | 0.280 091 | 0.055 426 | 0.006 423 | 0.006 102 | |
| MAE | 0.198 537 | 0.023 454 | 0.004 842 | 0.004 247 | |
| TIME | 42.41 s | 33.46 s | 17.23 s | 12.96 s | |
| 50%数据集(186 598×29) | MSE | 0.083 174 | 0.003 217 | 4.398 42e-05 | 3.952 17e-05 |
| RMSE | 0.288 401 | 0.056 719 | 0.006 632 | 0.006 287 | |
| MAE | 0.201 354 | 0.031 224 | 0.004 921 | 0.004 362 | |
| TIME | 34.15 s | 29.15 s | 15.27 s | 11.23 s | |
| 10%数据集(37 320×29) | MSE | 0.083 532 | 0.003 421 | 4.913 51e-05 | 4.187 16e-05 |
| RMSE | 0.289 019 | 0.058 489 | 0.007 010 | 0.006 471 | |
| MAE | 0.215 426 | 0.034 285 | 0.005 321 | 0.004 631 | |
| TIME | 29.13 s | 24.53 s | 14.71 s | 10.91 s |
由表 3可以看出, LightGBM模型提升的训练效果显著, 在速度和误差上都有本质的提升, XGBoost模型的训练效果也比较理想, 但LightGBM在速度和误差上均有提升。LightGBM在数据集成倍增长的情况下, 实验耗时增长不多, 但精度确有提高。可见, LightGBM模型在数据集量大的情况下, 精度和速度的优势能展现出来。
5 结语
本文针对风电场规模不断扩大, 风机SCADA实时监测系统短周期采样数据的充分利用的问题, 提出了基于PCA降维以及LightGBM的风电功率超短期预测方法。通过4种不同算法及不同数据集规模的实验效果对比可以看出, 在数据集数量和维度都比较大的情况下, 采用LightGBM模型可以在保证精度的情况下, 实现风电功率的超短期预测。这对风电场的稳定运行及调度优化具有一定的现实意义。
参考文献
-
[1]基于人工神经网络的风电功率预测[J]. 中国电机工程学报, 2008, 28(34): 118-123. DOI:10.3321/j.issn:0258-8013.2008.34.019
-
[2]基于相似曲线簇和GBRT方法的超短期风电功率预测[J]. 华北电力大学学报(自然科学版), 2018(6): 19-24.
-
[3]基于风速云模型相似日的短期风电功率预测方法[J]. 电力系统自动化, 2018(6): 53-59. DOI:10.7500/AEPS20170605001
-
[4]主成分分析综合评价应该注意的问题[J]. 统计研究, 2013, 30(8): 25-31. DOI:10.3969/j.issn.1002-4565.2013.08.004
-
[5]基于迭代决策树(GBDT)短期负荷预测研究[J]. 贵州电力技术, 2017(2): 82-90.
-
[6]UNIVERSITY of WASHINGTON. Introduction to Boosted Trees[EB/OL]. (2014-10-22)[2018-04-05]. http:hornes.cs.washington.edu/-tqchen/data/pdf/BoostedTree.pdf.


